
This post summarizes research comparing two approaches for teaching coding agents framework-specific knowledge — skills and AGENTS.md. Through evaluations focused on Next.js 16 APIs, the team found that a compressed 8KB document index embedded directly in AGENTS.md achieved a 100% pass rate, significantly outperforming skills. This result suggests that passive context may be more effective than agents actively retrieving information on their own.
1. The Problem to Solve
AI coding agents face the problem of training data becoming outdated. In 2026, APIs newly introduced in Next.js 16 like 'use cache', connection(), and forbidden() aren't in existing model training data, causing agents to generate incorrect code or revert to old patterns. Conversely, projects using older Next.js versions see models suggesting the latest APIs. The Vercel team wanted to provide agents with version-appropriate documentation.
2. Two Approaches to Teaching Framework Knowledge
The Vercel team tested two methods:
- Skills: Open standard domain knowledge packages that agents can invoke when needed. When an agent determines it needs framework help, it calls a skill to access relevant documentation. Expected benefits: clear separation of concerns and minimal context overhead.
AGENTS.md: A markdown file at the project root providing persistent context to coding agents. Its contents are available to the agent every turn without the agent deciding whether to load information. Claude Code usesCLAUDE.mdfor a similar purpose.
3. Initial Expectations and Disappointing Results with Skills
Skills initially seemed ideal. Package framework docs as skills, and agents would invoke them for Next.js tasks, reading version-matched documentation to generate correct code.
But evaluation results told a different story.
3.1. Skills Didn't Trigger Reliably
In 56% of evaluation cases, skills were never invoked. The agent had access to documentation but didn't use it. Adding skills showed zero improvement over the baseline (no documentation).
| Configuration | Pass Rate | vs. Baseline |
|---|---|---|
| Baseline (no docs) | 53% | — |
| Skills (default behavior) | 53% | +0pp |
In some cases, test metrics were lower than the baseline, suggesting unused skills may introduce noise or distraction.
3.2. Explicit Instructions Helped, But Phrasing Was Fragile
Adding explicit instructions in AGENTS.md to tell the agent to use skills boosted the skill invocation rate to 95%+ and pass rate to 79%.
| Configuration | Pass Rate | vs. Baseline |
|---|---|---|
| Baseline (no docs) | 53% | — |
| Skills (default behavior) | 53% | +0pp |
| Skills with explicit instructions | 79% | +26pp |
However, subtle wording differences had enormous impact on agent behavior. "You MUST invoke the skill" led agents to read docs first and miss project context. "Explore project first, then invoke skill" produced better results. This fragility made it unsuitable for production.
4. Building Reliable Evaluations
Before drawing conclusions, the team needed reliable evaluation tools. The initial test suite had issues: ambiguous prompts, tests verifying implementation details, and focus on APIs already in training data. They strengthened the evaluation suite with behavior-based assertions and tests targeting Next.js 16 APIs not in training data, including connection(), 'use cache', cacheLife(), cacheTag(), forbidden(), unauthorized(), proxy.ts, async cookies() and headers(), after(), updateTag(), and refresh().
5. The Unexpected Result: AGENTS.md Wins
The team tried embedding the document index directly in AGENTS.md — not full documentation but an index pointing to version-specific doc files. A key instruction was added:
IMPORTANT: Prefer retrieval-led reasoning over pre-training-led reasoning for any Next.js tasks.
Final Pass Rates
| Configuration | Pass Rate | vs. Baseline |
|---|---|---|
| Baseline (no docs) | 53% | — |
| Skills (default behavior) | 53% | +0pp |
| Skills (with explicit instructions) | 79% | +26pp |
AGENTS.md document index | 100% | +47pp |
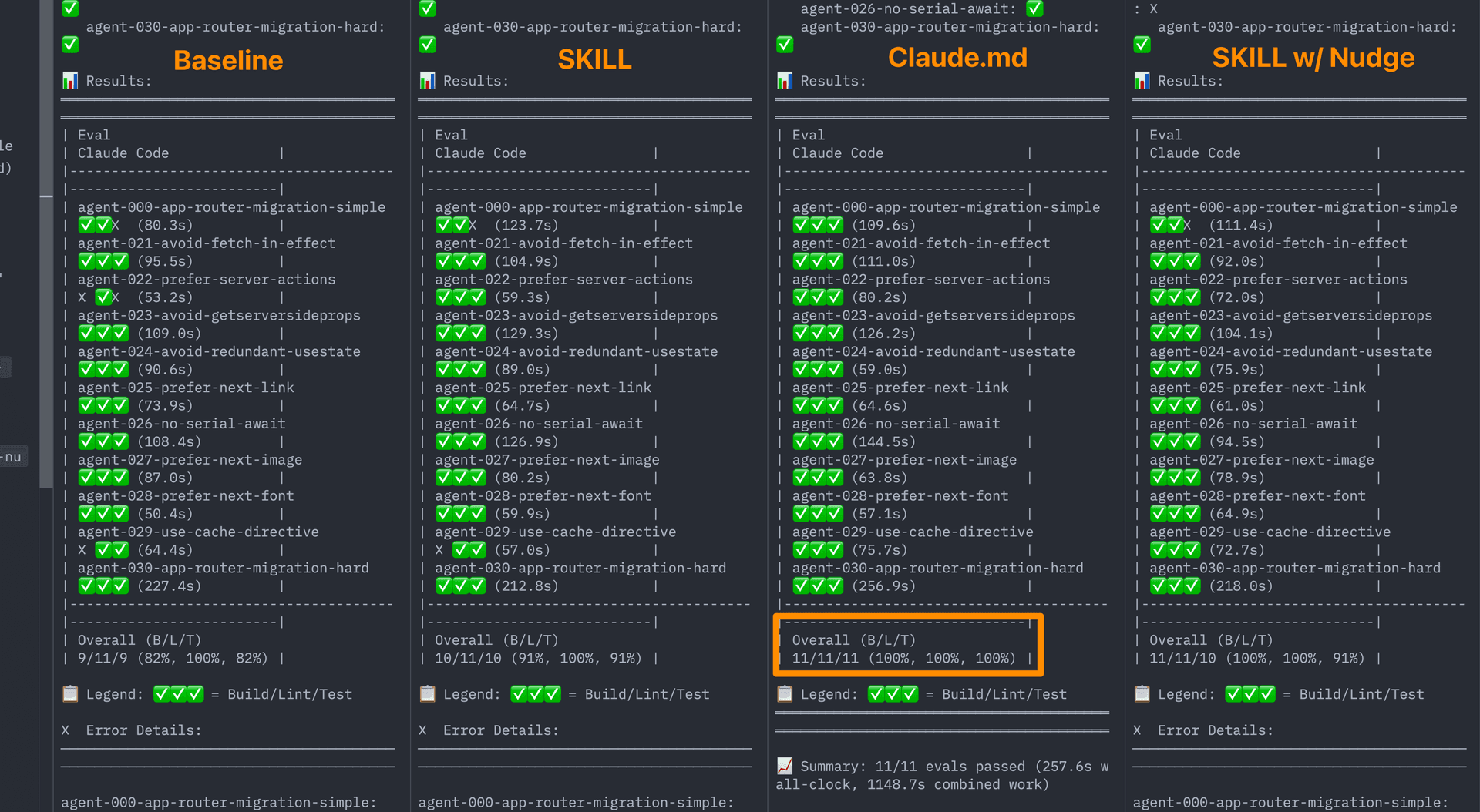
The "dumb" approach (a static markdown file) dramatically outperformed skill-based retrieval. AGENTS.md achieved perfect scores across build, lint, and test.
Why Does Passive Context Beat Active Retrieval?
Three factors:
- No decision points: The agent never needs to decide "should I look this up?" — information is already there.
- Consistent availability: Skills load asynchronously and only when called; AGENTS.md content is included in the system prompt every turn.
- No sequencing issues: Skills require decisions about order (read docs first or explore project first?); passive context avoids this entirely.
6. Solving Context Bloat
Embedding docs in AGENTS.md risks bloating the context window. The team solved this through compression — reducing from ~40KB to 8KB (80% reduction) while maintaining 100% pass rate. The compressed format uses pipe-delimited structures to pack the document index into minimal space.

7. Try It Yourself
Run this command in any Next.js project:
npx @next/codemod@canary agents-md
It detects your Next.js version, downloads version-matched docs to .next-docs/, and inserts the compressed index into AGENTS.md.
8. Implications for Framework Developers
Skills aren't useless. AGENTS.md provides broad, horizontal improvement across all agent-Next.js interactions. Skills work better for vertical, action-oriented workflows like "upgrade Next.js version" or "migrate to App Router." The two approaches are complementary.
But for general framework knowledge, passive context currently outperforms on-demand retrieval. If you maintain a framework and want coding agents to generate correct code, consider providing AGENTS.md snippets users can add to their projects.
Practical recommendations:
- Don't wait for skills to improve. Results matter now.
- Compress aggressively. An index pointing to searchable files is sufficient.
- Test with evals. Build evaluations targeting APIs outside training data.
- Design for retrieval. Structure docs so agents can find and read specific files rather than needing everything upfront.
The goal is shifting agents from pre-training-led reasoning to retrieval-led reasoning. AGENTS.md has proven to be the most reliable way to achieve this currently.
Conclusion
Vercel's research clearly shows that for providing framework knowledge to coding agents, passive context approaches like AGENTS.md are currently far more effective than active retrieval approaches like skills. By eliminating the agent's decision-making process about whether to retrieve information and enabling constant access to relevant knowledge, it significantly improves accessibility to the latest APIs and version-specific information. Framework developers should reconsider their documentation delivery approaches based on these findings.