AI 발전의 전반전은 새로운 모델과 학습 방법 개발에 초점을 맞췄으나, 이제는 평가와 문제 정의의 중요성이 커진 후반전에 접어들었다. RL(강화학습)이 일반화됨에 따라 AI가 다양한 작업을 한 가지 레시피로 해결할 수 있게 되었고, 앞으로는 실제 유용성을 높이는 평가 방법과 현실과 맞닿은 문제 정의가 핵심이 될 것이다.
이제 남은 과제는 "AI로 무엇을 평가하고 어떻게 진짜로 세상을 바꾸는가?"에 대한 답을 찾는 데 있다.
1. AI 전반전: 모델과 학습법이 주도한 시대
20세기 후반부터 2020년대 초까지, AI의 발전은 주로 새로운 학습 방법과 모델 구조의 발명에 의해 이루어졌다.
대표적인 예로, 체스 챔피언을 꺾은 DeepBlue, 인간을 넘어서 바둑을 이긴 AlphaGo, 대부분의 사람보다 높은 SAT·변호사 시험 성적, 수학·코딩 올림피아드 메달리스트 AI 등 역사적 사건들이 있다.
"우리는 새로운 학습 방법이나 모델을 개발해서 벤치마크를 점점 더 잘 풀었고, 그게 최초의 승부였다."
논문 인용수 등을 봐도 Transformer, AlexNet, GPT-3 같은 모델이나 방법론은 엄청난 주목을 받았던 반면, 해당 모델의 성능을 측정했던 벤치마크(예: WMT'14, ImageNet)는 상대적으로 적은 주목을 받았다.
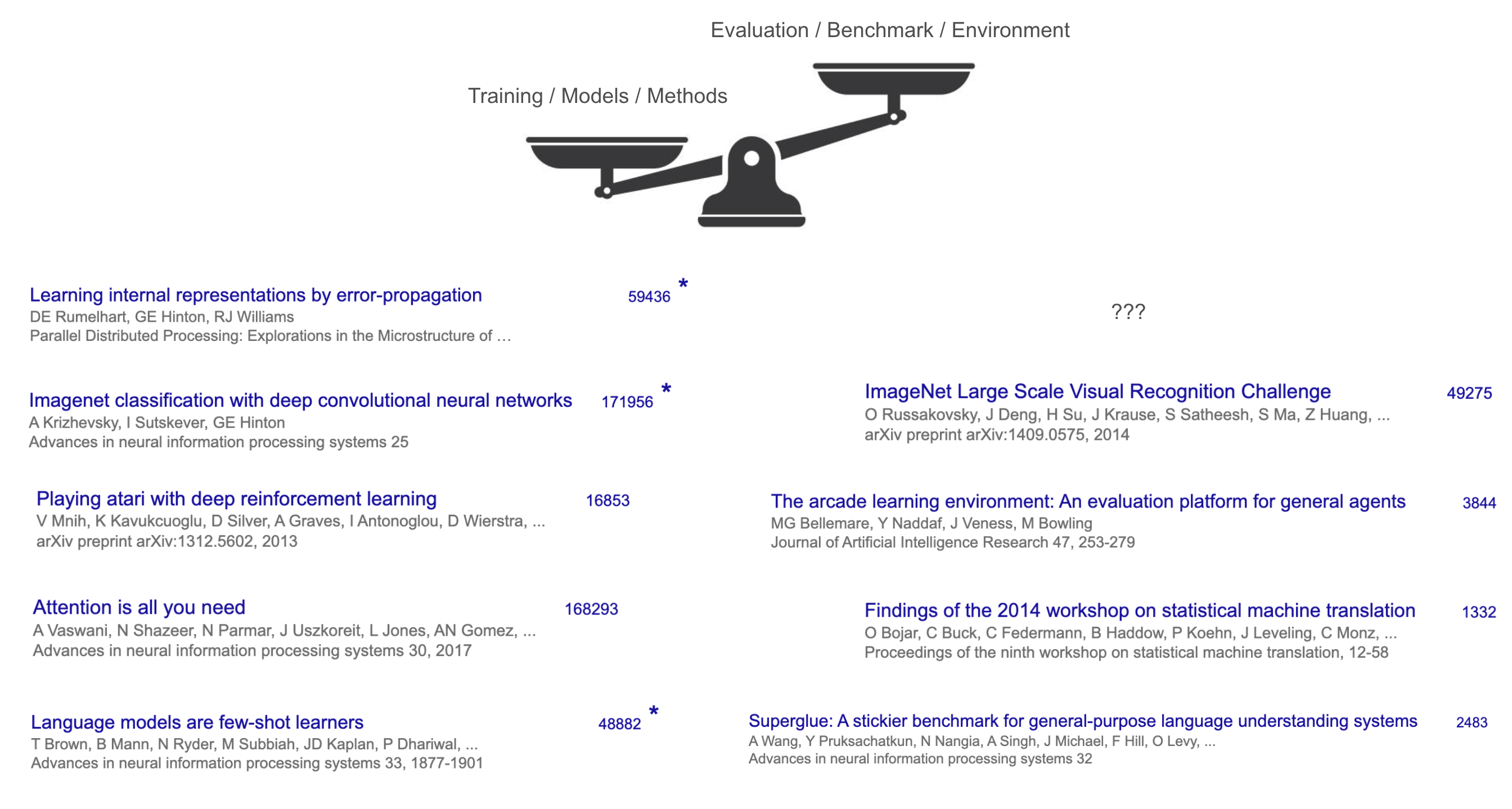
이유는 분명하다. 새로운 모델이나 학습법을 발명한 사람들만이 획기적인 변화를 만들었기 때문이다. 반면 "AI가 무엇을 할지를 정하는 일(=벤치마크 설정)"은 상대적으로 덜 창의적이고, 인간이 이미 잘 하는 일(번역, 이미지 분류 등)을 그냥 AI에게도 하게 하는 수준에 머물렀다.
그렇기에 전반전의 규칙은 단순했다:
- 기존 모델을 넘어서는 혁신적 방법론을 제시한다.
- 그 방법이 벤치마크 점수를 올려 주면 승자다.
이 방식은 오랜 시간 수많은 도메인에서 획기적 성과를 내며 AI 발전을 이끌었다.
2. 레시피의 발견: RL의 진정한 전환
최근 몇 년간, 중요한 변화의 계기가 찾아왔다.
그 변화의 핵심은 다음과 같다.
"세 마디만 꼽자면, 드디어 RL이 작동한다. 좀 더 정확히 말하면, RL이 이제는 일반화된다."
즉, 과거에는 RL(강화학습)로 특정 도메인(예: 바둑, 게임)에서만 좋은 결과를 내는 것이 전부였지만, 이제는 거의 모든 복잡한 작업에서 같은 원리로 AI가 통한다는 것이 증명되었다.
▶ 예전에는 소프트웨어 엔지니어링, 창작 글쓰기, IMO급 수학문제, 마우스&키보드 조작, 장문 질의응답 등 각각 따로 연구해야 했다.
▶ 이제는 하나의 "레시피"가 이들을 대부분 다룰 수 있다.
그 레시피란 크게 세 가지 요소를 섞는다:
- 대규모 언어 사전학습(프리트레이닝)
- 막대한 데이터와 연산규모
- 추론과 행동(Reasoning & Acting)

전통적 강화학습 연구는 거의 항상 '알고리즘'에만 집중했다.
그러나 점차 환경(environment)과 사전지식(prior)이 얼마나 중요한지 드러났고, 그 중에서도 '사전지식' 역할을 하는 언어 사전학습이 결정적이었다.
과거 OpenAI의 'gym', 'Universe', Dota2 에이전트 등은 진전을 이루었지만, 웹 탐색·컴퓨터 사용 분야까지 이어지지 못했고, 한 분야에서 성공한 RL이 다른 분야엔 통하지 않았다.
GPT-2, GPT-3 이후 비로소 결정적인 조각이 드러났다.
"RL의 가장 중요한 부분이 RL 알고리즘이나 환경이 아닌, 사실은 '사전지식(pre-training priors)'에 있었다는 사실"
언어 사전학습이 채팅 등엔 유효했지만, 컴퓨터 사용이나 게임 분야에선 한계가 있었다.
이유는 이 분야들이 인터넷 텍스트 분포와 거리가 멀고, 그대로 SFT/RL을 하면 일반화가 잘 안되기 때문.
하지만 "생각하기", 즉 추론(Reasoning)을 에이전트의 행동 공간에 추가하면, 언어 모델의 사전지식이 새로운 환경에서도 일반화될 수 있었다.

"생각, 즉 추론이란 직접 세상에 영향을 주지 않지만, 공간 자체는 무한하다. 우리는 이 공간을 선택적으로 활용하면서도 매우 유연한 추론 능력을 보인다."
이렇게, '언어 사전학습+추론=범용 강화학습의 레시피'가 정착됐고, 오히려 RL 알고리즘 자체는 사소한 부분이 되어 버렸다.
3. AI 후반전의 시작: 평가와 문제 정의의 전환
이제 이 범용 레시피의 등장으로 전반전의 게임이 바뀌었다.
"레시피는 더이상 전혀 새로운 아이디어를 요구하지 않고, 이미 표준화·산업화되어 벤치마크 점수도 대규모로 개선될 수 있다."
기존 방식대로 기준을 조금씩 올린 새로운 벤치마크를 내놓아도, 곧바로 범용 레시피가 이를 해결해 버릴 것이다.
따라서 이제 남은 진짜 문제는 '어떻게 평가할 것인가'로 이동한다.
"이제는 새로운, 더 어려운 벤치마크를 만드는 것이 아니라, 근본적으로 기존 평가 방식 자체를 의심하고 새로운 평가 세팅을 만들어야 하는 단계다."
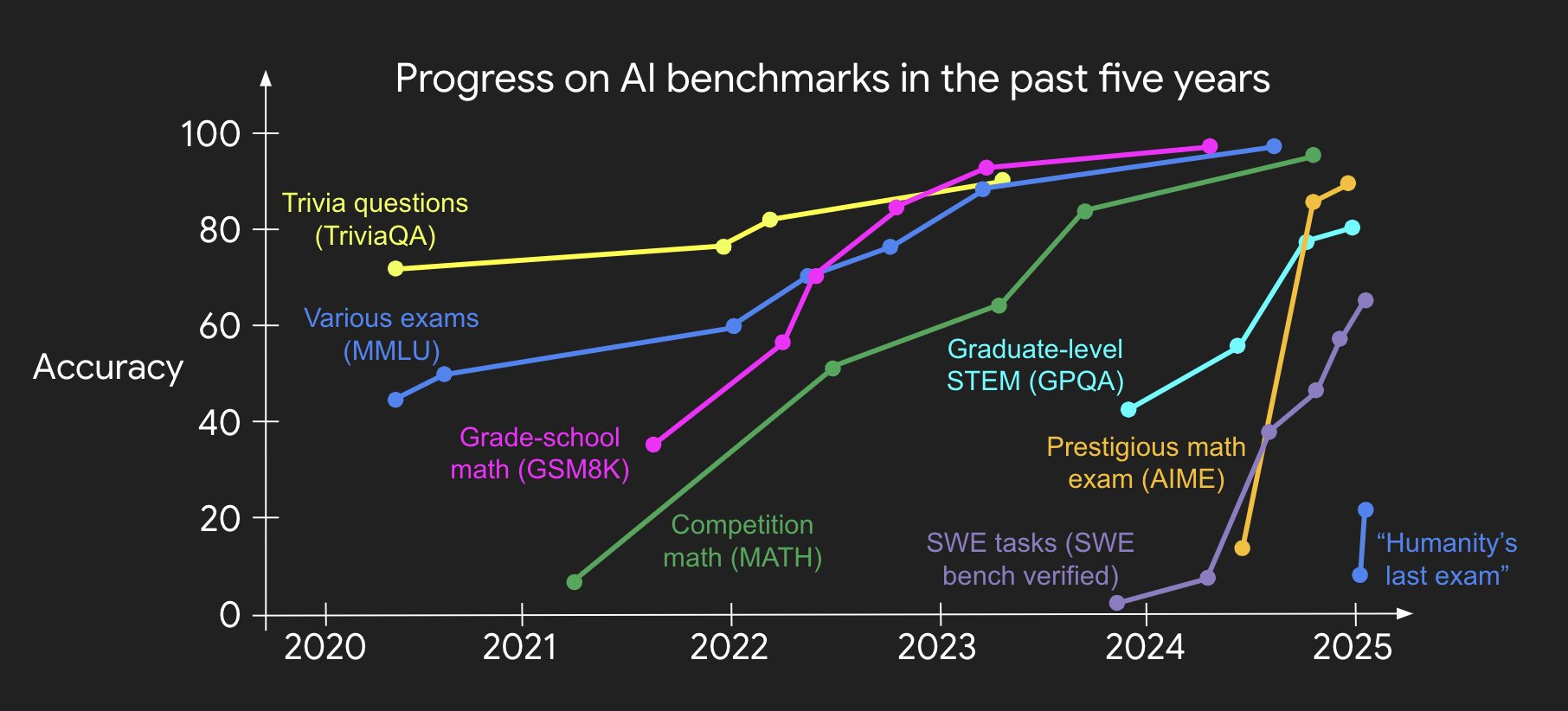
대표적인 AI 성과(체스, 바둑, SAT, 변호사 시험, IOI, IMO 등)는 이미 달성됐지만, 현실 세계(경제, GDP 등)는 크게 변하지 않았다.
저자는 이 현상을 "유틸리티 문제(utility problem)"라고 부른다.
4. 유틸리티 문제와 평가 혁신의 필요성
AI가 각종 게임과 시험을 이겼지만, 실제 경제적 가치(유틸리티)는 획기적으로 달라지지 않았다.
"문제의 근원은 평가(setup)가 현실과 다른 점이 너무 많다는 것에 있다."
주요 차이점과 문제를 간단히 들면:
1. 평가 방식이 너무 자동화만 지향한다:
대부분의 작업이 '입력→AI가 알아서 실행→정답/점수' 구조다.
"현실에서는 에이전트가 사람과 상호작용해야 한다. 고객센터라면 한 번 길게 메시지를 보내고 답만 기다리는 게 아니라, 여러 번 실시간 대화를 주고받아야 진짜 쓸모가 있다."
이에 대한 대응으로 사람 실사용을 포함한 벤치마크(예: Chatbot Arena, tau-bench 등)가 등장하고 있다.

2. 평가가 '독립·동일 분포(i.i.d.)' 전제에만 의존한다:
예를 들어, 500개의 태스크를 독립적으로 실행해 평균 점수를 내는 구조다.
"실제로는 이전 작업 경험이 다음 작업에 도움이 된다. 구글 엔지니어는 한 레포를 계속 볼수록 더 빨리 문제를 해결하지만, AI는 같은 환경에서 전혀 익숙해지지 않는다."
결국, 사람처럼 '장기 기억'이 있어야 하며, 이를 테스트하는 새로운 평가 기준이 필요하다.
핵심 결론:
과거에는 지능이 낮을 때 단순히 벤치마크 점수만 올려도 실용성이 같이 증가했다.
그러나 이제는 범용 레시피가 '기존 평가 프레임'에서는 언제든 이길 수 있으므로,
진짜 실용성을 반영하도록 평가‧문제 정의 자체를 바꾸지 않으면 안 될 시점에 왔다.
5. 후반전의 게임: 실용적 평가, 현실 문제 정의, 그리고 진짜 변화
AI 후반전의 규칙은 다음과 같이 바뀐다.
- 실제 현장과의 간극을 줄이는, 새로운 평가 방식/태스크를 개발한다.
- 이를 범용 레시피로 해결하거나, 그 레시피에도 안 통하는 부분을 찾아 진짜 새로운 방법을 고안한다.
- 이 과정을 계속 반복한다.
이 방식은 새롭기 때문에 어렵지만, 동시에 흥미롭다.
"전반전은 게임이나 시험 문제를 AI가 푸는 것이었지만, 후반전은 바로 실질적으로 유용한 제품을 만들어내고, 이로써 수십억/수조 달러 가치의 회사를 세울 수 있는 기회의 장이다."
혁신적 평가 방식 없이 기존 프레임만 고수하면 점진적 발전만 있을 뿐, 진짜 게임 체인저는 나오기 어렵다.
즉, 새로운 평가와 문제 정의를 통해 AI가 진짜 실용적 가치를 만들어내는 것— 이것이 후반전의 플레이 방식이다.
"새로운 전반전의 승자, 환영한다! 이제 두 번째 게임이 시작된다."
마치며
AI의 발전 방향은 이제 단순한 모델 경쟁이 아니라, 실질적 유용성과 현실 문제 해결에 얼마나 기여하느냐에 초점을 맞춘 새로운 전환점에 이르렀다.
이제는 "AI가 어디까지 할 수 있는가?"보다는, "AI를 어떻게 평가하고, 어떤 문제에 도전하게 할 것인가?"가 혁신의 핵심이다.
지금이 바로 그 후반전의 출발점이다.