OpenAI가 2025년에 공개한 gpt-oss 시리즈(20B, 120B)는 GPT-2 이후 6년 만에 다시 선보인 완전 공개 가중치(오픈웨이트) LLM입니다. 본문에서는 gpt-oss의 핵심 구조를 GPT-2, Qwen3와 비교하며 변화의 맥락을 짚고, 최신 옵티마이제이션, 효율성 개선, 다양한 벤치마킹 결과를 분석합니다. 지금의 LLM 발전사가 어떻게 이어져 왔는지, 그리고 오픈웨이트 모델이 가지는 의미를 세밀하게 이해할 수 있습니다.
1. gpt-oss의 공개: 2019년 GPT-2 이후 첫 대규모 오픈웨이트 LLM
OpenAI가 이번 주, 가중치를 공개한 두 가지 대형 언어모델 gpt-oss-20b와 gpt-oss-120b를 릴리즈했습니다. 이는 무려 2019년 GPT-2 이후 최초의 완전 오픈웨이트 대규모 LLM입니다. 눈에 띄는 점은 효율적인 최적화 덕분에 개인용 GPU나 단일 H100 카드 하나로도 실행이 가능하다는 것인데요, 이는 추후 자세히 다룹니다.
"gpt-oss 모델은 각각 고급 프리트레이닝과 포스트트레이닝 기술로 학습되었습니다."
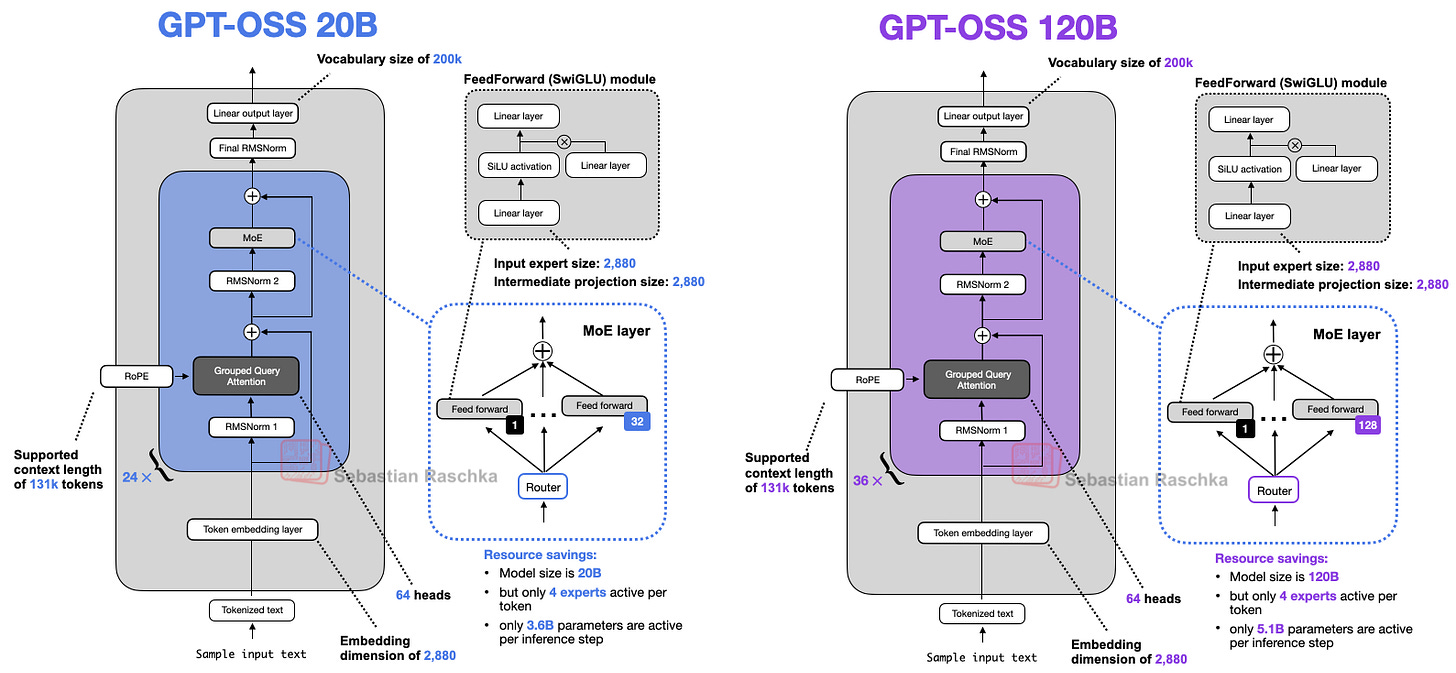
gpt-oss-20b는 RTX 50xx급 GPU(16GB VRAM), 120b는 80GB H100에서도 구동이 가능하며, 본격적인 분석에 앞서 모델 구조와 공개 범위, 실제 활용 방법까지 친절하게 설명합니다.
2. GPT-2와의 비교: LLM 구조 진화의 큰 흐름
GPT-2(2019)는 트랜스포머 아키텍처 기반의 디코더-only LLM입니다. gpt-oss 역시 뿌리는 같습니다. 하지만 여러 부분에서 발전이 있었습니다.
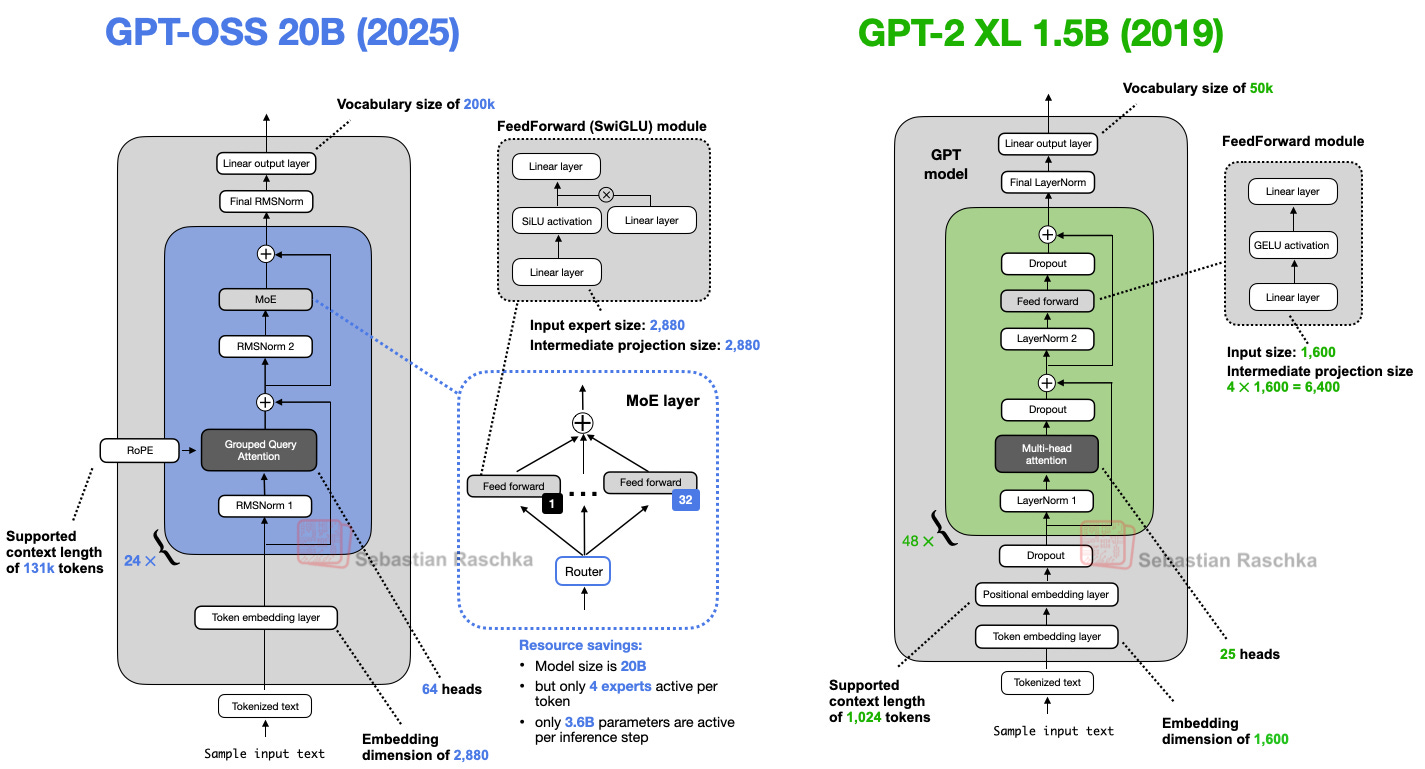
대표적인 아키텍처 차이와 그 배경을 살펴볼게요:
2-1. 드롭아웃(Dropout)의 감소
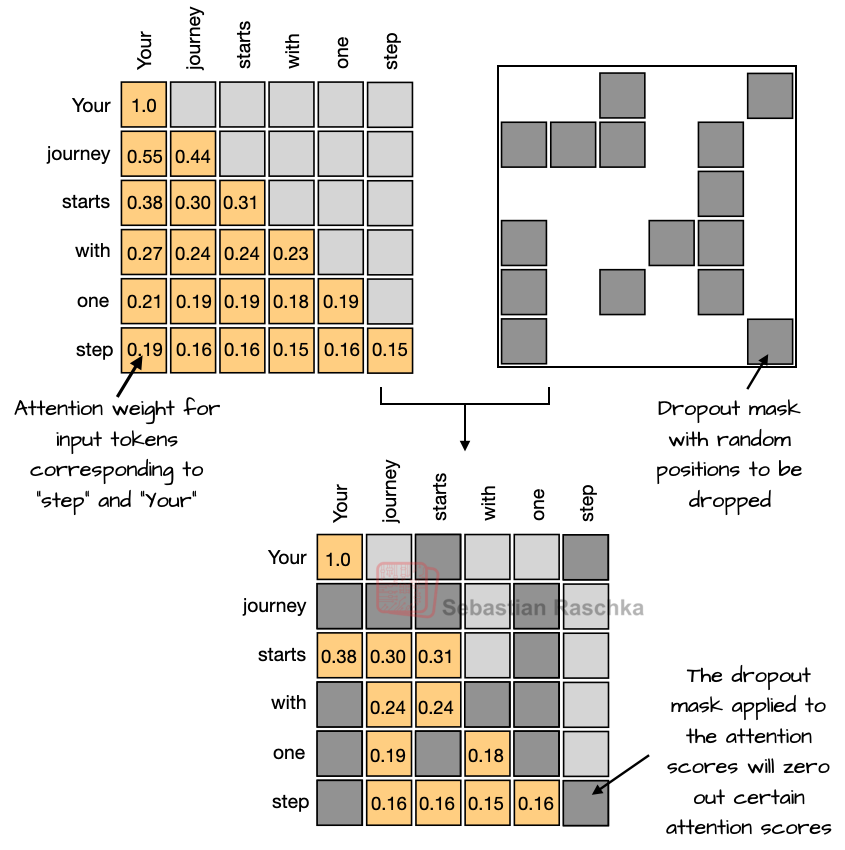
GPT-2 시절엔 과적합을 막기 위해 널리 사용되던 드롭아웃이지만, 최근 LLM은 엄청나게 방대한 데이터셋을 1에폭으로 학습하기 때문에 드롭아웃의 효과가 거의 없습니다.
"드롭아웃은 LLM엔 좋지 않습니다. 최근 실험에서도 다운스트림 성능이 오히려 떨어진다고 확인되었습니다."
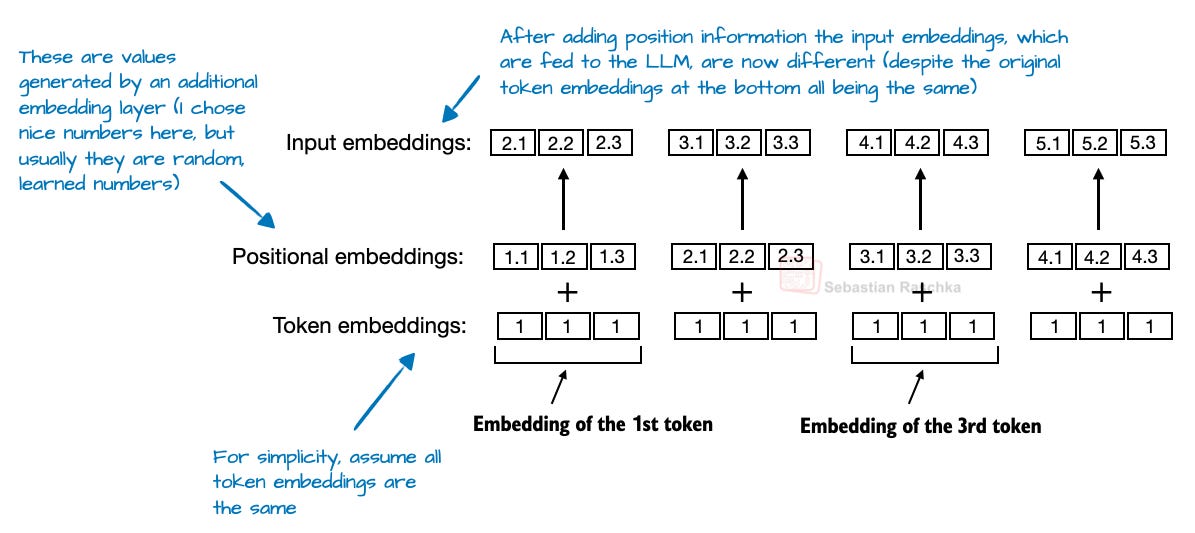
2-2. 위치 임베딩: 절댓값에서 RoPE로
초기엔 절대 위치 임베딩을 썼으나, 최근엔 RoPE (Rotary Position Embedding) 방식이 표준이 되었습니다. RoPE는 쿼리-키 벡터를 토큰별로 회전시켜 위치를 코드화합니다.
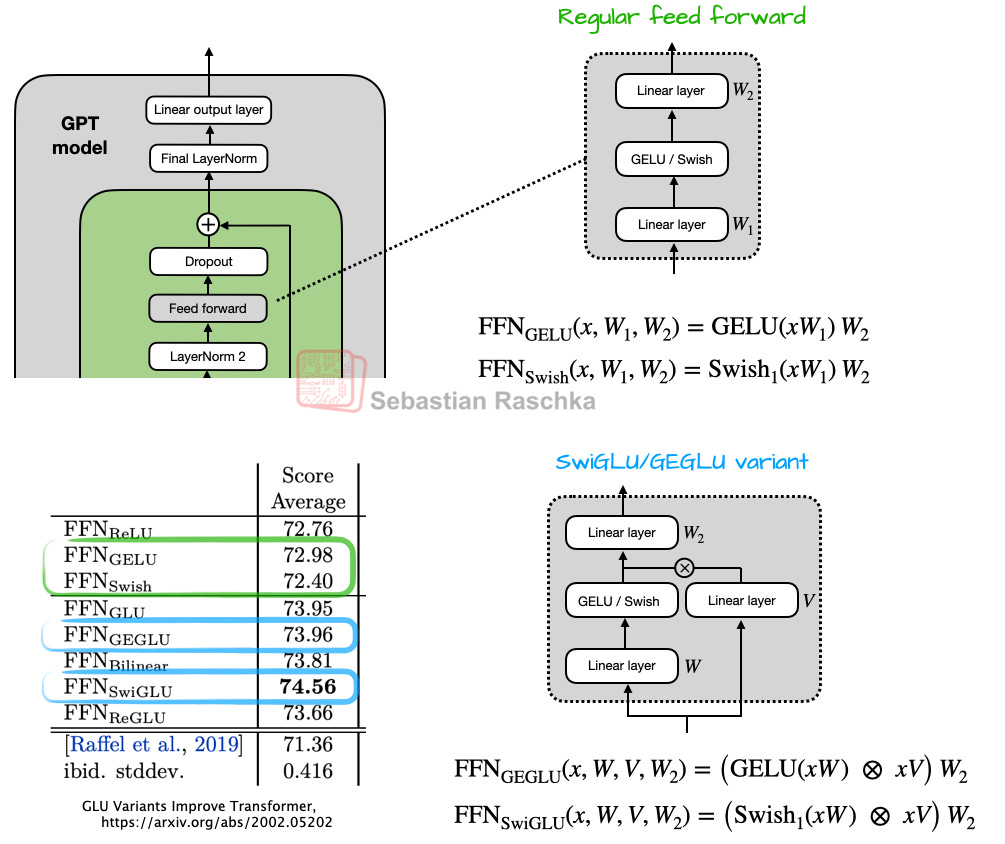
2-3. 액티베이션 함수: GELU에서 Swish/SwiGLU로
처음엔 GELU가 쓰였으나 Swish, SwiGLU 등 계산량이 적고 (실제로는 더 적은 파라미터로 동일 효과) 성능도 비슷한 신형 함수로 교체되었습니다.
"SwiGLU 같은 GLU 계열은 단순히 더 많은 파라미터를 쓰는 것처럼 보이지만, 실제론 적은 파라미터로도 더 좋은 성능을 냅니다."
3. 주요 혁신 기술: Mixture-of-Experts, GQA, Sliding-Window Attention
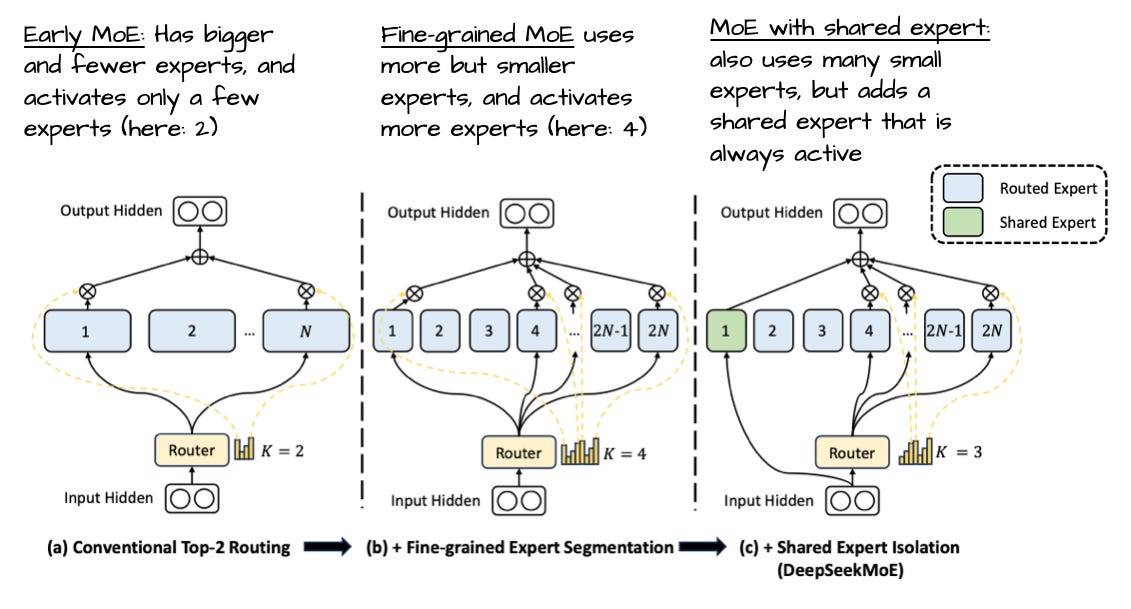
3-1. Mixture-of-Experts(MoE)
전통적 피드포워드 레이어 대신 여러 전문가 모듈을 둬 일부만 활성화(라우팅)하는 MoE가 도입되었습니다. 덕분에 전체 파라미터 수는 늘어나지만, 실제 계산엔 일부만 쓰기 때문에 효율성은 챙기고, 학습 용량은 대폭 커집니다.
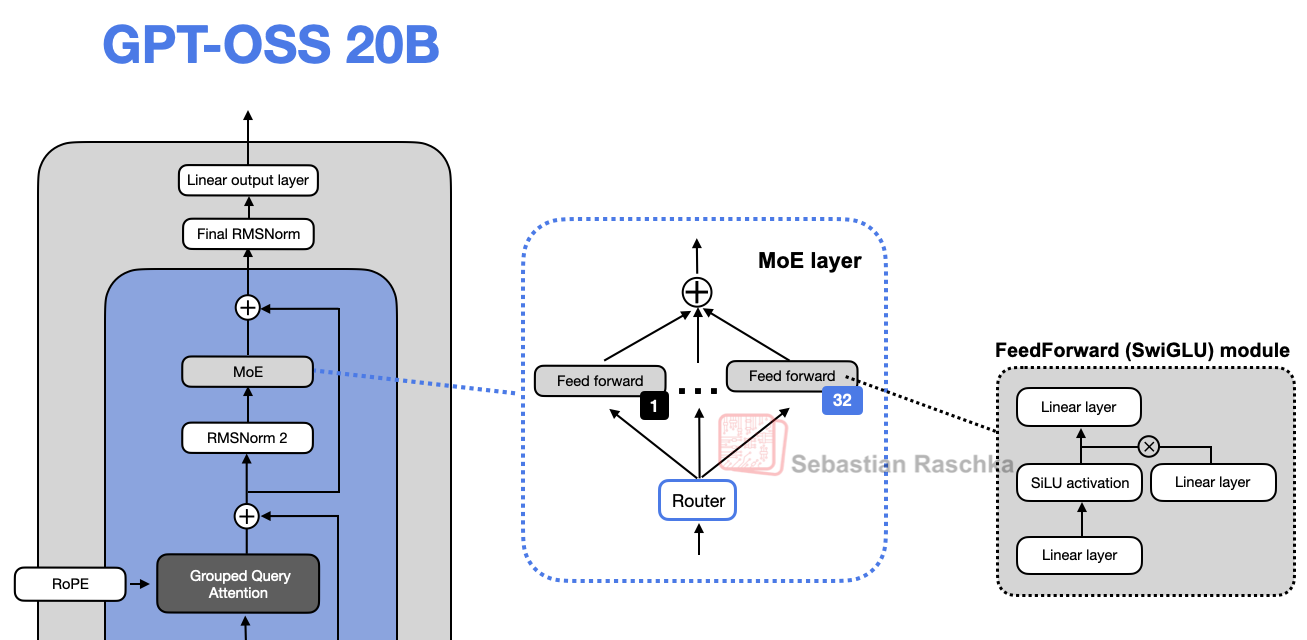
"흥미롭게도 대부분의 MoE 모델에서 전문가(Expert) 가중치가 전체 모델 파라미터의 90% 이상을 차지합니다."
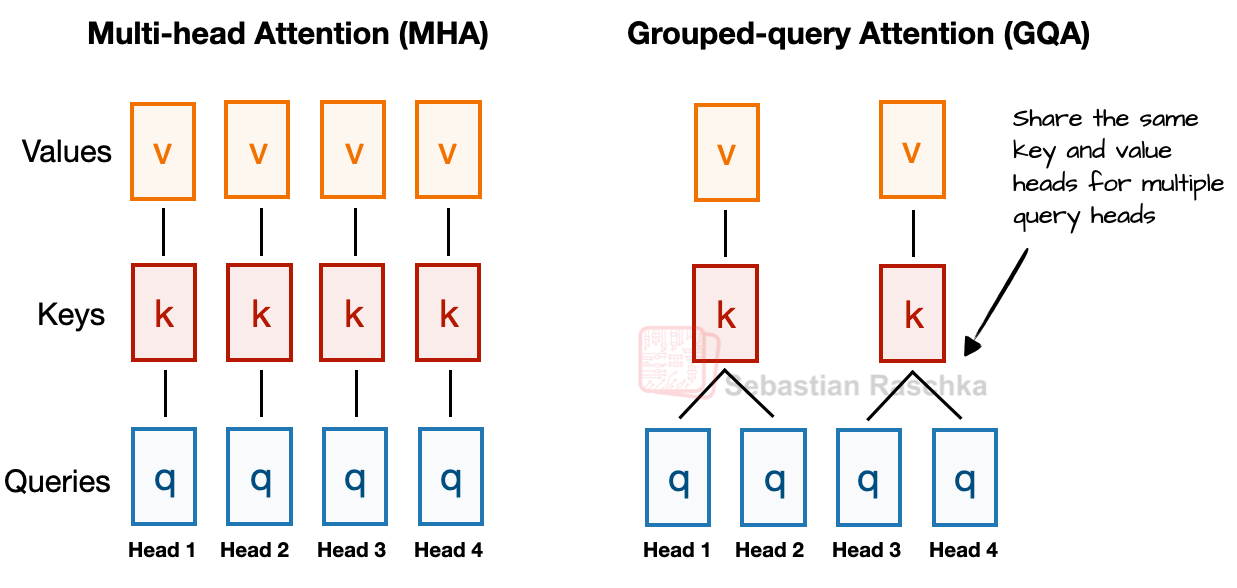
3-2. GQA(Grouped Query Attention)
GQA는 여러 쿼리 헤드가 키/밸류를 공유해 메모리 사용량 및 계산량을 줄이는 효율적 어텐션 방식입니다.
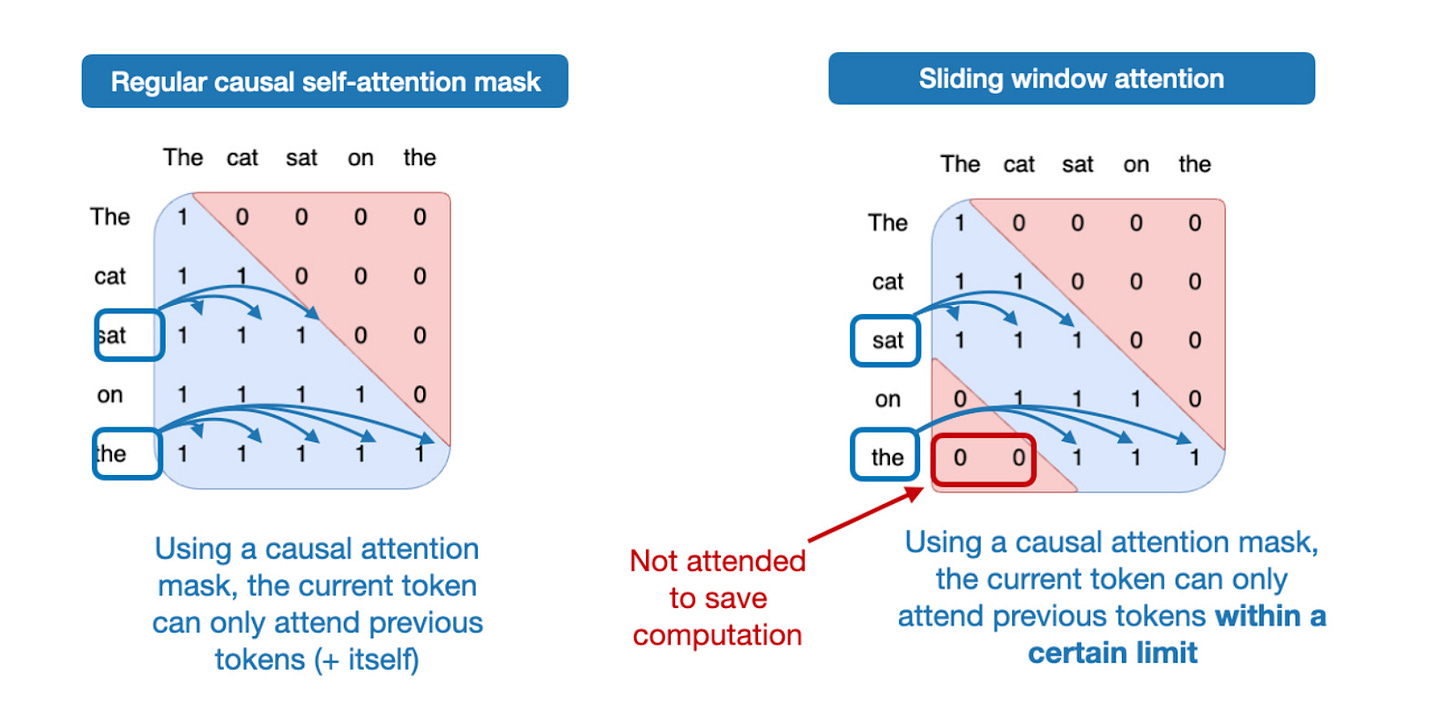
3-3. Sliding-Window Attention
Mistral 등에서 대중화된 슬라이딩 윈도우 어텐션은 매 두 번째 레이어마다 문맥을 128토큰 범위로 제한, 계산량을 획기적으로 줄입니다.
"gpt-oss는 모든 레이어에서 슬라이딩 윈도우를 쓰지 않고, 2개 중 1개, 즉 번갈아 제한 어텐션으로 효율을 극대화합니다."
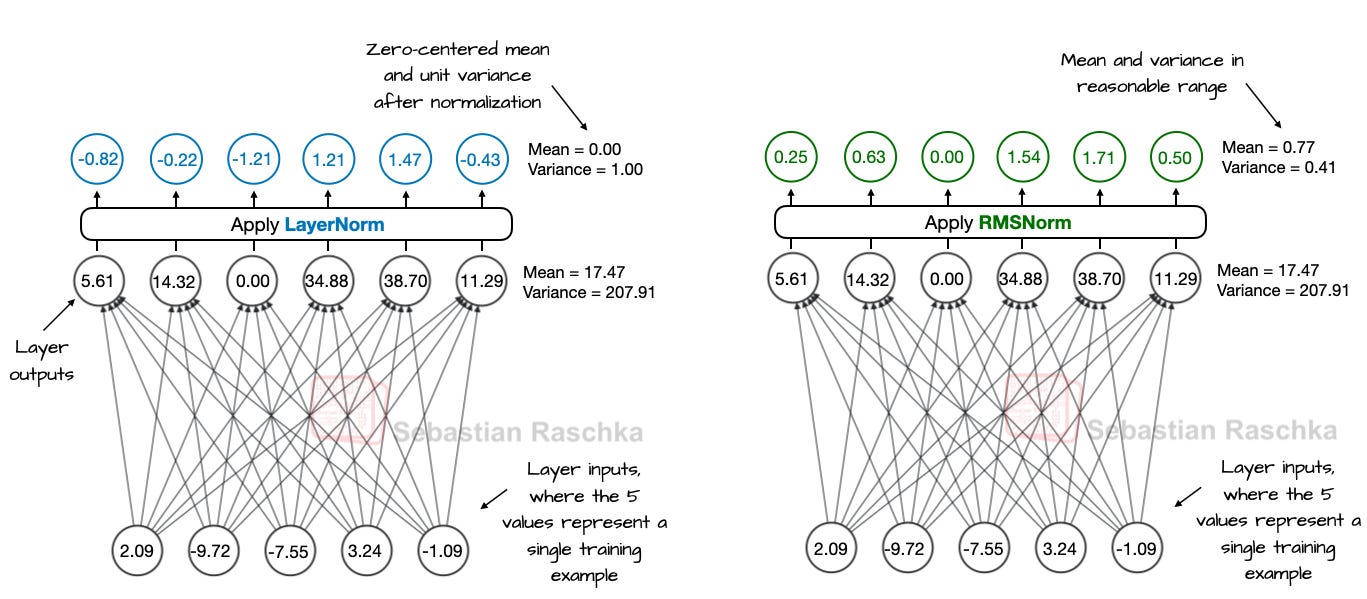
3-4. RMSNorm 도입
모든 레이어 정규화 과정에서, LayerNorm보다 연산량이 적고 GPU 효율이 좋은 RMSNorm을 채택해, 최근 LLM에서 표준처럼 쓰이고 있습니다.
4. gpt-oss vs Qwen3: 깊고 얇음 vs 얕고 넓음의 대결
2025년 5월에 출시된 Qwen3와의 비교를 통해 최근 LLM 아키텍처 트렌드를 구체적으로 살펴볼 수 있습니다.
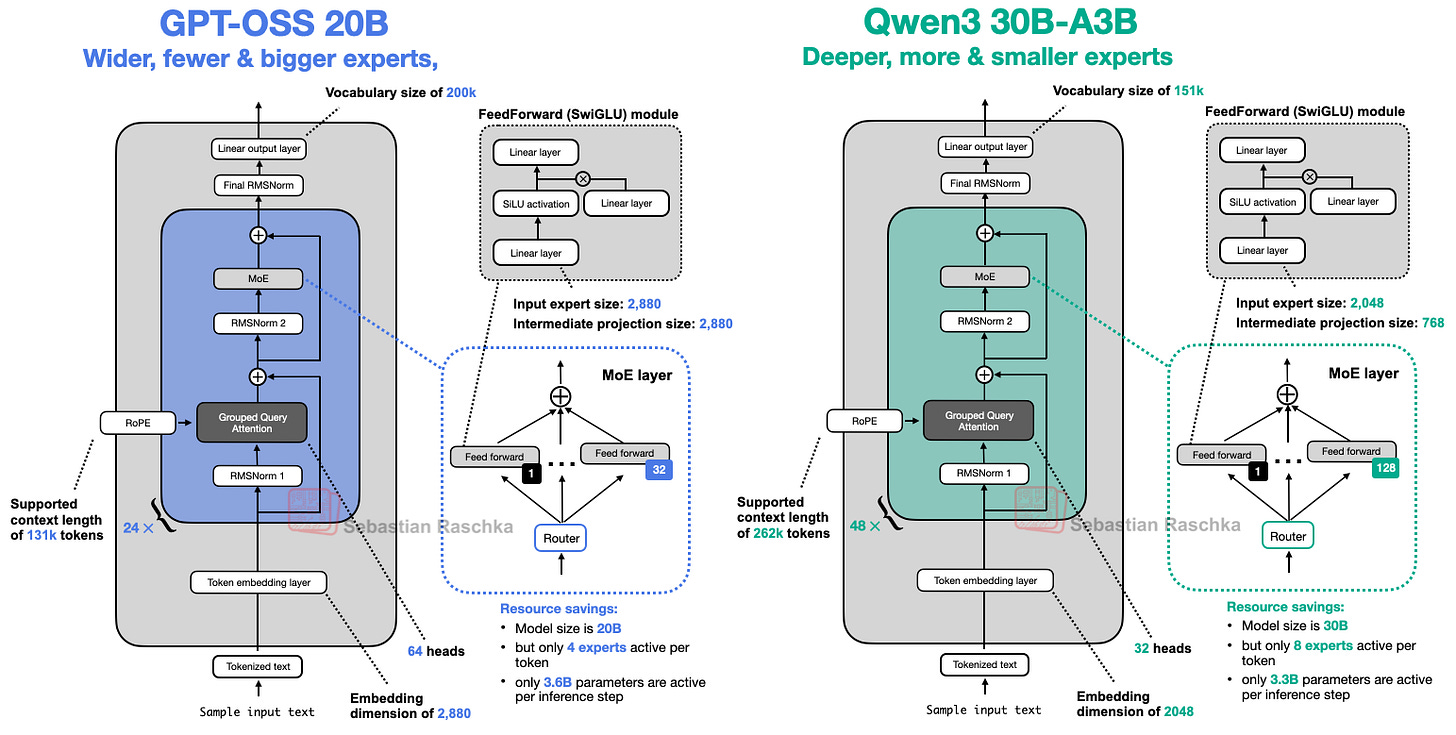
- Qwen3는 48개 블록의 깊은 구조, gpt-oss는 24개 블록의 넓은 구조(임베딩 2880 vs 2048, 전문가 크기도 큼)를 가집니다.
- 전문가 수에서는 Qwen3가 훨씬 많지만 각 전문가는 gpt-oss가 큽니다.

"깊은 모델은 더 유연하지만, 훈련이 어렵고(그래디언트 폭주/소실), 넓은 모델은 병렬화가 효율적이라 추론 속도가 빠릅니다."
실제로 Gemma2 논문 실험에 따르면, 동일 파라미터 기준으론 '더 넓은' 구조가 미세하게 더 좋은 점수를 기록했다고 합니다.
또한 최근 LLM 트렌드는 전문가를 늘리고 각 전문가 크기는 줄이는 방식(DeepSeekMoE 참고)이 대세임을 보여주죠.
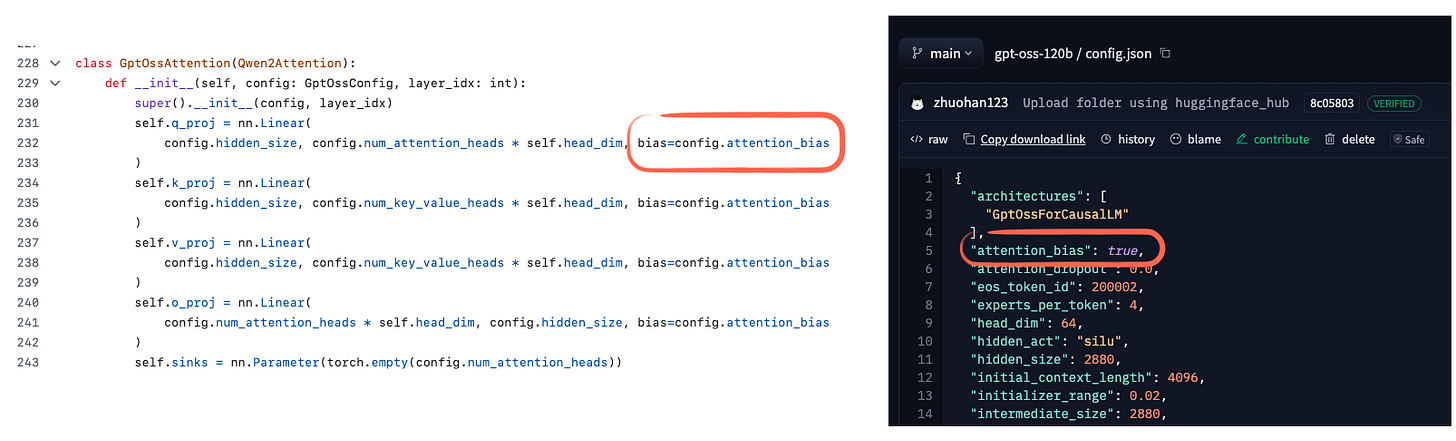
5. 세밀한 개선: 어텐션 bias, sink, 라이선스/공개 정책 등
흥미로운 소소한 디테일들도 다루고 있습니다.
- gpt-oss에서는 Attention bias(키, 밸류 프로젝션에 bias)를 GPT-2 이후 오랜만에 도입했으나, 최근 논문은 효과가 거의 없음을 보여줍니다.
- Attention Sink는 긴 맥락에서 특정 정보 보존을 위해 활용하는데, 실제 입력 토큰이 아니라 헤드별로 학습된 bias logit을 attention score에 더하는 방식으로 적용되었습니다.
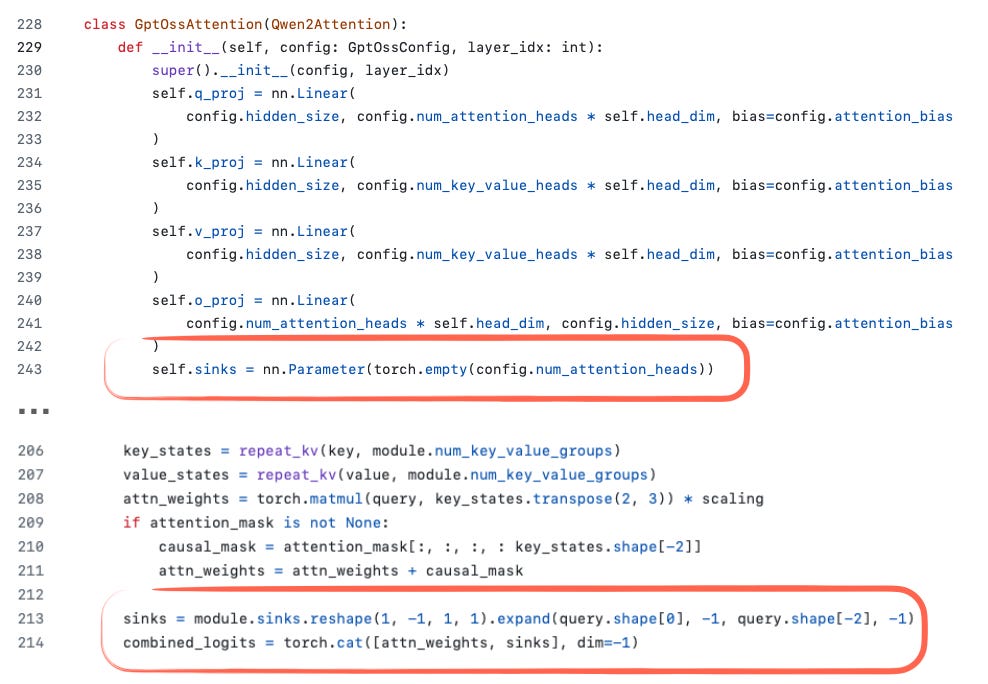
한편, gpt-oss와 Qwen3는 모두 Apache 2.0 라이선스로 (정식 오픈소스는 아니고 오픈웨이트) 사용제약이 없습니다.
"strict한 의미에서 gpt-oss는 오픈웨이트 모델입니다. 즉, 가중치와 추론 코드는 공개되어 있지만, 학습 코드·데이터셋은 공개되지 않았습니다."
6. 훈련과 활용: 고난이도 추론과 MXFP4 최적화
6-1. 훈련 정보 및 구성
gpt-oss 시리즈는 엄청난 계산량(H100기준 210만 GPU-시간)과 최신 원천 데이터(주로 영어, STEM, 코딩, 일반상식)로 학습되었습니다.
"gpt-oss의 훈련량은 DeepSeek V3와 비슷한 수준이나, 정확한 학습 데이터 규모는 비공개입니다."
6-2. Reasoning 스케일 조정
특히 흥미로운 점은 추론 시 "Reasoning effort: low/medium/high" 명령어를 넣어 답변의 길이, 정확도를 직접 조절할 수 있다는 것입니다.
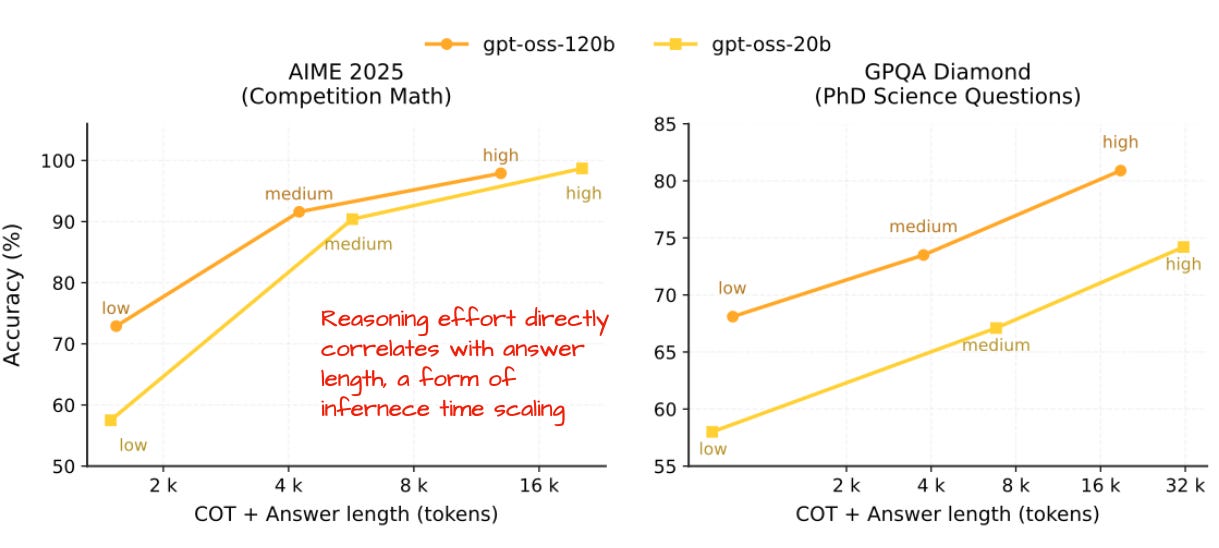
"간단한 지식질문, 오타 수정 등에는 reasoning effort를 낮춰 리소스를 절감할 수 있습니다."
참고로 Qwen3도 이와 유사한 토글이 있었으나 최근 성능 저하 문제로 각 기능을 분리했습니다.
6-3. MXFP4 최적화
초대형 gpt-oss-120b 모델마저도 MXFP4 양자화 최적화 덕분에 단일 80GB H100에서 구동 가능합니다.
- 20B 모델은 최신 RTX 50시리즈 16GB만으로 충분하며, MXFP4 미지원 하드웨어는 메모리 사용량이 큰 폭으로 증가합니다.
- 실제로 Mac mini, ollama 환경에서도 20B 모델이 13.5GB 수준에서 쾌적하게 동작합니다.
7. 성능과 한계: 벤치마크, 사용성, 미래 전망
7-1. 벤치마크와 실제 체감
아직 gpt-oss의 서드파티 벤치마크 결과는 많지 않으나, 자체 발표 및 실제 체험 의견을 보면 상당한 경쟁력(특히 reasoning tasks!)을 보여줍니다.
"몇몇 사용자 평대로, gpt-oss는 헛소리(hallucination) 경향이 다소 있으나, 이는 추론 위주 집중 학습이 기초 지식 기억 일부를 희생해서일 가능성이 높습니다."
오픈웨이트 LLM 트렌드는 외부 툴 연동(검색, 계산 등)과의 접점이 커지면서, 앞으로 '사실 암기보다 추론능력' 우선의 흐름이 가속화될 수 있습니다.
7-2. OpenAI, GPT-5 및 비교
gpt-oss 직후, OpenAI는 GPT-5 발표도 이어갑니다. 특히 흥미로운 것은, 이번 오픈웨이트 공개모델이 자사 고성능 상용모델과도 벤치마크상 근접한 성능을 보인다는 점입니다.
"과장됐다는 평가도 있었지만, 이번 오픈웨이트 모델 릴리즈는 실제로도 충분히 강력하며, 오픈 모델과 상용 모델 간 격차가 크게 줄었음을 보여줍니다."
마치며
GPT-2에서 gpt-oss, 그리고 Qwen3, 최신 GPT-5까지의 아키텍처 발전사는 트랜스포머 기반 LLM이라는 본질을 지키면서, 효율성과 추론능력, 실제 활용도 차원에서 세밀하게 최적화되어온 과정을 보여줍니다. 오픈웨이트 LLM의 시대에는 누구나 고성능 모델을 로컬·클라우드 어디서나 자유롭게 실험하고, 연구 및 응용 개발에 나설 수 있게 되었습니다.
앞으로의 발전도 기대해볼 만하겠죠? 🎉
"지금은 오픈웨이트·로컬 모델로 작업하기에 정말 좋은 시대입니다."
본 문서가 도움되셨다면, 독립 연구를 위한 다양한 지원(저서 구매, 영상 강의, 구독 등)도 확인해보시면 좋겠습니다! 😊