1. 무엇을 만들었나?
처음에 저자는 로톡에서 변호사들이 답변을 쓸 때, AI가 자동으로 답변 초안을 작성해주는 크롬 익스텐션을 만들었습니다.
이 확장 프로그램은 변호사들이 기존에 하던 방식 그대로 작업하면서 동시에 AI의 자동완성 기능을 쓸 수 있도록 설계되었습니다.
크롬 익스텐션을 선택한 이유는, 기존 워크플로우를 최대한 방해하지 않으면서 AI 기능을 자연스럽게 접목할 수 있는 방법이기 때문이었습니다.
"변호사님들이 원래 작업하시던 방식 그대로 작업하시면서 동시에 ai 자동 완성 서비스를 이용하실 수 있도록 하는 방법이 익스텐션 방식 뿐이기 때문입니다."
2. 시스템 아키텍처
시스템의 전체 구조는 아래와 같습니다.
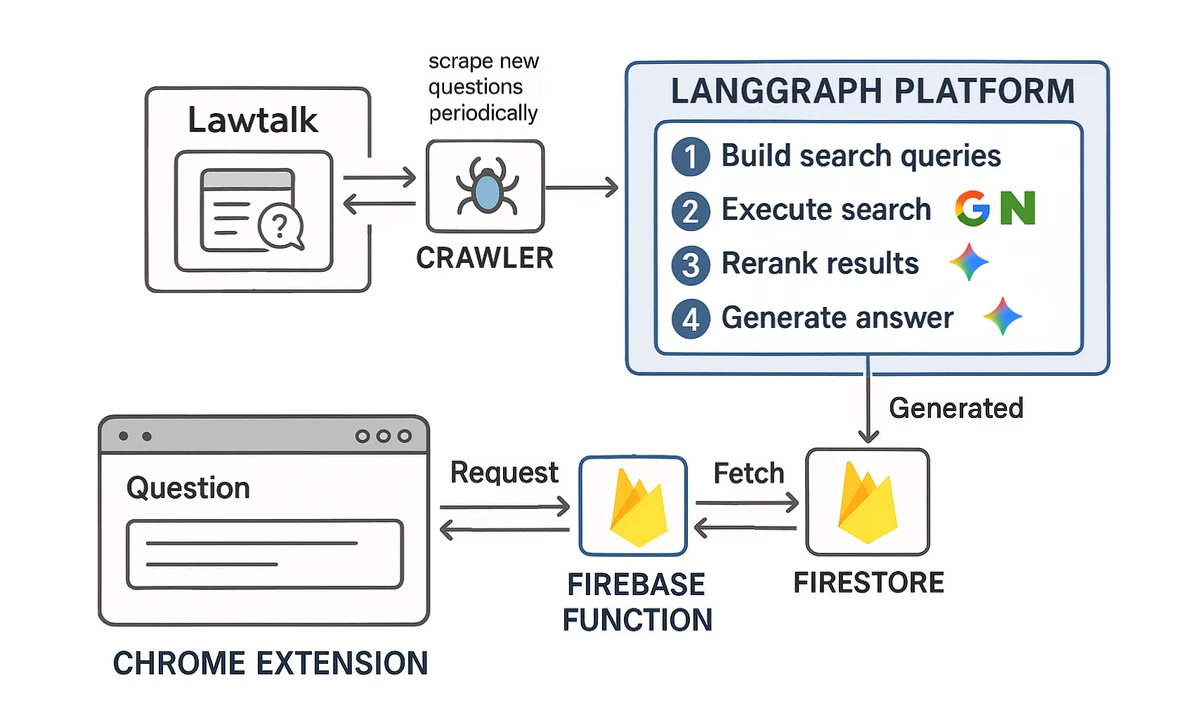
주요 동작 흐름
- 로톡 질문이 들어오면 → 웹 검색을 위한 검색어 추출
- 구글, 네이버 등에서 해당 검색어로 검색
- 검색 결과를 질문과의 관련성 기준으로 재정렬
- 가장 관련성 높은 문서를 바탕으로 답변 생성
이 방식은 퍼플렉시티(Perplexity) 등 웹 검색 기반 답변 생성 서비스와 유사하지만,
- 법률 분야에 특화된 검색어 추출 설계
- 질문 등록 시점과 답변 작성 시점 사이의 시간 간격 활용
등의 차별점이 있습니다.
법률 분야 특화 설계
- 상세한 분류체계도(택소노미)를 만들어, 모든 법률 질문을 커버할 수 있도록 함
- 질문의 법적 쟁점을 정확한 법률 개념과 용어로 정리하는 것이 핵심
"이 문제(일반인의 법률 질의에 답변하는 것)의 본질이 질문의 법적 쟁점을 정확한 법률 개념과 용어로 정리하는 것이라고 판단하였기 때문입니다."
- 언어모델은 아직 법률 질문에서 쟁점을 정확히 법률 용어로 정리하는 데 한계가 있음
- 그래서 분류체계도를 참고해 단계별(step-by-step) 쟁점 정리를 하도록 설계
"모든 법 분야의(민법, 형법, 행정법 등) 거의 모든 주제, 쟁점을 망라하는 거대한 분류체계도를 만들고 언어모델로 하여금 그 분류체계도를 참고하여 단계별로(step-by-step) 쟁점을 정리하도록 하면 훨씬 결과가 좋아진다는 것을 확인하였고 그렇게 구현하였습니다."
3. 기술 스택
이 프로젝트에서 사용한 주요 기술은 다음과 같습니다.
- 랭그래프(LangGraph): 전체 워크플로우 구현 및 호스팅
- 랭체인(LangChain), 랭스미스(LangSmith): 다양한 모듈 활용
- 언어모델: 구글 제미나이(Gemini) 2.5 플래시와 2.0 플래시 혼용 (한국어 성능이 OpenAI보다 우수)
- 서퍼(Serper), 파이어크롤(FireCrawl): 구글 검색 API, PDF 처리 등
- 네이버 검색 API: 네이버 검색 결과 활용
- 구글 클라우드 스케쥴러, 클라우드 빌드: 로톡 질문 주기적 수집 및 빌드 자동화
- 파이어스토어, 파이어베이스 함수: 분석 결과 저장 및 데이터 제공
- 프론트엔드: 크롬 익스텐션이 파이어베이스 함수에 데이터 요청, 결과 수신
4. 배운 점들 – 텍스트 데이터에 대한 새로운 시각
저자는 이번 프로젝트를 통해 텍스트 데이터를 바라보는 새로운 관점을 얻었다고 말합니다.
이미지와 텍스트의 공통점
문병로 교수님의 강의에서, 이미지는 행렬을 곱해 다양한 변형이 가능하다는 점을 설명합니다.

- 텍스트 데이터도 임베딩 모델을 통해 벡터로 변환 가능
- 이 벡터에 행렬을 곱하면 다양한 변환(요약, 답변 등)이 가능
"텍스트를 입력 받아 텍스트를 출력하는 모든 텍스트 처리 작업들이 본질적으로는 이미지에 행렬을 곱해 원하는 형태로 이미지를 변형하는 것과 다르지 않다는 사실을 알게 되었습니다."
임베딩과 공간 변환
- 아직은 임베딩 벡터 → 텍스트로의 완벽한 변환은 어렵지만,
- 텍스트 처리 작업을 공간 변환으로 바라보게 됨
- 이를 바탕으로 mini two-tower 모델을 시도
Extreme Classification과 mini two-tower 모델
- 질문에 가장 관련성 높은 답변 찾기는 Extreme (multi label) classification 문제
- 사람이 한다면 태그를 붙여서 매칭
- 이 태그 변환도 행렬곱(공간 변환)으로 볼 수 있음
Two-tower 모델 구조
- user 타워: 유저 정보 → 임베딩 벡터
- candidate 타워: 추천 대상 정보 → 임베딩 벡터
- 두 임베딩의 유사도로 추천
mini two-tower 모델
- OpenAI나 Gemini의 텍스트 임베딩 모델로 질문/답변 임베딩
- 이 임베딩을 태그로 변환하는 작은 모델만 새로 학습
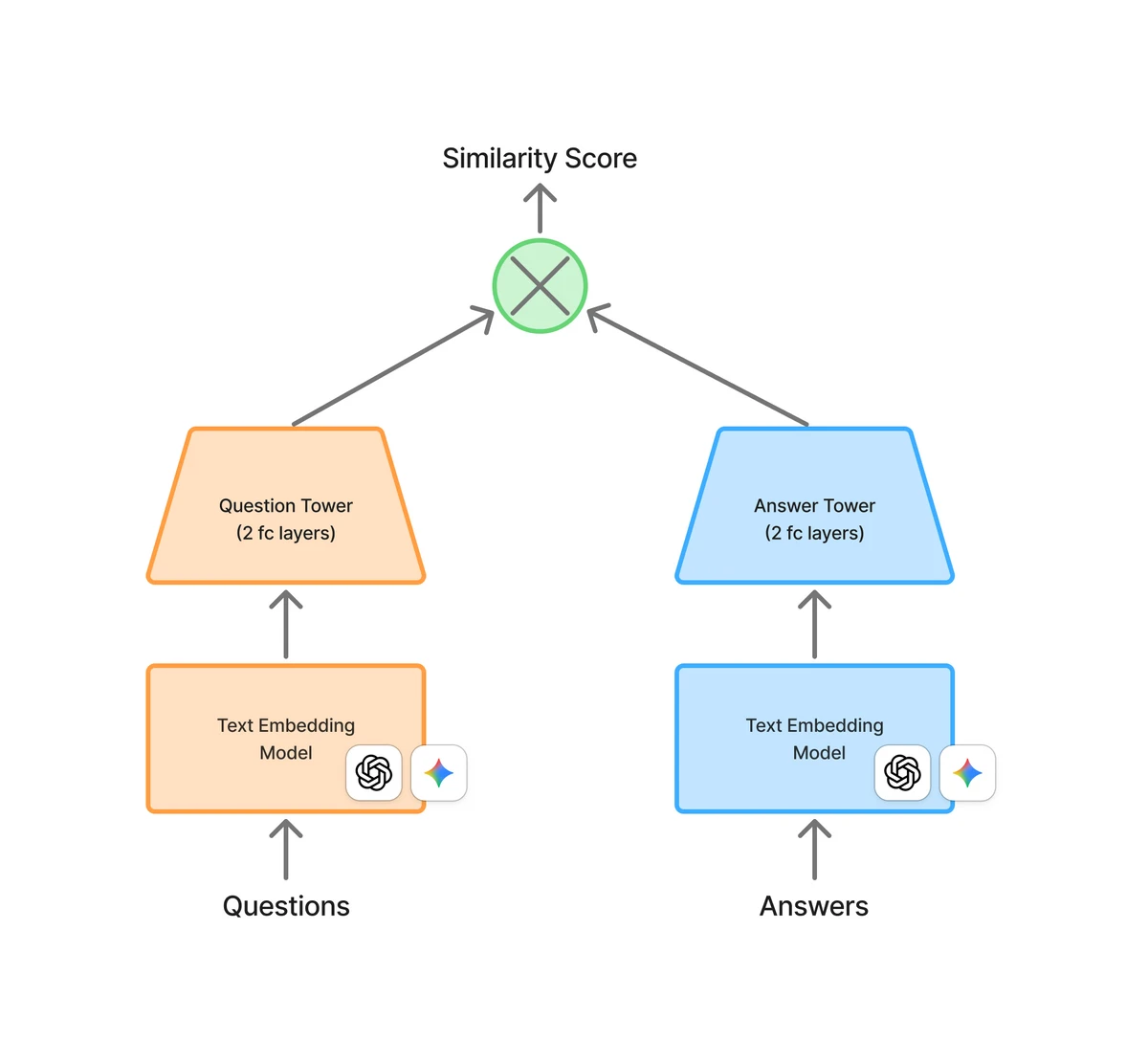
- 공개 Q&A 데이터셋으로 실험
- 질문 타워와 답변 타워 모두 임베딩 입력/출력
- 유효한 질-답 쌍은 임베딩 유사도 높게, 무관한 쌍은 낮게 학습
"학습 데이터 중 유효한 질-답 쌍(즉, 실제 질문-답변 쌍)에 대해서는 두 모델의 임베딩 출력값 유사도가 높고, 유효하지 않은 질-답 쌍에(즉, 질문과 엉뚱한 답변 쌍) 대해서는 두 임베딩 출력값의 유사도가 낮아지는 것을 학습 목표로 설정하였습니다."
- 하지만 overfitting 문제로 성능이 좋지 않았음
- 원인: 텍스트 임베딩 모델의 성능 한계, 입력 데이터의 불완전성
The Bitter Lesson에 관하여
- 결국 질문을 태그로 변환하는 작업을 벡터 공간이 아닌 언어모델+분류체계도로 전환
- Richard S. Sutton 교수의 "the bitter lesson"을 접하며 고민
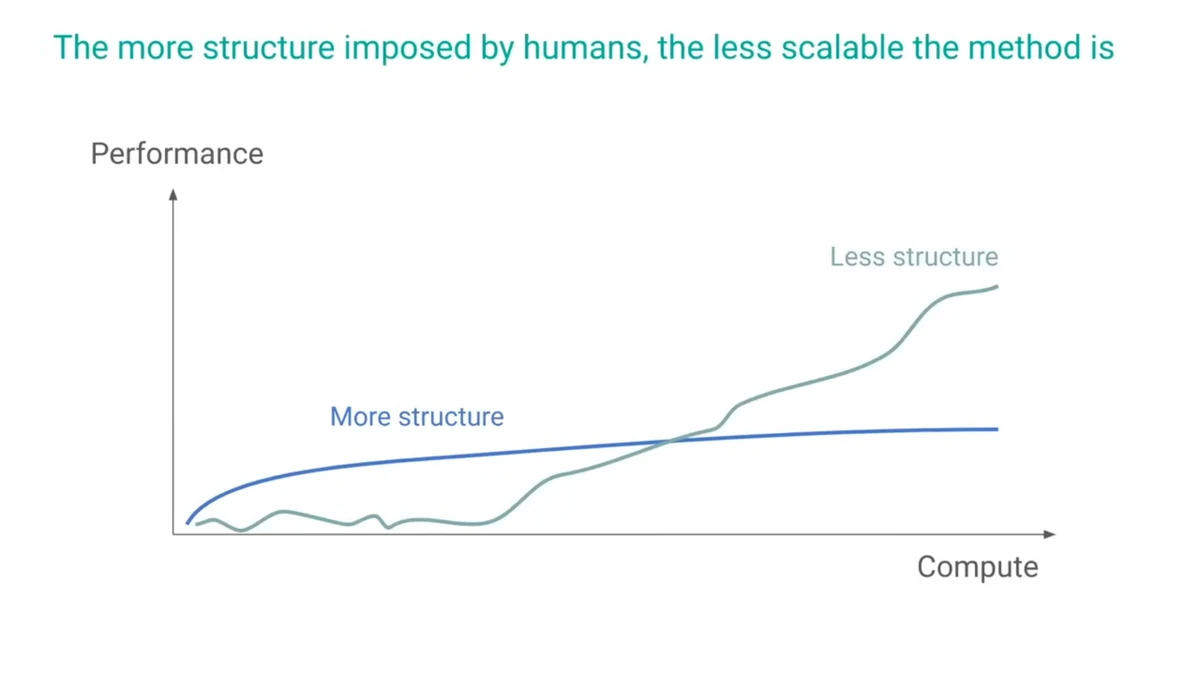
"이렇게 사람의 지식을 이용해 문제에 접근하는 방식은 단기적으로는 좋은 성과를 낼 수 있어도 장기적으로는 좋은 결과를 만들기 어렵다는 Richard S. Sutton 교수님의 "the bitter lesson"을 접하게 되면서 이 방법에 대해 다시 고민하게 되었습니다."
저자의 결론
- 연구와 비즈니스는 다르다
- 인간의 지식 활용과 일반적 방법(연산량 기반)은 반드시 상충하지 않는다
- 법률 분야는 수학/코딩과 달리 검증 가능한 정답이 명확하지 않음
- 변호사시험 객관식도 오래 생각한다고 답이 나오는 문제가 아님
"변호사시험의 객관식 문제들은 그것과 마찬가지로 10초 안에 정답이 생각나지 않으면 10분을 생각해도 정답을 찾아내기 어려운 문제들입니다."
법률 분야 추론 모델 학습 아이디어
- 법률 서적에서 문장 추출 → 목차와 함께 언어모델에 입력
- 문장이 어느 섹션에서 왔는지 추론하게 함
- 명확한 정답, 대량의 학습 데이터 확보 가능
- 법률 문제 전체 해결은 어렵지만, 법체계 영역 분류에는 유용
5. 트러블 슈팅
가장 큰 문제는 랭체인(LangChain)의 ChatGoogleGenerativeAI 클래스에서
structured output 생성 시 배열이 포함된 경우 오류가 발생한 점이었습니다.
- 원인: 응답 청크를 스트리밍으로 받을 때, 구글이 마지막에 빈 청크를 추가로 보내는 경우 발생
- 랭체인 클래스가 이를 제대로 처리하지 못함
"저는 랭체인 BaseChatModel을 상속하는 커스텀한 ChatModel 클래스를 만들어서 마지막에 빈 청크가 오는 경우에도 잘 처리되도록 구현하여 문제를 해결하였습니다."
6. 크게 도움된 자료들
프로젝트를 진행하며 머신러닝을 공부하는 데 도움이 된 자료들입니다.
- 서울대 데이터 사이언스 대학원 이준석 교수님 유튜브
- L1, L2 정규화, 트랜스포머 구조 등 기초부터 심화까지 폭넓게 다룸
- 이준석 교수님 채널
- Algorithmic Simplicity
- CNN, RNN, 트랜스포머 등 딥러닝 구조의 원리와 발전 과정 설명
- CNN 영상
- Welch Labs
- Mechanistic Interpretability 등 흥미로운 주제 다룸
- Mechanistic Interpretability 영상
마무리 🌱
이 프로젝트는 법률 분야에 특화된 AI 자동완성을 만들면서,
- 텍스트 데이터의 본질에 대한 새로운 시각
- 모델 설계와 한계
- 실제 서비스 구현에서의 트러블 슈팅
- 연구와 비즈니스의 균형
등 다양한 배움을 얻게 해준 경험이었습니다.
"텍스트를 다루는 것이 본질적으로는 하나의 공간 변환이라고 바라보게 되면서 two-tower 모델을 약간 변형한 mini two-tower 모델을 시도해볼 수 있었습니다."
"연구의 영역과 비즈니스의 영역은 다르다. 인간의 지식을 활용하여 성능을 향상시키는 것과 연산량을 때려 박아 일반적인 방법으로 문제를 해결하는 것이 반드시 상충되는 것은 아니다."
핵심 키워드:
- 로톡, 크롬 익스텐션, AI 자동완성, 법률 분야, 검색어 추출, 분류체계도, 임베딩, two-tower 모델, the bitter lesson, 트러블 슈팅, 머신러닝 학습 자료
이상으로, "Cursor for 로톡 변호사" 개발 경험의 시간순 상세 요약이었습니다! 🚀