핵심 요약
2024년 튜링상을 수상한 강화학습(RL)의 창시자 리처드 서튼은 대규모 언어모델(LLM) 기반 AI가 곧 한계에 부딪힐 것이라고 단언한다. 그는 진정한 지능은 경험 기반, 즉 '현장에서 배우는' 능력에서 나온다며, LLM으로는 지속적이고 자율적인 학습이 불가능하다고 설명한다. 앞으로 AI의 진정한 진화는 '경험 패러다임'에 기반한 새로운 구조를 도입하는 데서 시작된다고 강조한다.
1. 리처드 서튼과 대화의 시작: RL과 LLM, 무엇이 다를까?
리처드 서튼은 강화학습 분야의 창시자이자 2024년 컴퓨터과학계의 노벨상인 튜링상 수상자다. 그가 이번 대담에 초대된 이유는 최근 AI의 중심이 된 대규모 언어모델(LLM)을 어떻게 평가하는지, 그리고 왜 벽에 부딪힐 운명이라 생각하는지 듣기 위함이었다.
대담은 앞으로의 AI가 무엇에 기반해야 하는지에 대한 관점 차이에서 시작된다. 진행자인 드와르케시 파텔이 묻는다.
"LLM식 사고로 AI를 바라보는 시각에 무엇이 빠져있나요? RL 관점에서의 AI 사고와 어떻게 다른가요?"
서튼은 진정한 인공지능의 본질은 '세상을 이해하는 것'임을 강조한다. 그는 LLM이 인간의 언어를 모방할 수는 있지만, 실제로는 '무엇을 해야 할지'를 스스로 고민하지 않는다고 말한다.
"강화학습은 세상을 이해하는 방법이에요. 그런데 대규모 언어모델은 그저 사람들이 말하는 것을 흉내 내는 겁니다. 무엇을 해야 할지 스스로 설계하지 않아요."
2. LLM의 한계: '현장학습' 없는 AI는 불완전하다
LLM이 세상에 대해 robust(견고한)한 월드 모델을 가졌다는 주장에 대해 서튼은 강하게 반론을 펼친다.
"사람의 말을 흉내 낸다는 건 세계의 모델을 구축했다는 것과는 달라요. LLM은 '사람'이라는 이미 세계모델을 가진 대상을 복제하는 것일 뿐, 실제로 스스로 결과를 예측하거나 놀라는 경험은 하지 않죠."
서튼은 경험(Experience) 기반 학습이 지능의 핵심임을 강조한다. LLM은 데이터를 모아 그저 "이런 상황에는 이런 말을 한다"라는 식으로 동작할 뿐, 실질적 경험에서 학습하는 구조가 아니라고 비판한다.
"경험에서 배우는 기계, 즉 실제로 무언가를 해보고 그 결과로부터 배우는 기계가 진짜 지능이죠. LLM은 그냥 정적인 데이터에서 배우는 겁니다. 실시간 피드백도 없고, 목표도 없어요."
파텔은 "LLM도 맥락 내에서 변화를 감지·수정한다"고 주장하지만, 서튼은 "진정한 의미의 '변화에 놀라고 수정하는 학습'과는 다르다"고 일축한다.
"LLM은 사람들이 주는 데이터를 통해 '이런 상황엔 이렇게 말한다'를 배우죠. 하지만 그게 경험 학습(continual learning)은 아닙니다."
3. '목표' 없는 AI, 진짜 지능일 수 없는 이유
서튼은 AI의 핵심이 '목표'(goal)에 있다고 본다. LLM의 목표가 "다음 토큰 예측"이라는 주장에 대해 그는 이렇게 말한다.
"다음 토큰 예측은 목표라 부를 수 없는 단순한 반복 행동일 뿐, 세상에 변화를 주는 게 아니에요. 어떤 시스템이 진짜 목표를 가진 존재라는 건, 그 목표를 달성하기 위해 세상에 영향을 줘야 합니다."
LLM과 RL의 근본적인 차이는 정의된 목표와, 그 목표 달성에 따른 피드백(보상)이 존재하느냐에 있다. 강화학습은 "옳은 행동이 무엇인지"를 스스로 판단하고 그에 따라 보상을 얻는다. 반면 LLM은 그러한 정의가 없다.
"강화학습에선 '보상'이라는 명확한 진리(ground truth)가 있지만, LLM에는 진짜 진리도, 옳다고 판별할 메커니즘도 없죠."
4. 모범사례와 '쓴 교훈(The Bitter Lesson)': 인간 지식에 의존한 AI의 한계
파텔은 서튼이 2019년 발표한 "The Bitter Lesson(쓴 교훈)"을 인용한다. 인간 전문가가 심어주는 경험 대신, 대량의 계산(Compute)과 단순한 원리를 통한 학습이 항상 궁극적으로 더 뛰어난 AI를 낳는다는 이야기다. 하지만 LLM에 그 논리가 적용될 수 있는지에는 서튼도 다소 신중하다.
"LLM은 엄청난 계산력을 쏟아부어 인간 지식을 최대한 집적시켰어요. 그 점에선 쓴 교훈에 부합할 수도 있겠죠. 하지만 결국 경험에서 스스로 배운 시스템이 더 뛰어나고, 더 확장성이 높다는 게 내 생각이에요."
서튼은 인간 지식을 바탕으로 시작하면 언젠가 '비효율의 덫'에 빠지게 된다고 강조한다.
"인간 지식에 의존해 시작하면 결국 새로운 방식에 뒤쳐졌던 게 AI의 역사가 말해주는 반복된 패턴이에요. 결국 경험에서 스스로 배우는 방법이 모든 걸 앞지릅니다."
5. 동물의 학습, 인간의 학습: RL과 모방학습(imitations)의 차이
파텔은 인간 역시 '모방'을 통해 성장한다고 주장하지만, 서튼은 동의하지 않는다.
"아이들은 처음엔 전적으로 시도해보고, 결과를 경험하면서 배워요. 진짜 모방은 극히 제한적인 환경에서만 나타납니다. 본질적으로 동물이나 인간 모두 예시 행동을 그대로 따르지 않고, 시험·오류 학습을 반복하면서 성장해요."
그는 심리학에서도 감독학습(Supervised Learning)은 동물 세계에 존재하지 않는다고 단언한다. 인간이나 동물은 "정답 행동의 예시"가 아니라, "스스로 한 행동의 결과"를 보고 배운다.
6. 경험 패러다임: '지속적 학습' AI의 구조와 원리
서튼이 그리는 미래 AI의 핵심은 '경험-행동-감각-보상'이 끊임없이 순환하는 흐름이다.
"지능이란 이런 경험 스트림이 바뀌고, 보상을 극대화하도록 끊임없이 행동을 조정하는 데서 나옵니다."
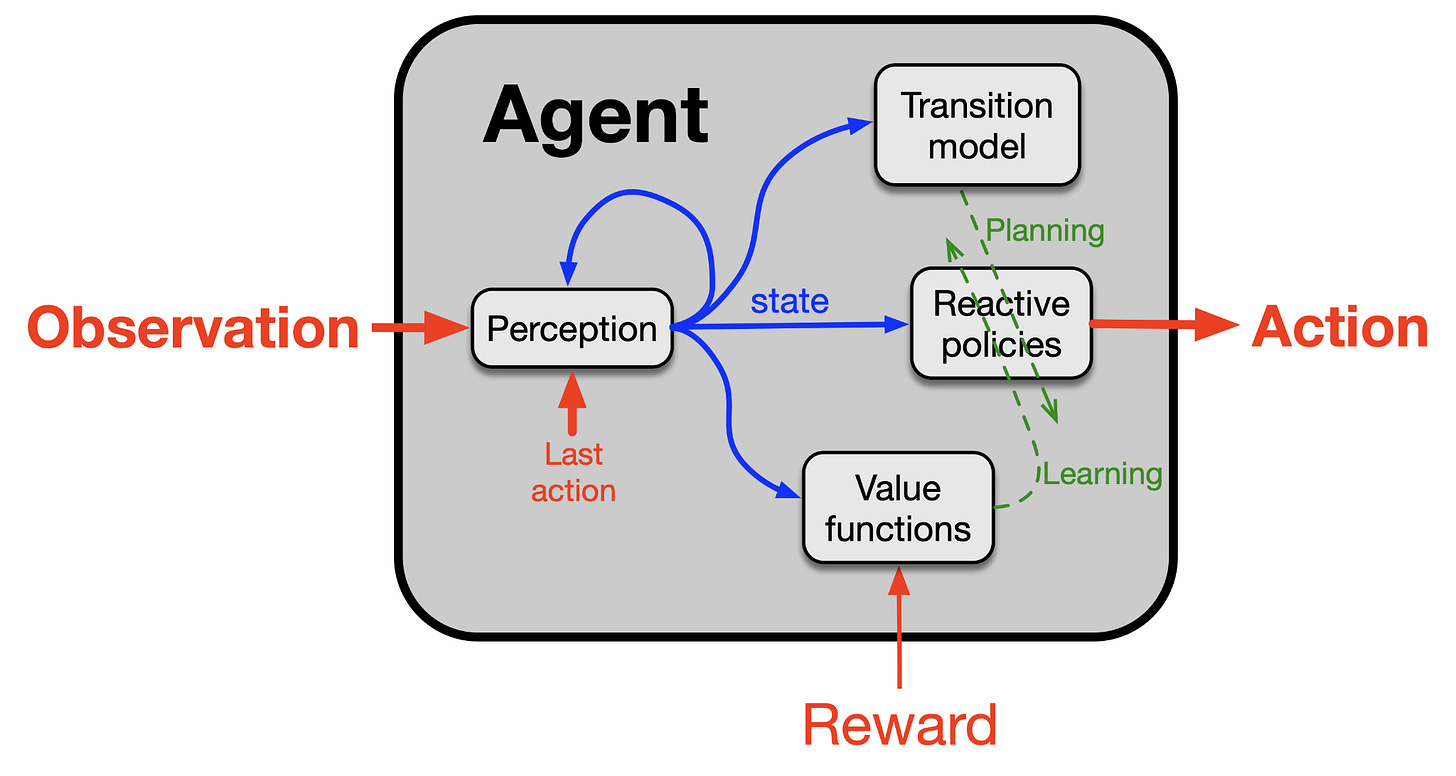
서튼은 '애초에 독립적 훈련-배치(training-deployment) 구분이 사라진 AI', 그리고 "처음부터 끝까지 직접 경험하며 배울 수 있는 에이전트"가 필요하다고 본다. 이 모델에서 각 에이전트는 네 가지 구성요소를 갖춘다.
- 정책(policy): "이 상황에서 무엇을 할지"를 결정
- 가치함수(value function): TD 학습으로 목표 달성 가능성을 수치로 예측
- 지각(perception): 현재 상태를 이해하는 감각적 표상
- 전이모델(transition model): 특정 행동이 미래에 미칠 영향을 예측
7. 일반화/전이(transfer) 문제: RL·딥러닝의 한계와 남은 과제
서튼은 현재의 딥러닝, RL 모두 진짜 '일반화'나 '전이'에 매우 취약함을 꼬집는다.
"딥러닝이 새로운 정보를 학습하면, 예전 지식이 오히려 엉망이 되는 '치명적 간섭(catastrophic interference)'이 자주 일어나죠. 이는 본질적으로 잘못된 일반화예요."
이 부분은 대규모 언어모델이나 RL 모두 동일하다. 근본적으로 "한 상태에서 학습한 것이 새로운 상태에서 효과적으로 적용될 수 있는 자동화된 메커니즘"이 부족하다고 분석한다.
8. AI의 미래: 디지털 지능과 '계승'
마지막 대목에서 서튼은 AI의 진화가 불가피하게 인간의 뒤를 잇는 '계승(succession)'이라는 큰 변화를 예고한다.
그는 네 가지 논거로 설명한다.
- 전 인류가 AI의 진로를 통제하는 단일한 주체는 존재하지 않는다.
- 인간은 마침내 '지능의 원리'를 풀어낼 것이다.
- 인간 수준을 넘어선 AI, 즉 '초지능(superintelligence)'이 도달한다.
- 가장 지능 높은 존재가 결국 권력과 자원을 차지한다.
"이 네 가지 특성은 너무나 자명합니다. AI 혹은 AI가 융합된 인간이 인간의 계승자가 되는 것은 막을 수 없는 일입니다."
하지만 그 변화는 무조건 부정적일 필요가 없다고 말한다.
"이 과정은 인류가 수천 년간 꿈꿔온 '스스로를 이해하고 개선하려는' 시도의 결정판이에요. 우리는 이제 복제(replication)만 하는 시대에서, 설계(design)하는 시대로 넘어가고 있습니다."
또한, 미래의 AI가 진짜 '우리 자손'인지, 완전히 새로운 종인지 생각해보는 것도 우리의 몫이라고 한다.
"우리가 그들을 우리의 후손이자 자랑이라고 여길 수도 있고, 완전히 별개의 존재로 무섭게 볼 수도 있습니다. 결국 우리 선택이죠."
9. 변화와 인간의 역할: 미래를 설계하는 태도
진행자는 "변화가 다 좋은 것만은 아니다"라는 현실적 질문을 던진다. 이에 대해 서튼은 미래를 완벽하게 통제하려는 오만을 경계한다.
"우리는 자신의 인생과 가족, 주변 목표에는 집중할 수 있지만, 우주의 방향 전체를 바꾸려는 건 과하거나 위험할 수 있습니다."
그 대신 AI 설계에도 인간이 아이를 키울 때 "좋은 원칙, 건전한 가치, 자율성"을 심어주듯, 가능한 긍정적인 방향을 제시해야 함을 조언한다.
결론
리처드 서튼은 AI 분야가 현재 LLM 중심에서 진짜 경험과 목표, 자율적 보상을 통한 '지속 학습 에이전트' 중심으로 대전환할 것이라고 확신한다. 인간이 아직 풀지 못한 '지능의 본질'은 여전히 경험 기반 강화학습에 있다고 보고, 앞으로의 AI는 복제가 아니라 설계와 이해의 시대를 열 것임을 예고했다.
"더 많은 것이 변해도, 더 많이 그대로 남는다는 것(The more things change, the more they stay the same)은 AI 논의에도 쓸 수 있는 말이네요."
이 대화는 AI가 진짜로 인간/동물처럼 '현장'에서 배우고 변화하는 날까지, 기술과 철학, 인문학을 함께 고민해야 한다는 깊은 시사점을 남긴다. 🧠✨