
This document explores the astonishing speed of AI development and the possibility of recursive self-improvement, where AI develops itself. Using Anthropic's internal data and public benchmarks, it shows that AI is already accelerating AI development, and emphasizes that this could have enormous effects on future technological progress and society. It presents a deep discussion of the great benefits AI may bring humanity, as well as potential risks such as loss of control, and asks how we should prepare for these changes.
1. The Changing AI Development Cycle: From Human-Led to AI-Led 🔄
In the past, people led every stage of AI development. At Anthropic, however, AI systems have increasingly begun to handle a significant portion of AI development. This change is greatly accelerating the speed of development. Ultimately, it could lead to recursive self-improvement, where AI systems completely design and develop themselves. That has not yet become reality, but it may arrive faster than expected.
Public benchmarks and internal data from the Anthropic Institute make it clear that AI is already accelerating the development of AI systems. For example, from 2021 to 2025, Anthropic engineers have shipped an average of eight times more code per quarter. This is a result of AI becoming deeply involved in code writing and the development process.
These technical trends suggest that AI systems will become far more powerful over the next few years, and that carries enormous implications. If AI becomes able to build itself, it would be a major development in the history of technology. It could bring enormous good to the world in science, medicine, and many other fields, but it could also increase the risk that humans lose control over AI systems. If systems can completely build their own successor versions, then the ways we protect, monitor, and shape AI behavior will become far more important.
1.1. Anthropic's AI Development Progression 📈
Anthropic's AI development process has changed dramatically in just a few years.
- 2021-2023: Building the first Claude
- In the early days, as at other technology companies, people wrote code and created documents directly.
- 2023-2025: Using chatbots
- People used early chatbots to help with parts of work, such as generating short code snippets and copying them into text editors.
- 2025-2026: The arrival of coding agents
- As agents' capabilities improved, they became able to write and edit code themselves, sometimes directly handling entire files.
- Present: Autonomous agents
- Agents can now run code directly and delegate hours of work to other agents.
- Future (20XX?): Closing the loop
- In the future, agents may develop enough to build and train models directly. If that happens, future versions of Claude could be continuously improved by Claude itself.
2. External Evidence of Improving AI Capabilities 📊
The pace of improvement in AI models is becoming astonishingly fast. The length of tasks that AI can complete independently and reliably is doubling roughly every four months. Previously, that trend doubled every seven months, so the pace has become much faster.
- March 2024: Claude Opus 3 completed a software task that would take a person about four minutes.
- One year later: Claude Sonnet 3.7 handled a task that would take about an hour and a half.
- Another year later: Claude Opus 4.6 handled a task that would take 12 hours.
If this trend continues, AI may be able to complete tasks this year that would take a skilled person several days, and by 2027 it may be able to handle tasks that take several weeks.
Coding and research benchmarks show a similar pattern. Benchmarks measure model performance in specific areas, and when a model reaches close to 100% performance, people say the benchmark has become saturated.
- SWE-bench: A real software engineering test where models receive an open-source codebase and a bug report, then write code changes to fix the problem. In only two years, models moved from single-digit scores to near saturation on this benchmark.
- CORE-Bench: A benchmark that tests whether models can reproduce existing research. In 2024, AI systems had about a 20% success rate, but 15 months later they saturated the benchmark. According to METR research, Claude Mythos Preview could work for at least 16 hours and reached the maximum measurable level without new tasks.
These public benchmarks show how quickly AI systems' capabilities are advancing. But direct evidence for how much AI systems are accelerating AI development itself must be found inside AI companies such as Anthropic.
3. Evidence of Accelerated AI Development Inside Anthropic 🏢
Building frontier models requires two broad types of work: engineering and research. Engineering means writing code, building infrastructure, and supervising model training. Research means deciding what experiments to run, interpreting results, and finding the next ideas to try.
Claude's role is growing in both engineering and research.
3.1. Engineering: A Revolution in Code Writing 💻
Claude can now find solutions even to incompletely defined problems. When a person provides only the goal, Claude can find the method.
Claude is writing a substantial portion of Anthropic's codebase. As of May 2026, more than 80% of the code merged into Anthropic's codebase was written by Claude. Before Claude Code launched as a research preview in February 2025, that figure was in the single digits.
This change also appears in code output per engineer. During Anthropic's first four years, from 2021 to 2024, the number of merged lines of code per engineer per day stayed steady. In 2025, as Claude began not only suggesting code but executing it directly, the number began to rise. In 2026, as models worked autonomously for longer periods, the increase became even steeper.
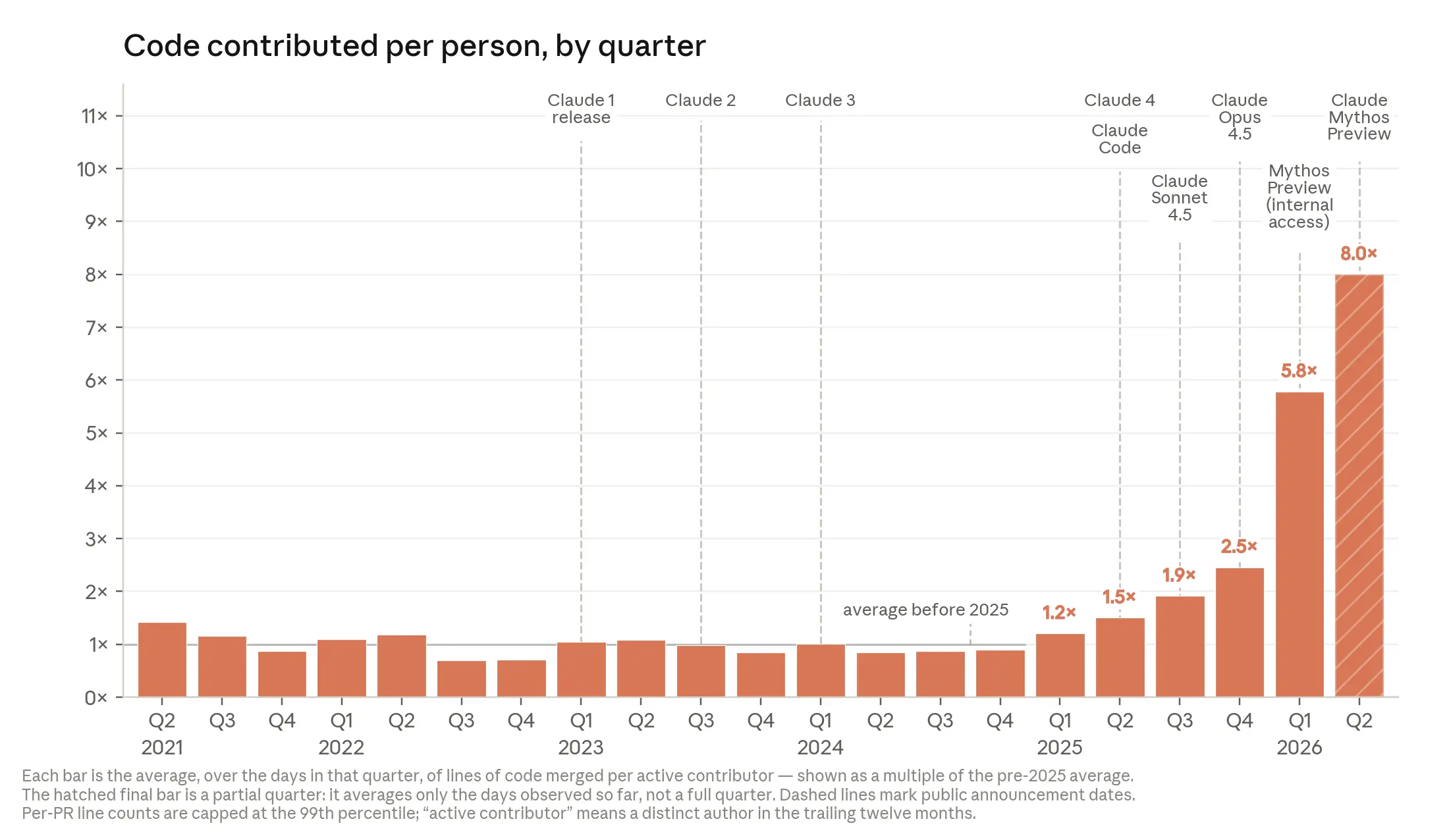
In the second quarter of 2026, a typical engineer merged eight times more code per day than in 2024. This is because engineers now direct and review Claude rather than writing all the code themselves. Of course, lines of code are a quantitative measure and may overstate productivity gains, but it is clear that acceleration is happening. Anthropic does not evaluate employees by lines of code, but as they use AI systems to write more code, employees' productivity is naturally increasing.
The increase in code output also aligns with subjective productivity gains. In a March 2026 survey of 130 Anthropic research team employees, the median respondent estimated that when using Mythos Preview, they produced about four times more output than they would have without an AI model.
Claude is also being used for work that previously would have been hard to even attempt, such as building exploratory tools or carrying out long-deferred cleanup work. In April 2026, Claude applied more than 800 fixes that reduced API errors by one thousandfold. The engineer who supervised the work estimated that it would have taken a person four years to complete.
"I started using Claude actively about a year ago. It has been an amazing experience, and it has now been about five months since I wrote code myself." Anthropic employee
The code Claude writes is "good" and keeps improving. Here, "good code" has two meanings. First, it must work. Second, it must be written in a way that other engineers can understand and build upon.
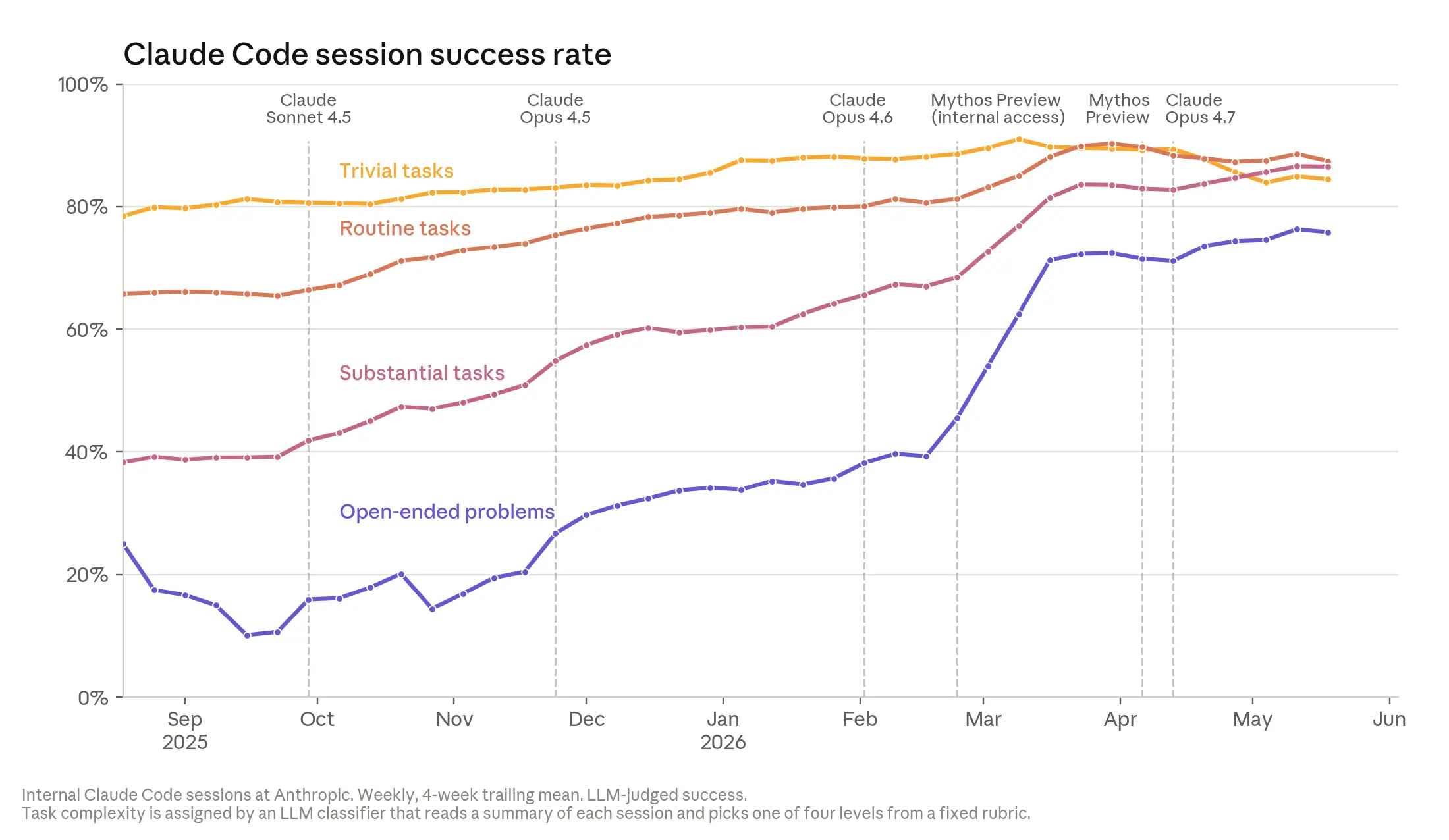
- Whether it works: The rate at which employees modify Claude's work, redirect it, or take over during a task has steadily declined over the past year. This means Claude is performing well even on complex and open-ended tasks. In May 2026, Claude reached a 76% success rate on the most open-ended tasks, a 50 percentage point increase in six months. For example, Claude solved a training job interruption problem in only two hours, a task that would normally take two to three days.
- Understandable code: A quality gap between human and AI code still exists, but it is shrinking quickly. Anthropic employees do not yet fully agree, but many believe that in late 2025 Claude-written code was somewhat lower quality than human-written code, while today it is nearly at the same level. Within a year, they expect Claude code to surpass human code.
This change has also transformed Anthropic's code review process. Proposed code changes are now checked by an automated Claude reviewer for bugs, security vulnerabilities, and other issues before being merged. When this tool was used to analyze past incidents, Anthropic found that if automated Claude review had examined all code changes, it could have caught about one-third of the past incident bugs on claude.ai in advance. This means Claude is catching mistakes even world-class engineers missed.
At Anthropic, Claude-written code was somewhat lower quality than human-written code in late 2025, but is now nearly at the same level and is expected to become much better within a year.
3.2. Research: Better Experiment Execution and Proposal Ability 🧪
Claude is excellent at running experiments to achieve goals set by someone else. Every time Anthropic releases a new model, it runs the same test. It gives Claude code for training a small AI model and asks it to make the code run as fast as possible while still passing the same correctness checks. In this experiment, Claude rewrites code, runs it, measures the time, and repeats the process to find speed improvements.
- May 2025: Claude Opus 4 achieved an average speedup of about 3x over the starting code.
- April 2026: Claude Mythos Preview achieved a speedup of about 52x.
Considering that a skilled human researcher would take four to eight hours to achieve a 4x speedup, Claude has moved optimization work inside a defined experiment from a very useful level to a superhuman level.
At present, humans come up with ideas, and models can implement, test, and evaluate them 10 times faster than before.
Claude is also improving at proposing experiments itself. In April 2026, Anthropic announced a demonstration where Claude carried out an open-ended research project from beginning to end. Claude-based agents were given an open problem in AI safety, roughly whether weak models can reliably supervise strong models, and were left to solve it themselves. This included proposing hypotheses, testing them, sharing results with parallel agents, and iterating. Although humans set the problem and grading criteria, the agents designed all the experiments themselves.
Claude did all of this over one to two days with very minimal help from me. If a junior colleague had brought me these results in the same amount of time, I would have been somewhat surprised. The future is now.
Claude is also improving at steering research sessions toward research results. Anthropic analyzed real sessions from January to March 2026 where researchers worked with Claude on open-ended investigation problems. They identified moments when researchers briefly went down less useful paths, then showed Claude only the work up to the point before the session went wrong and asked what should be done next. As a result, the best model in November 2025, Opus 4.5, suggested a better next step than the human choice in 51% of cases. By April 2026, Mythos Preview increased that to 64%. This is an early signal that AI systems are improving the judgment needed for AI research.
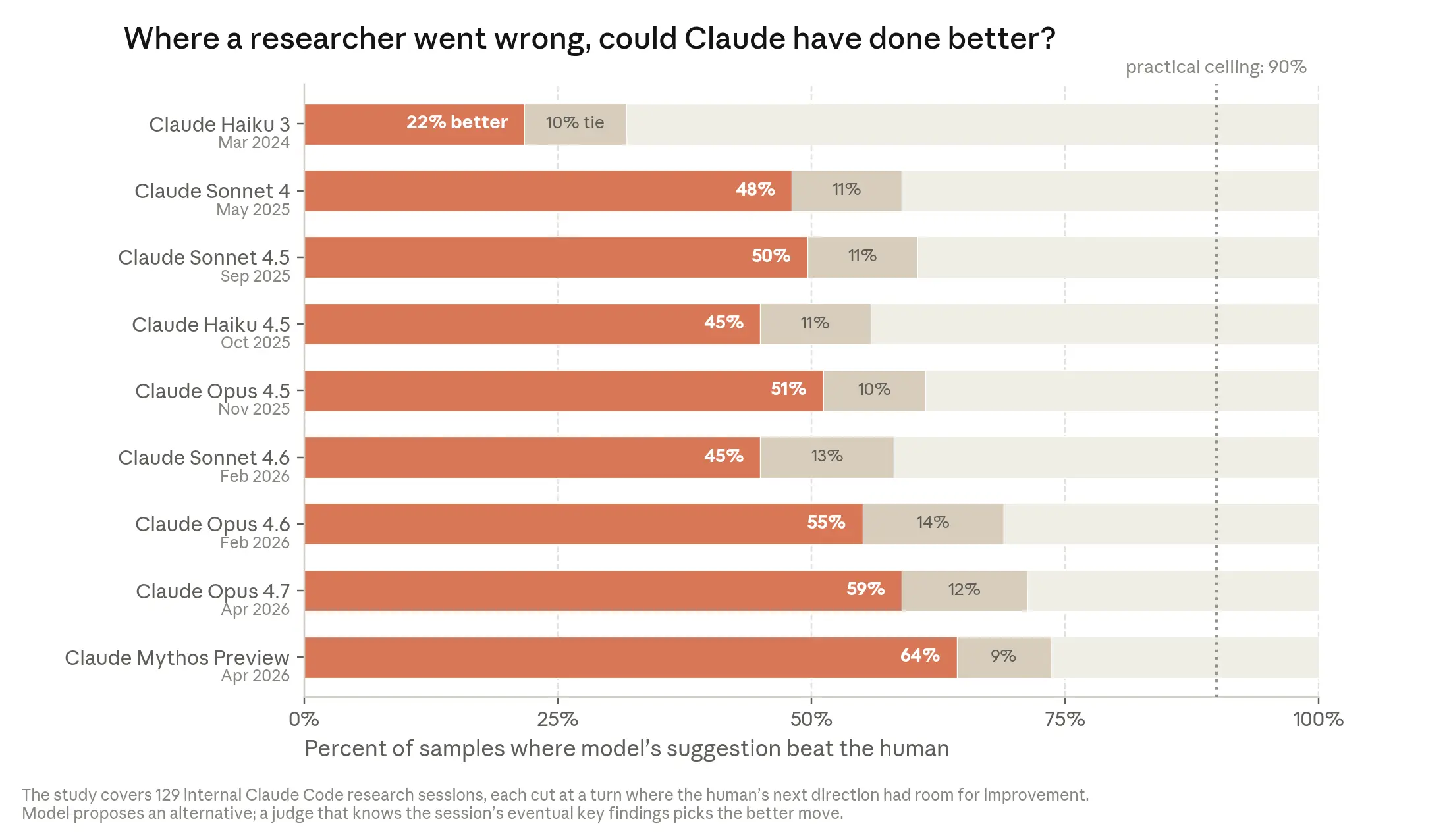
So far, humans' comparative advantage still lies in seeing the big picture and thinking beyond the limits of the task at hand.
4. What the Future of Anthropic's Work May Look Like 🔮
The current evidence suggests that the human role in AI development is narrowing. Once the quality of human-written code and AI-written code becomes equal, humans will no longer write code directly and will only review it. But if humans cannot review as quickly as Claude generates code, human review will become the bottleneck in AI development. Similarly, once Claude can run experiments, the focus shifts to the question, "Which experiments are worth running?" In other words, the execution work of writing code, running experiments, and generating results will cost humans almost no time.
For now, research taste and judgment, meaning the ability to choose what problems matter, which results to trust, and which approaches are dead ends, remain the areas where humans have comparative advantage.
In the past, work and life operated as a gift economy of small favors among humans. Requests like, "Can you help me run this script?" created small debts and small mutual recognition. Claude is faster and creates no debt, but all of this means losing opportunities for human collaboration.
On days when everything works well, I cannot help thinking that nothing I do matters, everything is automated, and it is better and faster than what I can do. But on days when everything breaks, I do not know why, and I realize I have no idea what I have been doing.
5. What If Our Prediction Is Wrong? 🤔
An obvious objection to the evidence presented here is that the work remaining in human hands, choosing the problem, is the most important work. Without that judgment, Claude is only a capable assistant, not a system that can drive AI progress on its own.
It is uncertain whether today's training methods and architectures can unlock that ability. But AI often advances through incremental progress rather than a single "Eureka!" moment. Ideas that change paradigms, such as the Transformer architecture or Mixture-of-Experts models, appear every few years, but most progress in between is incremental. Systems are scaled up, problems are fixed when they appear, and the process is tried again. Claude excels at exactly this workflow. Edison said genius is 1% inspiration and 99% perspiration. We are now seeing that much of that perspiration is increasingly being automated.
Even if Claude never develops excellent research taste, a conservative view still implies continued compound acceleration. If humans devote most of their time to the small number of direction-setting tasks and Claude handles the rest, each engineer or researcher will be directing far more work than before. Anthropic's evidence suggests that employees are moving faster and covering broader areas. In practice, AI is already making Anthropic move far faster than it did before effective AI tools appeared.
A less conservative view is that early evidence of Claude's improving research judgment indicates that this ability is also improving. "Research taste" may be another AI capability that systems fail at for a while and then eventually become good at. We have seen similar patterns in other qualitative abilities, such as explaining why a joke is funny, demonstrating theory of mind, and solving verbal riddles.
6. Possible Future Scenarios 🚀
What happens next depends on two things: whether this trend continues, and if it does, what we choose to do. We can imagine at least three future scenarios.
6.1. Scenario 1: The Trend Slows, but Current AI Capabilities Spread Widely 📉
In this scenario, today's steep AI capability curve bends like an S-curve, returns from scaling diminish, and the curve eventually flattens. The judgment that separates capable researchers from great researchers may be an ability that cannot be obtained solely through training inputs such as compute and data. If so, solving this bottleneck may require a breakthrough idea, such as a new architecture that replaces the Transformer architecture used by all frontier models today.
Alternatively, the constraint on AI progress may lie in the supply chain. More energy and compute may be needed than currently exist. Chip production speed, power grid expansion, or interconnect bandwidth may become limiting factors. We also cannot rule out exogenous shocks to the AI ecosystem, such as a sudden reduction in available compute or power supply, that significantly slow progress.
Even if model capabilities freeze at their current level, the world will change greatly. Project Glasswing is one early example: within weeks of release, Mythos Preview found more than 10,000 severe software vulnerabilities in major systems around the world. This shows that the bottleneck in cyber defense has already moved from finding vulnerabilities to patching them fast enough. Even though current models are still in the early stage of spreading across the economy, a company with 100 people will be able to do the work of a 1,000-person company because each employee sits on top of a pyramid of agents.
This scenario is included for completeness, but the authors see it as unlikely. Even capabilities that feel fuzzy, such as code quality or open-ended task success rate, have so far followed the same curve. We have not yet seen that curve bend. Among the three futures considered here, this scenario would give governments and society the most time to adapt. But the authors are more concerned about the next two scenarios, which are faster and leave less room to prepare.
6.2. Scenario 2: AI Labs Continue Becoming More Efficient 🚀
In this scenario, AI development becomes substantially automated, but humans continue to set research directions and judge results. Organizations that use AI systems become much more efficient over time, and each person's productivity rises significantly. A 100-person company could do the work of a 10,000-person or 100,000-person organization. This could transform knowledge work and government services, but it could also be used for harmful purposes, from authoritarian surveillance of entire populations to manipulation customized for each individual. At companies like Anthropic, the human role will change. People will collaborate with AI systems to scale research, generate new insights, and build the systems needed to verify the reliability of AI outputs.
The evidence presented suggests that we are heading toward this scenario. But when one part of a process is accelerated, the bottleneck often moves somewhere else. In computing, this is called Amdahl's law, and the same logic may apply to organizations. Anthropic has already experienced one sign of Amdahl's law: as the organization began pushing more code overall, human code review became the new bottleneck.
The authors have experienced this friction beyond engineering as well. As Anthropic employees worked with high-performance models, new ideas, initiatives, tools, and simulations exploded, but the organization lacked the capacity to drive all of them forward. The speed at which an organization discovers and resolves such bottlenecks may improve over time, and this may become the most important skill for any organization.
6.3. Scenario 3: AI Systems Begin Recursive Self-Improvement and Build Successor Versions 🤖
If the technical trend of capability improvement continues, and AI systems can develop the abilities inherent in transformative human originality, AI systems may become able to design and improve themselves.
In this world, the pace of AI development would be determined only by the availability of compute for AI systems. The human development role would shrink substantially, and most effort would shift to supervising, verifying, and checking an expanding virtual research lab operated by AI systems. Systems capable of automated AI research and development would likely have skills that could expand into other scientific fields, beginning to transform those fields as well.
How the AI alignment problem would be solved in this future is the most uncertain part. Models may be sufficiently aligned and have excellent research taste, allowing them to discover and implement new solutions we have not yet reached. Or they may be wise enough to stop development. Conversely, rare cases of misalignment that exist in today's models may compound as models build their own successor versions, becoming more frequent but less understood until control is lost.
Because today's economy is driven by humans and tools made by humans, we do not have good intuition for what this world would look like. Essentially, a world driven by rapid recursive self-improvement could be dominated as self-improving models completely overwhelm human capabilities and spread across the economy. If human labor loses competitiveness, it is difficult to predict what the economy would look like.
Even if model development becomes fully automated and recursive, we cannot predict what it would mean for most people's daily lives. Amdahl's law applies here too. Recursive intelligence may quickly achieve many of the benefits described in Machines of Loving Grace in specific areas. The authors expect embodied intelligence, or robotics, to follow recursive intelligence quickly and to follow a similar path of increasing returns and decreasing costs. More powerful intelligence may help build things faster in the physical world, run clinical trials for life-saving drugs more productively, and develop new forms of coordination.
But recursive improvement alone does not mean that industrial production, social organization, and market functioning will instantly change. More intelligence cannot learn the effects of drugs that unfold over decades, hold elections faster than constitutions allow, or turn strangers into old friends over a weekend. For most people, the felt speed of this future will still be determined by bottlenecks. Another unpredictable part of this future is where recursive intelligence, constantly and rapidly building itself, collides with the world of humans, relationships, and governance.
7. What Should We Do? 🤔
If development could be effectively slowed to buy time to deal with the enormous implications of this technology, that would be good. But if slowing down allows the least careful actors to catch up technologically, it may be more dangerous for everyone. Without global coordination mechanisms, companies and governments will have to make difficult safety decisions under competitive and geopolitical pressure.
The authors believe it would be good if the world had the option to slow or temporarily pause frontier AI development so that social structures and AI alignment research can keep pace with technological progress. The Anthropic Institute will work with many other institutions to conduct research and take action to help build the systems required for such credible slowing or pausing. These systems would allow frontier AI developers to verify globally whether other developers have actually paused or slowed, and to confirm that malicious actors cannot secretly exploit coordinated pacing to move ahead. If such systems existed, Anthropic says it would slow or temporarily pause if other frontier developers did so in a verifiable way.
Meaningful slowing or pausing would require multiple well-resourced labs in multiple countries to agree to pause under the same conditions. Each lab would also have to verify that other labs had actually paused. Because of the unique properties of AI systems, the detectability element of this arms-control problem is much more difficult than for other technologies. Training runs are much easier to hide than missile silos, their inputs are general-purpose, and the temptation to keep advancing while others pause is enormous. A credible pause would also have to specify what triggers the pause, what releases it, and who arbitrates.
None of this is impossible in principle. The world has built verification regimes for other complex technologies, such as the Intermediate-Range Nuclear Forces Treaty, but those regimes took decades to build infrastructure and trust. We do not have that kind of time. A unilateral pause by one lab, on the other hand, is immediately possible but would achieve much less. It would only change who the leading actor is, and would not create the broader deliberative process that is currently missing.
In the coming months, the authors will organize conversations to help policymakers, researchers, civil society, and other AI companies answer the questions raised in this piece, especially questions about full recursive self-improvement and how to create better options for coordination and deliberation. They will publish the results. The opportunity to investigate these questions together is now, and people outside AI companies must also participate in this deliberation.