
1. What Was Built?
The author initially built a Chrome extension for lawyers on LawTalk (a Korean legal Q&A platform), where AI automatically drafts answers when lawyers write responses. The extension was designed so that lawyers could keep working in their existing workflow while simultaneously using AI auto-completion. A Chrome extension was chosen because it was the least disruptive way to naturally integrate AI into the existing workflow.
"The extension approach was the only way for lawyers to use the AI auto-completion service while working in exactly the same way they always have."
2. System Architecture
The overall system architecture is as follows:
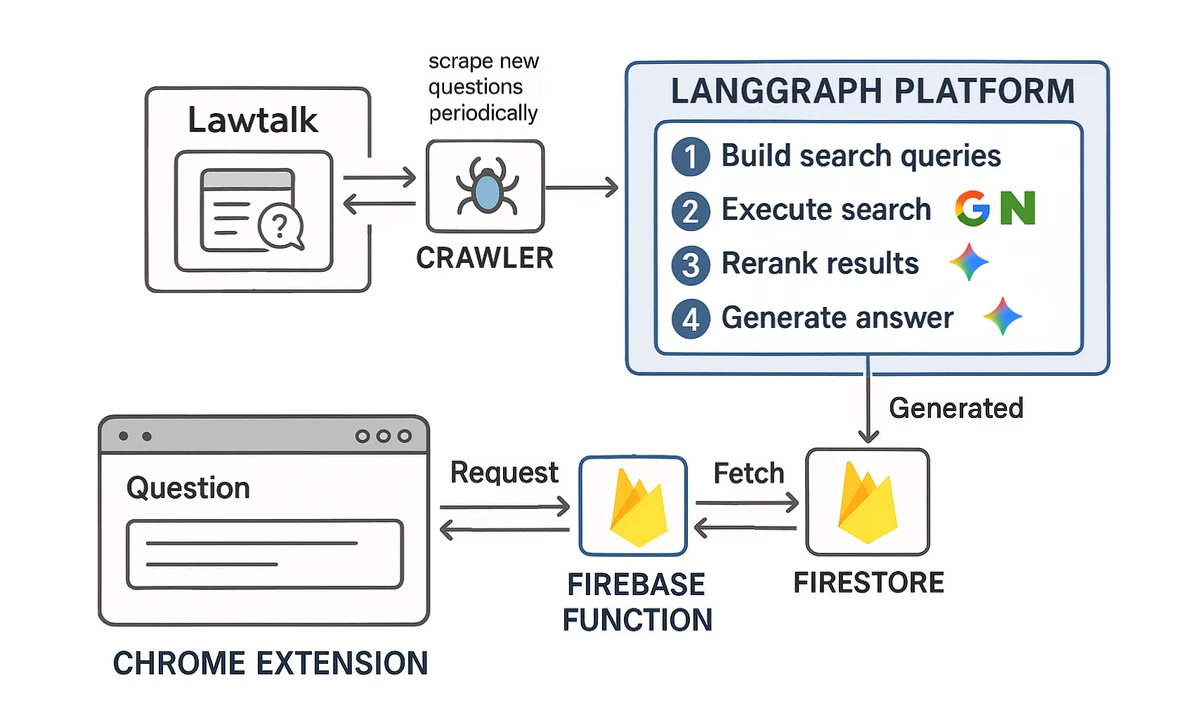
Main Workflow
- When a LawTalk question comes in -> Extract search terms for web search
- Search Google, Naver, etc. with those terms
- Re-rank search results by relevance to the question
- Generate an answer based on the most relevant documents
This approach is similar to web-search-based answer generation services like Perplexity, but with key differences:
- Search term extraction designed specifically for the legal domain
- Leveraging the time gap between when a question is posted and when an answer is written
Legal Domain-Specific Design
- Created a detailed taxonomy covering all legal questions
- The core challenge was accurately organizing the legal issues in a question using precise legal concepts and terminology
"I determined that the essence of this problem (answering legal questions from laypeople) was accurately organizing the legal issues using precise legal concepts and terminology."
- Language models still struggle to precisely identify legal issues using proper legal terminology
- So the system was designed to perform step-by-step issue analysis referencing the taxonomy
"I built an extensive taxonomy covering nearly all topics and issues across all legal fields (civil, criminal, administrative law, etc.) and confirmed that having the language model reference it for step-by-step issue analysis significantly improved results."
3. Tech Stack
Key technologies used in this project:
- LangGraph: Workflow implementation and hosting
- LangChain, LangSmith: Various module usage
- Language models: Google Gemini 2.5 Flash and 2.0 Flash (Korean performance superior to OpenAI)
- Serper, FireCrawl: Google Search API, PDF processing
- Naver Search API: Naver search results
- Google Cloud Scheduler, Cloud Build: Periodic LawTalk question collection and build automation
- Firestore, Firebase Functions: Storing analysis results and serving data
- Frontend: Chrome extension requests data from Firebase Functions
4. Lessons Learned -- A New Perspective on Text Data
The author gained a new perspective on text data through this project.
The Commonality Between Images and Text
In Professor Moon Byung-ro's lecture, the concept that images can be transformed in various ways through matrix multiplication is explained.

- Text data can also be converted to vectors through embedding models
- Multiplying these vectors by matrices enables various transformations (summarization, answering, etc.)
"I learned that all text processing tasks -- taking text as input and producing text as output -- are fundamentally no different from multiplying matrices against images to transform them into desired forms."
Embeddings and Space Transformation
- Perfect embedding vector -> text conversion isn't yet possible
- But the author began viewing text processing as spatial transformations
- This led to experimenting with a mini two-tower model
Extreme Classification and the Mini Two-Tower Model
- Finding the most relevant answer to a question is an Extreme (multi-label) classification problem
- A human approach would be tagging and matching
- This tag transformation can also be viewed as matrix multiplication (spatial transformation)
Two-Tower Model Architecture
- User tower: User information -> embedding vector
- Candidate tower: Recommendation target information -> embedding vector
- Recommendations based on similarity between the two embeddings
Mini Two-Tower Model
- Use OpenAI or Gemini text embedding models to embed questions/answers
- Train only a small model to convert these embeddings into tags
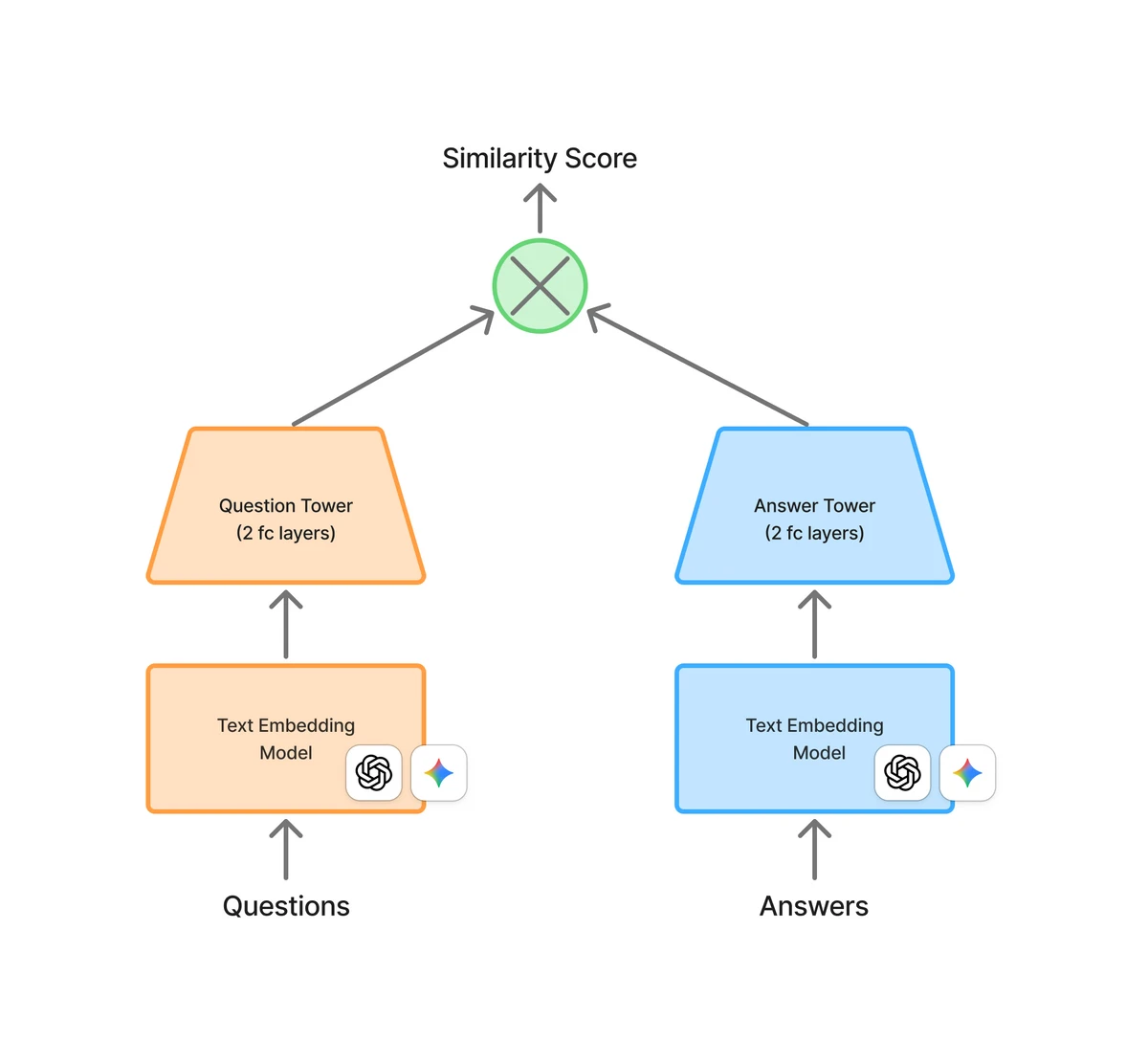
- Experimented with public Q&A datasets
- Both question tower and answer tower use embedding input/output
- Training objective: high embedding similarity for valid Q&A pairs, low similarity for irrelevant pairs
"The training objective was set so that the two models' embedding output similarity would be high for valid Q&A pairs (i.e., real question-answer pairs) and low for invalid pairs (i.e., questions paired with irrelevant answers)."
- However, performance was poor due to overfitting
- Causes: limitations of text embedding model performance, incomplete input data
On The Bitter Lesson
- The task of converting questions to tags ultimately shifted from vector space to language model + taxonomy
- This led the author to encounter Professor Richard S. Sutton's "The Bitter Lesson"
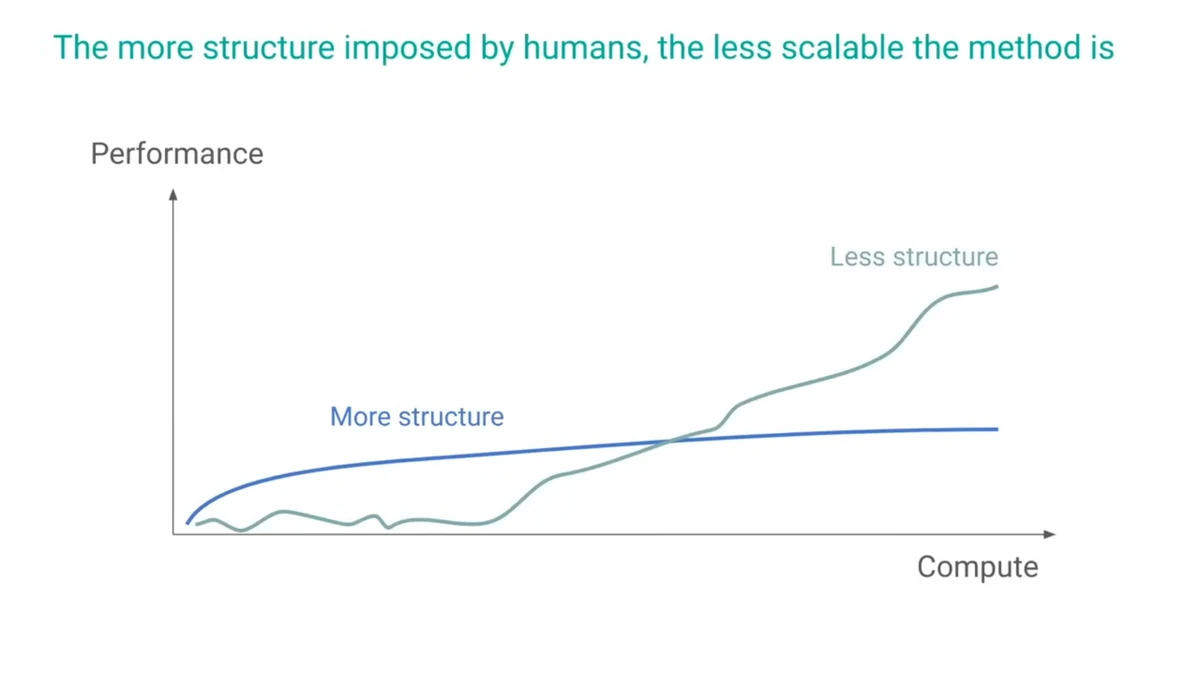
"Encountering Sutton's 'The Bitter Lesson' -- that approaches leveraging human knowledge may yield good short-term results but struggle long-term -- made me reconsider this method."
The Author's Conclusions
- Research and business are different domains
- Using human knowledge and general methods (compute-based) don't necessarily conflict
- The legal domain, unlike math or coding, lacks clearly verifiable correct answers
- Bar exam multiple-choice questions are the kind where if the answer doesn't come in 10 seconds, thinking for 10 minutes won't help
"Bar exam multiple-choice questions are just like that -- if the answer doesn't come to you within 10 seconds, you won't find it even after thinking for 10 minutes."
Idea for Training Legal Reasoning Models
- Extract sentences from legal textbooks -> input them with table of contents to a language model
- Have the model infer which section a sentence came from
- Enables clear correct answers and large training datasets
- Useful for legal domain classification even if full legal problem-solving remains difficult
5. Troubleshooting
The biggest issue was that LangChain's ChatGoogleGenerativeAI class produced errors when generating structured output containing arrays.
- Cause: When receiving streaming response chunks, Google sometimes sends an extra empty chunk at the end
- The LangChain class didn't handle this properly
"I solved the problem by creating a custom ChatModel class inheriting from LangChain's BaseChatModel that properly handles cases where an empty chunk arrives at the end."
6. Helpful Resources
Resources that helped with machine learning studies during the project:
- Professor Lee Joonseok (SNU Data Science Graduate School) YouTube
- Covers L1/L2 regularization, transformer architecture, and more from basics to advanced
- Professor Lee's Channel
- Algorithmic Simplicity
- Explains principles and evolution of deep learning architectures (CNN, RNN, transformers)
- CNN Video
- Welch Labs
- Covers fascinating topics like mechanistic interpretability
- Mechanistic Interpretability Video
Conclusion
This project -- building AI auto-completion specialized for the legal domain -- provided diverse lessons:
- A new perspective on the nature of text data
- Model design and limitations
- Troubleshooting in real-world service implementation
- Balancing research and business
"Viewing text processing as fundamentally a spatial transformation led me to experiment with a mini two-tower model, a slight variation on the two-tower architecture."
"The domains of research and business are different. Leveraging human knowledge for performance improvement and throwing compute at problems with general methods are not necessarily in conflict."
Key Concepts:
- LawTalk, Chrome extension, AI auto-completion, legal domain, search term extraction, taxonomy, embeddings, two-tower model, The Bitter Lesson, troubleshooting, machine learning resources