시작하며: 왜 이 글을 썼나?
최근에는 대규모 웹 크롤링에 대해 자세히 다룬 글이 거의 없었습니다. 마지막으로 참고할 만한 글은 2012년 Michael Nielsen의 포스트였죠. 그 사이에 CPU 코어 수 증가, SSD의 보급, 네트워크 대역폭의 폭발적 성장, 클라우드 인스턴스의 다양화 등 많은 것이 바뀌었습니다. 하지만 웹 자체도 더 동적이고 무거워졌죠.
저자는 "지금은 어떤 점이 달라졌을까? 병목은 어디로 옮겨갔을까? 10년 전처럼 4만 달러로 나만의 구글을 만들 수 있을까?"라는 궁금증에서 출발해, 비슷한 조건에서 직접 웹 크롤러를 만들어 24시간 만에 10억 개 페이지를 크롤링하는 실험을 진행했습니다.
문제 정의: 목표와 제약 조건
1. 24시간 내에 10억 페이지 크롤링
- 예비 실험 결과, 하루 만에 10억 페이지가 가능하다고 판단.
- 실제로 각 머신의 평균 가동 시간은 25.5시간(재시작 포함).
2. 몇 백 달러의 예산
- Nielsen의 크롤링은 약 580달러가 들었음.
- 저자는 462달러로 25.5시간 동안 크롤링을 마침.
- 여러 번의 소규모 실험과 대규모 실험도 진행.
3. HTML만 크롤링
- 자바스크립트는 실행하지 않음.
"옛날 방식"으로<a>태그의 링크만 수집. - "이 방식으로도 아직도 많은 웹을 크롤링할 수 있을까?"라는 호기심도 있었음.
4. 예의 지키기(Politeness)
- robots.txt 준수, 사용자 에이전트에 연락처 명시, 요청 시 도메인 제외, 상위 100만 도메인만 크롤링, 같은 도메인엔 70초 이상 간격 유지.
"운영자들에게 피해를 주지 않기 위해 반드시 예의를 지켜야 한다고 생각했습니다."
5. 장애 허용(Fault-tolerance)
- 중간에 중단/재개가 가능해야 했음.
- 완벽한 장애 허용은 아니지만, 일부 데이터 손실은 감수.
시스템 설계: 어떻게 만들었나?
전체 구조
일반적인 크롤러 설계(파싱, 페칭, 데이터 저장, 상태 관리 등 각 기능을 별도 머신에 분리)와 달리,
각 노드가 모든 기능을 갖춘 독립형 구조로 설계했습니다.
각 노드는 전체 도메인 중 일부만 담당(샤딩)하며, 다음과 같은 구성입니다.
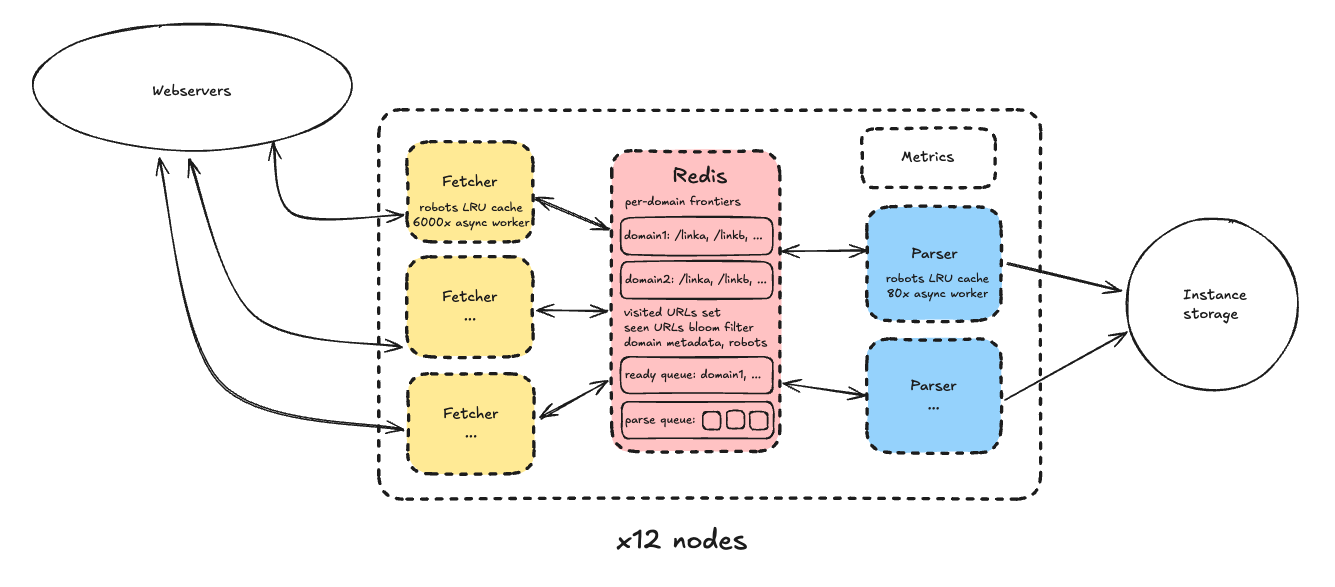
각 노드의 구성
- Redis 인스턴스: 크롤 상태 관리
- 도메인별 frontier(크롤 대기 URL 목록)
- 도메인 큐(다음 크롤 가능 시각 기준 정렬)
- 방문한 URL 및 메타데이터, 저장 경로
- Bloom filter: 이미 추가된 URL인지 빠르게 확인(속도 우선, 약간의 오차 허용)
- 도메인 메타데이터(robots.txt, 제외 여부 등)
- 파싱 대기 큐
- Fetcher 프로세스 풀
- Redis에서 다음 도메인/URL을 꺼내서 크롤, 결과를 파싱 큐에 넣음
- 각 프로세스는 asyncio로 수천 개의 동시 작업 처리(6000~7000개)
- LRU 캐시로 Redis 부하 최소화
- Parser 프로세스 풀
- 80개 async 워커로 HTML 파싱, 링크 추출, 저장
- 파싱은 CPU 집약적이라 fetcher보다 워커 수 적음
- 기타
- 저장소는 인스턴스 스토리지 사용(S3는 비용 문제로 제외)
- 저장 페이지는 250KB로 잘라 저장(실험 목적)
- 첫 fetcher가 리더 역할로 Prometheus에 메트릭 기록
최종 클러스터 스펙
- 12개 노드
- 각 노드는
i7i.4xlarge(16 vCPU, 128GB RAM, 10Gbps 네트워크, 3750GB 스토리지) - 각 노드: 1 Redis + 9 Fetcher + 6 Parser
"도메인 시드 리스트를 노드별로 샤딩해, 각 노드는 자신만의 인터넷 영역을 크롤링했습니다."
왜 12개 노드만 썼나?
- 도메인 샤딩을 너무 얇게 하면 인기 도메인 쏠림(Hot Shard) 현상 발생
- Redis가 120 ops/sec에 도달하면 성능 저하 우려, 15개 프로세스에서 멈춤
대안 설계 실험
- SQLite, PostgreSQL: 프론티어 쿼리 속도 문제로 부적합
- 단일 노드 수직 확장:
i7i.48xlarge(거대 인스턴스)에서 여러 "pod"로 구성해봤으나,
기대만큼 성능이 안 나와서 결국 수평 확장(여러 노드)로 전환
배운 점들: 크롤링의 실제 병목과 놀라운 변화들
1. 파싱이 최대 병목!
처음엔 fetcher 1개에 parser 2개가 필요할 정도로 파싱이 느렸음.
2012년보다 CPU도 좋아졌는데 왜 이럴까?
프로파일링 결과, 웹페이지 평균 크기가 2012년 51KB → 2025년 138~242KB로 대폭 증가한 것이 원인.
"파싱이 이렇게 큰 병목이 될 줄은 정말 몰랐습니다."
해결 방법
- lxml → selectolax로 교체(최신 C++ 기반 HTML5 파서, 최대 30배 빠름)
- 페이지 크기 250KB로 자르기(평균보다 높아 대부분의 페이지는 온전히 저장)
이렇게 해서 파서 1개당 초당 160페이지 파싱이 가능해졌고,
최종적으로 fetcher 9개, parser 6개로 초당 약 950페이지 크롤링 달성!
2. 페칭: 쉬워진 점과 어려워진 점
과거엔 네트워크 대역폭, DNS가 병목이었으나,
이번 실험에서는 CPU가 병목이었음.
- DNS: 상위 100만 도메인만 크롤링해서 병목 없음
- 네트워크: 노드당 25Gbps 중 8Gbps만 사용(32% 활용)
- SSL:
SSL 사용률이 2014년 30% → 2025년 80% 이상으로 폭증
SSL 핸드셰이크가 전체 CPU의 25% 차지, 네트워크보다 CPU가 먼저 포화됨
"SSL 핸드셰이크 연산이 가장 비싼 함수로, 전체 CPU의 25%를 차지했습니다."
3. 대규모 크롤 실전기
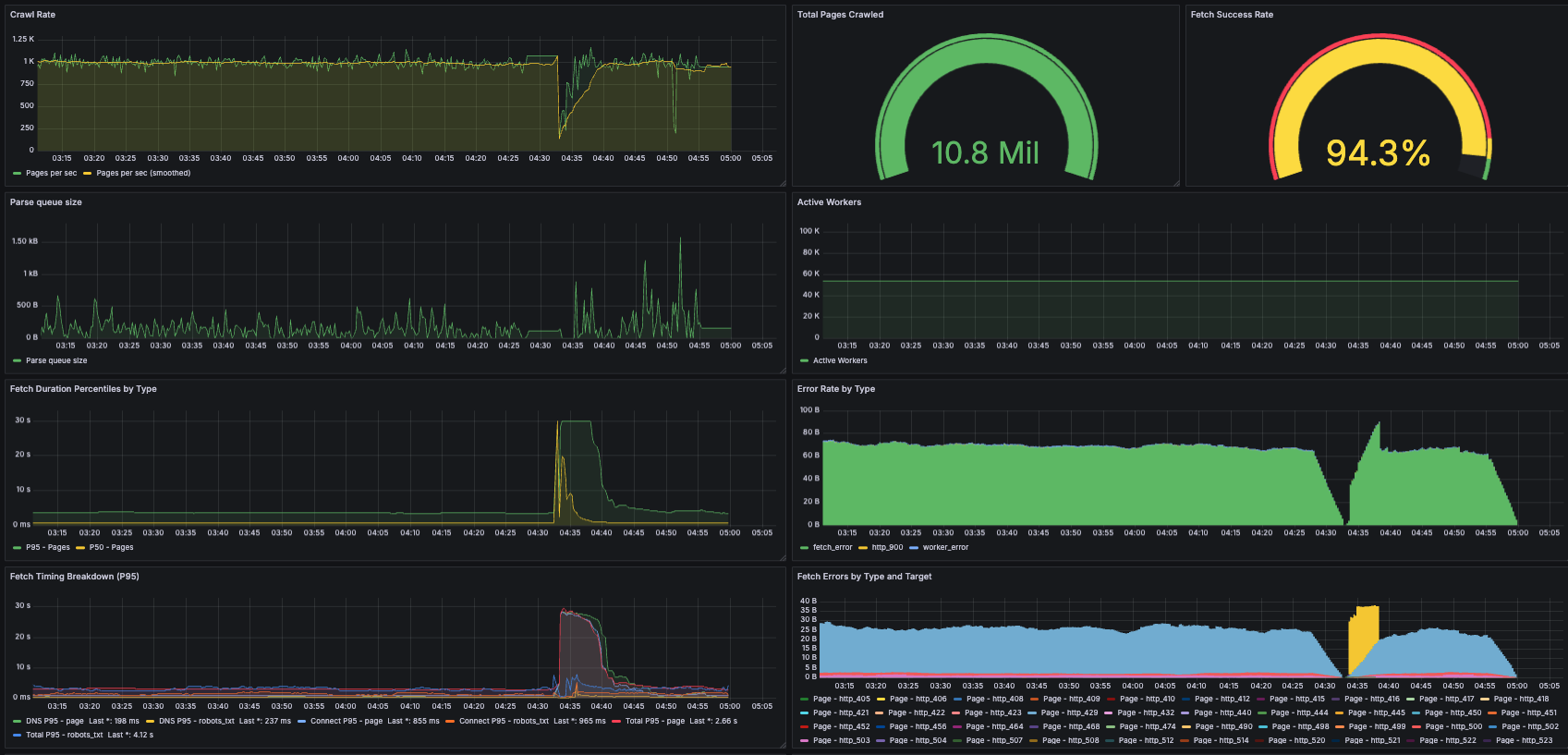
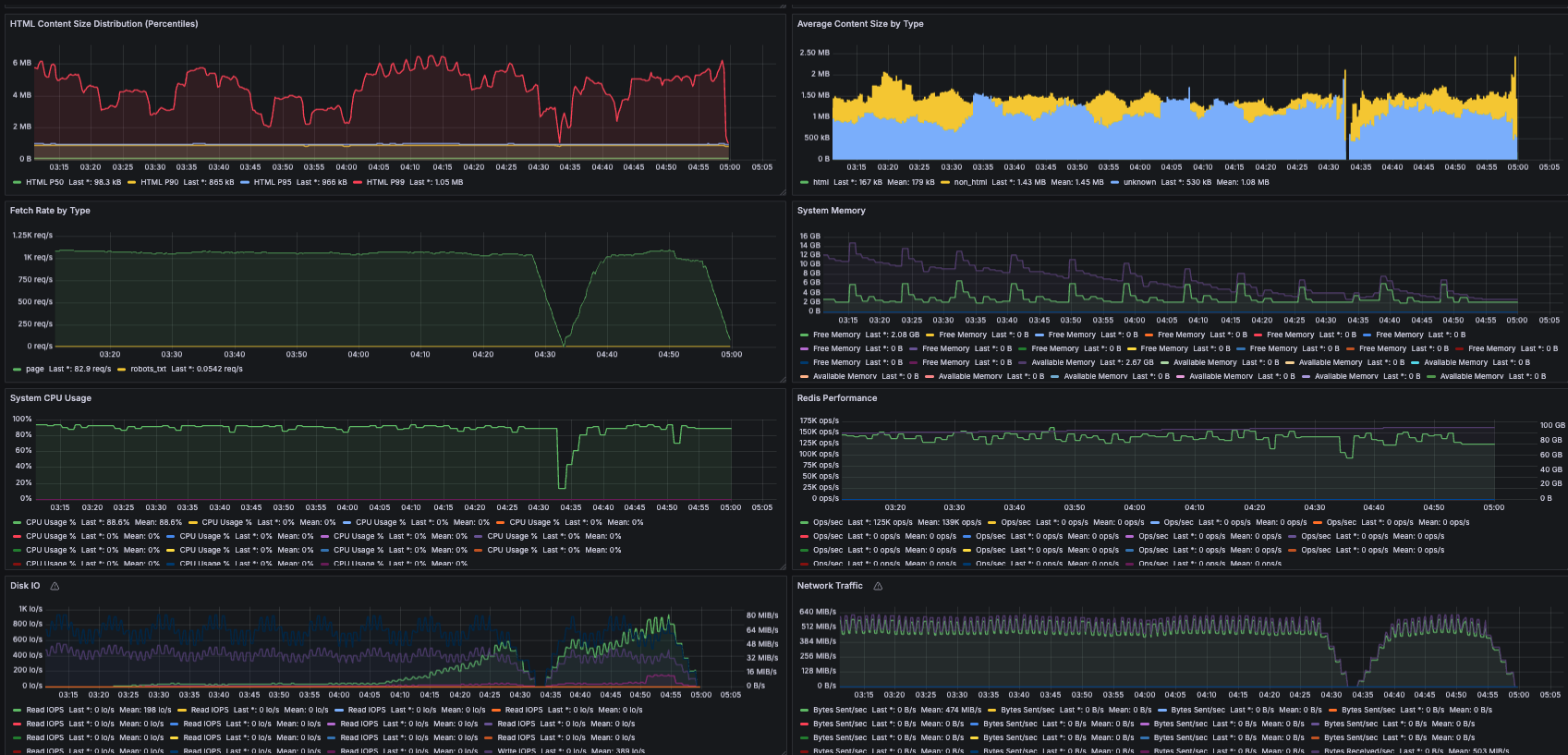
- 12개 노드로 대규모 실험을 하면서 여러 문제가 발생
- 로그 로테이션 미설정 → 루트 볼륨 용량 초과
- 프론티어(대기 URL 목록) 메모리 폭증: 인기 도메인(yahoo, wikipedia 등)에서 수억~수십억 개 URL이 쌓여 노드가 다운됨
- 수동으로 노드 재시작, 프론티어 잘라내기 등으로 복구
"노드가 파리처럼 쓰러지기 시작했습니다. 다행히 장애 허용 설계 덕분에 쉽게 재개할 수 있었습니다."
토론: 이론과 실제, 그리고 앞으로
1. 이론 vs. 실제
- 이론적 분석(예: 5대 머신으로 5일에 100억 페이지 크롤링)과 실제 성능 비교
- 실제로도 네트워크 활용률, 코어 할당 등을 감안하면 비슷한 수준의 효율 달성 가능
2. 앞으로의 과제
- 자바스크립트 미실행에도 아직 많은 웹이 접근 가능
하지만, 예를 들어 GitHub처럼 실제 내용은 JS로 렌더링되는 경우가 많아,
동적 렌더링이 필요한 대규모 크롤링은 훨씬 더 비쌀 것으로 예상
"생각보다 많은 웹이 아직도 JS 없이 접근 가능하다는 점이 놀라웠습니다."
-
크롤한 10억 페이지의 분포와 특성 분석:
살아있는 URL 비율, HTML/멀티미디어 비율 등은 아직 분석하지 못함 -
웹의 변화와 크롤링의 미래:
AI 시대의 대규모 크롤링, Cloudflare의 pay-per-crawl 등
웹 운영자와 크롤러 간의 새로운 균형이 필요
결론: 10년 만에 달라진 웹 크롤링의 현실
- 웹페이지 크기 증가, SSL 보편화, 네트워크 인프라의 발전 등으로
병목이 IO → CPU(파싱, SSL)로 이동 - 적은 예산과 12대의 서버로도 24시간 만에 10억 페이지 크롤링 가능
- 예의와 책임을 지키는 크롤링의 중요성 강조
"저는 예의를 매우 중요하게 생각했습니다. robots.txt를 지키고, 연락처를 남기고, 요청 시 도메인을 제외했습니다."
핵심 키워드 요약
- 24시간, 10억 페이지, 저예산
- 파싱 병목, SSL CPU 부하
- 수평 확장, Redis, 비동기 처리
- 예의(Politeness), 장애 허용
- 웹의 변화, 동적 렌더링, 크롤링의 미래
이 글은 웹 크롤링의 현재와 미래, 그리고 실제로 부딪히는 문제와 해결 과정을 생생하게 보여줍니다.
웹 크롤러를 만들거나 대규모 데이터 수집에 관심 있는 분들에게 많은 인사이트를 줄 수 있을 거예요! 😊