The ARE (Agents Research Environments) platform and the Gaia2 benchmark built on top of it have been proposed for developing and evaluating AI agents based on the latest large language models. This system enables efficient creation, experimentation, and evaluation of agents in environments composed of various simulations, tools, and apps that mimic real-world settings. Gaia2 evaluates the general capabilities agents need for real-world tasks within these environments. A key finding is that smarter models (those with stronger reasoning) show limitations in efficiency and response speed, emphasizing that useful "intelligence" is not merely accuracy but efficiency, adaptability, and collaboration.
1. The Emergence of ARE: A Large-Scale Agent Environment and Evaluation Platform
Meta Superintelligence Labs introduced the ARE (Agents Research Environments) platform, supporting scalable environment creation, integration of real or synthetic apps, and agent orchestration execution.
ARE's most notable feature is the ability to easily build complex environments equipped with diverse tools, rules, and content, along with automated verification mechanisms within each environment. This bridges the gap between model development and real-world deployment, significantly advancing the development and applicability of AI agents.
"ARE provides abstractions that make it easy and fast to create diverse environments, and its ability to scale benchmarks through these environments rapidly closes the gap between model development and real-world application."
In particular, by implementing the Gaia2 benchmark on ARE, it comprehensively evaluates real-world capabilities beyond simple execution and retrieval, including handling ambiguity and noise, adapting to environmental changes, multi-agent collaboration, and operating under time constraints.
2. Architecture and Core Concepts of ARE
ARE centers on time-driven simulation, where all changes (events) are independently recorded, and the environment and agents operate asynchronously in a fully decoupled manner.
2.1. The Five Fundamental Elements of ARE
- Apps: Collections of tools that directly access and modify data (e.g., email, chat).
- Environments: Miniature representations of the real world containing apps and data, governed by rules.
- Events: All occurrences within an environment, meticulously recorded in chronological order.
- Notifications: The mechanism by which events are delivered to agents; notification policies control environment visibility.
- Scenarios: Evaluation units with predefined initial states and scheduled events that reflect real-world complexity.
This structure allows users to finely experiment with environmental changes, diverse user requests, and the agent's ability to adapt accordingly.
"An ARE environment is an event-driven simulation where time progresses independently. Both agents and users communicate through the same interface, and all interactions can be recorded and debugged."
3. Gaia2: A Comprehensive Benchmark for Real Agents
Gaia2 consists of a total of 1,120 scenarios across 10 "universes" that simulate smartphone environments, incorporating apps and content close to real-world use cases. Leveraging ARE's powerful simulation capabilities, agents are comprehensively evaluated on real-world work abilities including temporal dynamics, event changes, tool usage, and multi-agent collaboration.
3.1. Seven Core Capabilities Evaluated
- Search: Exploring, collecting, and integrating information from multiple sources.
- Execution: Sequential or parallel execution of multiple tasks (writing, modifying).
- Adaptability: Real-time detection of environmental changes (new emails, messages, etc.) and strategy adjustment.
- Time: Processing tasks within deadlines and responding to time-dependent events.
- Ambiguity: Recognizing unclear or multi-answer requests and asking clarifying questions.
- Agent-to-Agent Collaboration: Communication and role division when apps are replaced by "sub-agents."
- Noise Resistance: Reliably completing missions amid tool/service errors, irrelevant events, and other real-environment noise.
"Agents must instantly adjust their strategies in response to dynamic events within the environment and communicate with multiple sub-agents to solve complex real-world tasks."
The scenario creation and verification processes are rigorously designed, with all agent actions automatically evaluated against pre-designed "oracle actions" for alignment.
4. ARE's Verification System and Agent Operation
ARE evaluates each agent's write actions using a rubric-based approach (structural comparison against ground-truth examples). It goes beyond simply checking whether an action was executed, examining action sequence, condition fulfillment, and time constraints.
"Actions that must exactly match the ground truth undergo hard checks, while areas requiring flexibility like message content use LLM-based soft checks."
Additionally, in multi-turn scenarios, systematic execution is achieved through per-turn verification, conditional event triggers, and online validation.
Agent execution combines the standard ReAct loop with asynchronous notifications, tool usage, and result verification through an orchestration approach, enabling agent behavior close to real-world operation.
5. Experimental Results: Limitations and Insights of State-of-the-Art LLM Agents
5.1 Model Performance Comparison
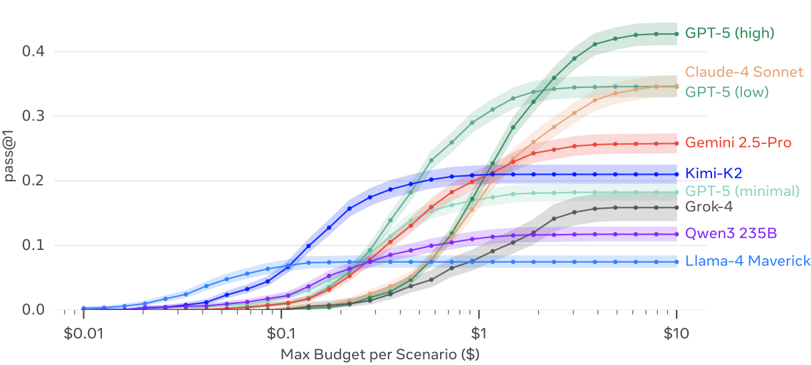
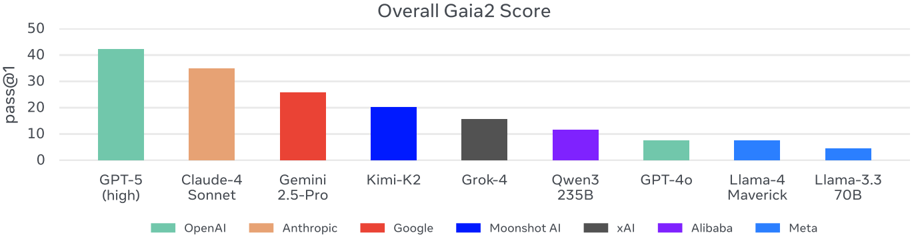
Multiple open and proprietary LLMs (e.g., GPT-5, Claude-4 Sonnet, Gemini 2.5 Pro) were comparatively evaluated in identical environments and scenarios.
Key findings:
- Instruction following and information retrieval are already strong across many models.
- Adaptability, ambiguity handling, multi-agent collaboration, and real-time responsiveness remain weak even for top-tier models like GPT-5 and Claude.
- Clear trade-offs between speed, cost, and success rate emerged. For example, models with the deepest reasoning excel at problem-solving but are often slow and expensive.
"More intelligent agents typically consume more computational resources and take longer. But in real environments, being fast and efficient is what makes an agent useful."
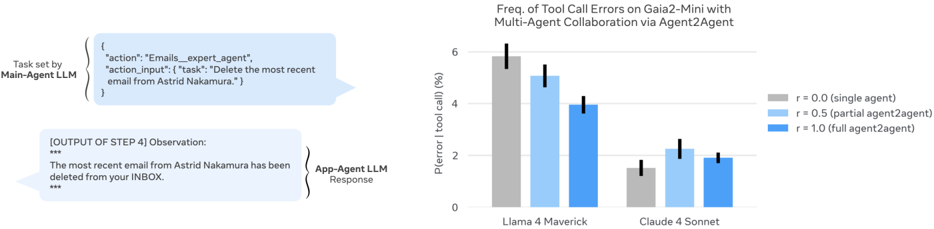
5.2 Implications of Collaboration Structures
In Agent2Agent experiments, placing a strong model (sub-agent) beneath a lightweight model significantly improved overall performance.
"A heterogeneous collaboration structure where the main agent plans and decomposes tasks while sub-agents quickly execute sub-tasks proved effective."
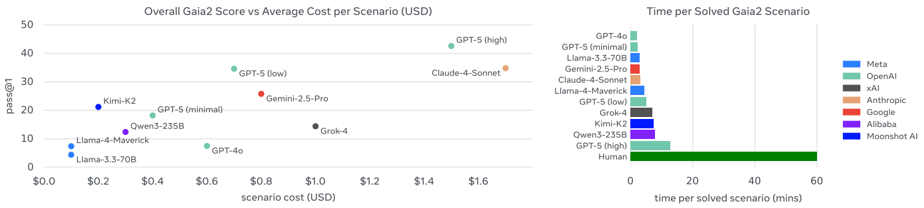
5.3 Relationship Between Time, Speed, and Cost
Models showed significant differences not only in task accuracy but also in response speed and cost efficiency. Notably, in scenarios where real-time responsiveness is critical (Time), models with deeper reasoning exhibited sharply declining performance, revealing an "inverse scaling law."
"Smarter agents are slower, and as a result, the higher the real-time demands, the lower their practical utility."
6. Key Lessons and Future Challenges
6.1 Conditions for Practical Intelligence: Efficiency + Adaptability
The ARE and Gaia2 experiments show that the simple equation "intelligence = accuracy" no longer holds. In practice, AI agents for real-world use require all three of the following:
- Accurate problem-solving ability
- Fast response and efficient resource utilization
- Adaptability to environmental changes and noise
"A truly useful agent should handle easy tasks quickly and cheaply, and solve difficult ones reliably."
6.2 Verification and Continuous Expansion
- Consistent benchmark and environment expansion is critical
- Environments need to be more complex, verification more rigorous, and even simple tasks need realistic noise and time constraints to enhance real-world fidelity
6.3 The Future of ARE
- Introduction of Code Agents, going beyond simple tool calls
- Emphasis on the need for fully asynchronous, multi-sensory, environment-connected agent operating systems that go beyond the limitations of sequential (synchronous) ReAct loops
"We need truly evolving systems where environments and agents independently and asynchronously continue to develop."
Closing Thoughts
ARE and Gaia2 present important tools and standards for the real-world application and evaluation of AI agents. The era of evaluating models solely by size or accuracy is over. Going forward, "real-world intelligence" encompassing efficiency, adaptability, and collaboration will be the core of agent competitiveness. These results and tools enable any researcher or developer to easily create their own agents, benchmarks, and evaluation criteria in real-world scenarios, opening a new horizon for AI advancement.
"For sustained progress, meaningful task definition and sophisticated evaluation are essential. ARE and Gaia2 are the starting point."
References: Code and platform: https://github.com/facebookresearch/meta-agents-research-environments Contact: rfroger@meta.com, gmialon@meta.com, tscialom@meta.com