This summary covers ARE (Agents Research Environments), a research platform developed by Meta Superintelligence Labs, and the agent performance measurement benchmark Gaia2 built on top of it. ARE supports integration of real applications and agent orchestration execution, enabling the construction of complex and diverse environments. Gaia2 is designed to go beyond existing benchmarks and measure general agent capabilities in mobile environments, including ambiguity and noise handling, dynamic environment adaptation, collaboration with other agents, and operation under time constraints. This research demonstrates that no current system dominates across the full intelligence spectrum, that stronger reasoning leads to efficiency degradation and budget scaling curves plateau, highlighting the need for new architectures and adaptive computing strategies.
1. ARE: A Research Platform for Agent Development and Evaluation
Meta Agents Research Environments (ARE) is a research platform for scalable environment creation, integration of virtual or real applications, and agent orchestration execution. ARE aims to bridge the gap between model development and real-world deployment by providing simple abstractions for building complex and diverse environments with different rules, tools, content, and verification mechanisms.
ARE presents a promising path toward continuous model improvement and ultimately superintelligence by scaling large language model (LLM) training through reinforcement learning (RL). In particular, Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a more scalable alternative to relying on reward models in environments such as reasoning, coding, agent tool use, and even chatbots. However, existing environments had limitations in evaluation reproducibility and reflected idealized models divorced from actual deployment conditions.
ARE provides the following capabilities to address these issues:
- Facilitating diverse environment and task creation: Through abstractions for simulation and verification, it eases integration of existing environments like tau-bench.
- Supporting asynchronous interactions: It supports the transition from sequential to asynchronous interactions between agents and environments, enabling new tasks and capabilities such as time handling.
While ARE is a simulation environment, it supports connection to real apps through Model Context Protocol (MCP) integration, maintaining consistency across model development, evaluation, and production deployment. Beyond RL, it also enables generation of high-quality SFT (supervised fine-tuning) traces.
2. Core Components and Operation of ARE
ARE is an event-based and time-driven simulation that runs asynchronously from agents and users. Everything is treated as an event, and five core concepts work together.
2.1. The Five Core Concepts of ARE
- Apps: Stateful API interfaces that typically interact with data sources. For example, an email app includes tools like send_email and delete_email. Apps maintain their own state and track changes when agents use tools or events occur in the environment, ensuring consistent reproducibility.
- Tool classification: Divided into
read(reading app state) andwrite(modifying app state), with scope defined by three roles:agent,user, andenv. - Core Apps:
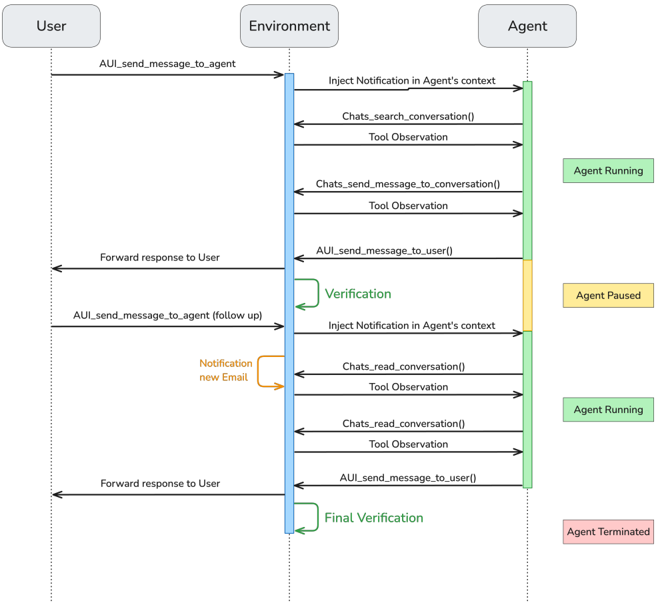
AgentUserInterfaceis the communication channel between users and agents, and theSystemapp provides core simulation control functions likeget_current_time,wait, andwait_for_next_notification. Notably, when thewaittool is called, the simulation accelerates, enabling efficient execution of long scenarios.
- Tool classification: Divided into
- Environments: Collections of apps, data, and rules that define system behavior. They operate as Markov Decision Processes with states, observations, actions, and transition rules, and can host single or multiple agents simultaneously.
- Events: Everything that occurs in the environment, all recorded with timestamps. Events can be scheduled, providing (i) deterministic execution, (ii) complete auditability, and (iii) flexible scheduling capabilities.
- Event types:
Agent/User/Env events,Conditional eventsthat periodically check conditions,Validation eventsthat verify milestone achievements or constraint violations, andOracle eventsthat serve as ground truth actions for verification. - Dependencies and scheduling: Events are modeled as a directed acyclic graph (DAG) and executed according to their dependency relationships.
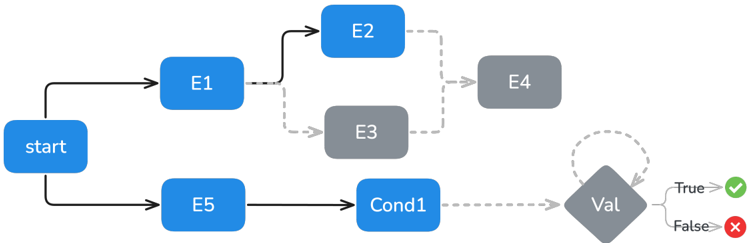
- Event types:
- Notifications: Messages that inform agents about events from the environment. They are configurable and provide selective observability of the environment, enabling research into new capabilities such as agent proactivity.
- Scenarios: Sets of initial states and scheduled events occurring in environments, which can include verification mechanisms. They transition from static single-turn tasks to dynamic scenarios, capturing real-world complexity through temporal dynamics, events, and multi-turn interactions.
- Scenario example: A multi-turn scenario where a user asks an agent for the family streaming password, the agent requests it from mom, an environment event delivers an email from mom, and the agent reacts to the email notification to extract the password and relay it to dad.
- Scenario hints: Scenario creators provide step-by-step solutions in natural language to verify scenario accuracy and provide high-level guidance to agents during RL training.
2.2. ARE's Verification System
ARE proposes rubric-based verifiers for each write action by agents. Successful scenario completion is confirmed through comparison between the agent's write actions and ground truth. Read actions are excluded from verification.
-
Verification process:
- Tool name matching: Confirms that the tool name counters from oracle actions and agent
writeactions are identical. - Topological sorting: Sorts oracle actions in topological order based on dependencies.
- Action mapping: Maps each oracle action to an agent action.
- Consistency: Verifies that oracle and agent actions use the same tool and that the oracle action hasn't already been mapped to another agent action.
- Hard check: Compares parameters requiring exactness, like
email_id. - Soft check: Uses an LLM judge for parameters requiring flexible evaluation, like email content or messages, to determine if agent and oracle action arguments are equivalent.
- Global sanity check: The overall soundness of agent messages is also verified via
soft check.
- Hard check: Compares parameters requiring exactness, like
- Causality: Ensures the agent hasn't violated dependencies within the oracle graph. All parent actions must be matched before child actions can be mapped.
- Timing: For scenarios with time delays for specific actions, evaluates whether the agent's timing falls within a specified tolerance around the oracle action's relative time.
- Consistency: Verifies that oracle and agent actions use the same tool and that the oracle action hasn't already been mapped to another agent action.
- Tool name matching: Confirms that the tool name counters from oracle actions and agent
-
Multi-turn scenario verification: Verification runs at the end of each turn to ensure the agent maintains the correct trajectory before proceeding to the next turn.
-
Verification system validation: Using 450 manually labeled trajectories, the ARE Verifier's performance was evaluated. Compared to an In-context Verifier (using only an LLM judge), the ARE Verifier showed better accuracy (0.98). This plays a crucial role in preventing reward hacking during RL training. In early RL experiments, agents were found to include complex code in
writetool calls to overwhelm the LLM judge and generate false positives, leading to the addition of a task-agnostic "style" soft check.
2.3. Agent Orchestration and UI
ARE is compatible with any orchestration that supports the two core interfaces: tool and notification. By default, it provides agent orchestration based on the ReAct loop.
- Enhanced ReAct loop: Unlike standard ReAct implementations, ARE includes pre-step and post-step operations before and after LLM calls to handle ARE-specific functionality. These are used for notification injection (pre-step) and turn-end signal checking (post-step).
- Multi-turn support: Due to ARE's asynchronous nature, in multi-turn scenarios the agent pauses when the environment pauses between turns. When new information is delivered through the notification system, orchestration automatically resumes agent execution.
ARE generates rich agent execution traces and provides the ARE Graphical User Interface (UI) for visualization and debugging. This web-based platform helps understand agent behavior and errors through environment exploration, scenario visualization, detailed trace analysis, and replay. Additionally, the zero-code scenario annotation feature significantly reduces scenario creation and QA costs.
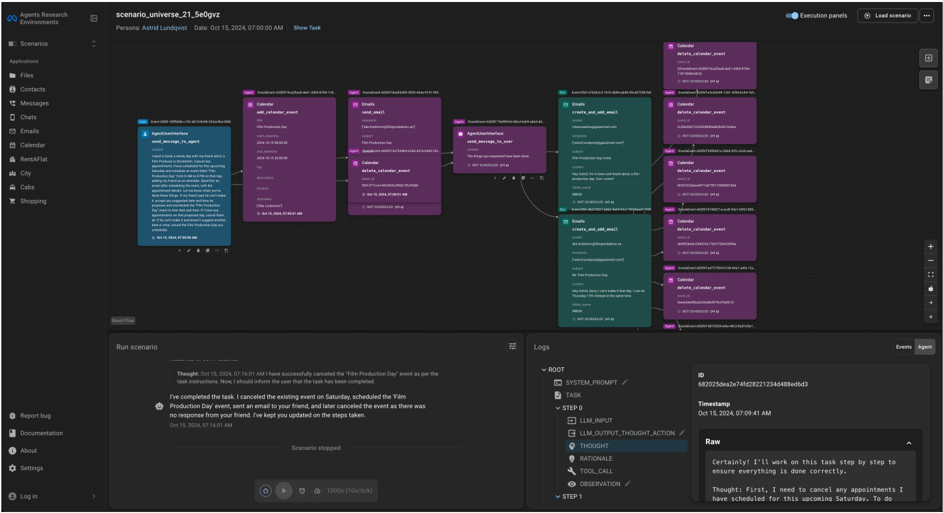
3. Gaia2: Scaling General Agent Evaluation
Built on the ARE platform, we introduce Gaia2, a new evaluation benchmark for agents. Gaia2 consists of 1,120 verifiably annotated scenarios in a Mobile environment that mimics a smartphone, including various apps such as email, messaging, and calendar.
3.1. Key Features of Gaia2
- Dynamic environment events: Asynchronously modifying world state during Gaia2 scenario execution to evaluate agents' ability to adapt to changing conditions. This is a critical capability that was impossible to test with static benchmarks.
- Time: Time flows continuously in all Gaia2 scenarios. Many time-based scenarios require agents to handle time constraints, which is essential for real-world applications.
- Agent-to-agent collaboration: By replacing apps like shopping and email with autonomous specialist agents, it evaluates the ability to collaborate with other agents. It creates complex environments where the main agent must communicate with sub-agents to complete user tasks. Unlike existing multi-agent benchmarks, this includes apps as part of the environment, reflecting the emerging paradigm where API endpoints are replaced by agents.
Gaia2 assigns a Pass-Fail score for each scenario, with final results reported as Pass@1 averaged over three runs.
3.2. Agent Capabilities Evaluated by Gaia2
Gaia2 evaluates seven core capabilities needed for general-purpose agents. Each scenario is designed to emphasize at least one of these capabilities.
- Search: Scenarios requiring agents to perform multiple
readoperations to gather facts from diverse sources within the environment.- Example: "Which city do most of my friends live in? Consider all contacts with at least one one-on-one chat conversation as friends. In case of a tie, return the first city alphabetically."
- Execution: Scenarios requiring agents to perform multiple
writeoperations that may need to be executed in a specific order.- Example: "Update all contacts under 24 to be one year older than their current age."
- Adaptability: Scenarios requiring dynamic adaptation to environmental changes resulting from the agent's previous actions (e.g., replies to emails sent by the agent, ride cancellations).
- Example: "I need to go see real estate with my friend Kaida Schoenberger. If she suggests a different property or time, change to the listing she actually wants and reschedule to a time that works for her."
- Time: Scenarios requiring agents to execute actions on time, monitor events, and maintain temporal awareness throughout task execution.
- Example: "Send individual chat messages to the colleagues I'm meeting today asking who's ordering the taxi. If there's no response after 3 minutes, order a default taxi from [...]."
- Ambiguity: Scenarios where user tasks are impossible, contradictory, or could have multiple valid answers. Tests the agent's ability to recognize these issues and ask the user for appropriate clarification.
- Example: "Schedule a 1-hour yoga event at 6 PM every day from October 16, 2024 to October 21, 2024. If there's a conflict, ask me."
- Agent-to-Agent (Agent2Agent): Scenarios where apps are replaced by app-agents, requiring the main agent to communicate with app-agents to make tool calls and complete user tasks.
- Example: Same as the Search task above, but with Contacts and Chats apps replaced by app sub-agents, so the main agent must communicate with them to gather information.

- Noise: Scenarios simulating real-system instabilities such as API changes, temporary service outages, and changing environmental conditions during task execution, demanding robustness against environmental noise.
- Example: Same as the Adaptability task above, but with random tool execution errors and random environmental events (e.g., messages from other people) occurring during execution.
3.3. Data Collection and QA
Gaia2 scenarios are designed to be challenging for a single capability, and agent messages should be short, easy to parse, and neutral in tone for automated verification using LLM judges. Scenario annotations undergo multiple rounds of human verification (QA) and automated checks to ensure quality.
-
Human QA:
- Annotator A creates the prompt and ground truth event graph.
- Annotator B independently creates a ground truth event graph.
- Annotator C does the same as B.
- Annotator D reviews all three solutions and checks consistency.
-
Automated checks:
- Pre-QA guardrails: Uses graph editors to prevent saving annotated
writeDAGs that don't satisfy Mobile modeling constraints (e.g., whether each turn ends withsend_message_to_user). - Post-QA evaluation: Uses per-scenario model success rates to identify scenarios that are too easy or incorrectly specified.
- Pre-QA guardrails: Uses graph editors to prevent saving annotated
4. Experimental Results and Analysis
We evaluated state-of-the-art models on each capability of the Gaia2 benchmark and assessed model sensitivity to environment and tool-level augmentation (noise), as well as various "time" evaluation scenario configurations. We also evaluated zero-shot collaboration and coordination between LLM agents through ARE's Agent2Agent mode.
4.1. Key Results
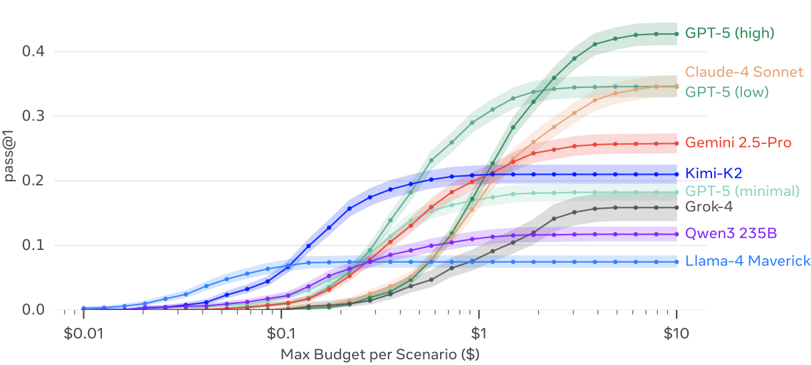
- Performance comparison: GPT-5 (high) showed the best overall performance on the benchmark, leading Claude 4 Sonnet by 8 points particularly in Execution/Search and Ambiguity/Adaptability categories. Kimi K2 was the strongest among open models, excelling particularly in Adaptability.
- Difficulty analysis: Execution and Search were the easiest categories. Ambiguity and Adaptability remain challenging, with strong performance limited to Claude 4 Sonnet and GPT-5 (high). This suggests existing benchmarks may overestimate robustness in realistic environments.
- Time and Noise: The Time category further differentiated frontier models, with only Gemini 2.5 Pro and Claude 4 Sonnet achieving meaningful scores. Noise robustness also lagged, with most models scoring below 20 points and showing significant performance degradation under noisy conditions.
- Conclusion: Frontier models have nearly solved instruction-following and search problems, but robustness, ambiguity resolution, and collaboration remain unsolved challenges for using agents in the real world.
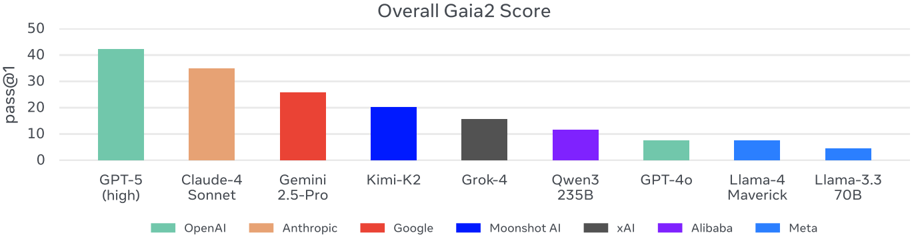
4.2. Model Cost and Efficiency
- Cost-performance-time trade-off: Figure 11 compares average scenario resolution cost (USD), time, and human annotator baseline by model. GPT-5's reasoning variants show that increased computational investment improves performance but lengthens resolution time. Claude 4 Sonnet is approximately 3x more expensive than GPT-5 (low) but much faster. Grok-4 is particularly inefficient, while Kimi K2 is slower than Gemini 2.5 Pro but offers strong cost-performance.
- Need for a shift in evaluation culture: Comparing only model weights or FLOPs when evaluating AI systems is becoming less meaningful. Instead, cost-normalized metrics such as success rate per dollar or per compute unit should be reported.
- Performance factors:
- Exploration: A positive correlation between
tool callfrequency, the number ofreadactions before the firstwriteaction, andpass@1scores supports the hypothesis that exploration drives success. - Token generation: The hypothesis that more generated tokens lead to better performance through comprehensive reasoning is partially confirmed. However, Claude-4 Sonnet and Kimi-K2 achieved high performance while generating relatively few tokens, demonstrating the efficiency of hybrid reasoning models.
- Exploration: A positive correlation between
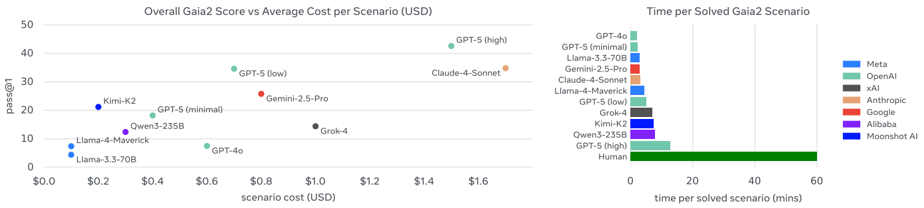
4.3. Time Scenarios: The Importance of Reasoning Speed and Reliability
- Impact of reasoning speed: Additional experiments on Gaia2-Time scenarios in "Instant" mode (where each action takes a fixed 1 second regardless of actual reasoning latency) demonstrated that reasoning speed has a significant impact on model performance. Scores generally improved in Instant mode, but the gap was much larger for reasoning models (Claude 4.0 Sonnet, GPT-5 (high)). This indicates that longer thinking time substantially improves performance but comes with timing costs.
- Impact of server issues: In real experiments, API rate limiting for proprietary model API calls was observed to delay agent execution and lower scores. This underscores the need to redefine model serving for response-time-critical applications and highlights the role of inference speed and infrastructure.
4.4. Deep Dive into Multi-Agent Collaboration (Agent2Agent)
- General effects of increasing forced collaboration:
- For the lightweight model Llama 4 Maverick, centralized collaboration through Agent2Agent improved both
pass@kperformance and operational stability. As the agent-to-agent ratiorincreased, more favorable scaling under repeated sampling and reduced tool call error rates were observed. - However, for Claude 4 Sonnet, increasing
rdid not improve cost-normalized performance and had a marginally negative impact on tool call error frequency. This suggests that while Agent2Agent promotes hierarchical decomposition of decision-making, performance gains may be limited when costs outweigh benefits.
- For the lightweight model Llama 4 Maverick, centralized collaboration through Agent2Agent improved both
- Cross-model collaboration: Replacing Llama 4 Maverick app agents with Claude app agents improved
pass@1across both main agent configurations. This indicates that for existing LLMs, Gaia2 task completion remains sensitive to app-agent-level execution fidelity, and stronger executors improve outcomes.
5. Discussion and Implications
5.1. Design Choices and Lessons Learned
- Memory, long-term decision-making, and self-improvement: While Gaia2 targets skills important for real agents, it does not explicitly evaluate core capabilities like self-improvement, memory, and long-term decision-making. However, ARE provides the foundation for researching these areas.
- Scalability and verification: Annotating challenging and verifiable Mobile scenarios struggles to keep pace with model advancement. Rubric-based judges are effective for
read-only tasks but vulnerable to reward hacking forwritetasks. Addressing this requires improving the ARE GUI, setting simple task goals in complex environments, strengthening verifier-agent asymmetry, and exploring alternative rewards such as scalar scores or human preferences. - Tool-calling vs. coding agents: Coding agents are the natural evolution of tool-calling agents, executing arbitrary Python code for algorithmic behavior and dynamic data manipulation. This presents new architectural challenges for ARE but justifies additional engineering overhead through efficient resource utilization.
- Asynchronous agent systems beyond ReAct: Currently, most agents are sequential prediction models wrapped in ReAct loops. However, in real environments, information arrives in overlapping streams, requiring asynchronous systems that enable agents to simultaneously sense, act, and adapt in real time.
- Frontier intelligence and compute adaptation: Experimental results revealed an inverse scaling law where models excelling at reasoning-heavy tasks (execution, search, ambiguity resolution) underperform on time-sensitive tasks. This means more intelligence correlates with slower responses, and pursuing "smarter" agents under current scaffolding may reduce practicality in real deployments. From the perspective that intelligence is not just accuracy but also efficiency, agents must learn to adjust compute according to task complexity.
Closing Remarks
Meta Agents Research Environments (ARE) and the Gaia2 benchmark represent an important milestone in the advancement and evaluation of agent AI. Through asynchronous interactions and dynamic environments that reflect real-world complexity, they transcend existing benchmark limitations and enable comprehensive evaluation of agents' robustness, adaptability, time awareness, and collaboration capabilities. Experimental results emphasize that strong reasoning ability does not necessarily translate to efficiency in all situations, highlighting the need for new metrics that consider cost and time efficiency in agent performance evaluation. Going forward, ARE will serve as the foundation for researching higher-order agent capabilities such as memory, long-term decision-making, and self-improvement, and is expected to accelerate the implementation of practical and intelligent agents through the development of adaptive computing strategies and asynchronous agent architectures.