
While building the AI agent project Manus, the author and team faced a critical decision: whether to train an end-to-end agent model from scratch using open-source foundations, or to leverage the in-context learning capabilities of the latest large language models (LLMs) and build the agent on top of them.
Past Experience and a New Choice
In the past, applying models like BERT to new tasks required fine-tuning and evaluation -- a process that took weeks per iteration despite much smaller models. In a startup environment where fast feedback is crucial, this slow pace was fatal. The author confesses to feeling this limitation acutely while training models directly at a previous startup.
"Back then, training models directly was the only option, and that slow feedback loop ended up being a major obstacle."
But with the emergence of models like GPT-3 and Flan-T5, everything changed. In-context learning made it possible to rapidly apply models to diverse tasks without training them directly. Based on this experience, Manus decided to focus on context engineering -- enabling product improvements in hours rather than weeks, and ensuring the product could ride the wave of model advancement.
"If model advancement is a rising tide, Manus wanted to be a boat floating on it, not a pole fixed to the seabed."
The Reality of Context Engineering
But context engineering was far from simple. The team rebuilt their agent framework four times, discovering better context composition methods each time. The team jokingly calls this process "Stochastic Graduate Descent" -- a mix of trial-and-error, experimentation, and educated guessing that actually worked.
This article shares the optimal context engineering principles the team discovered through hands-on experience, in hopes of helping others building AI agents.
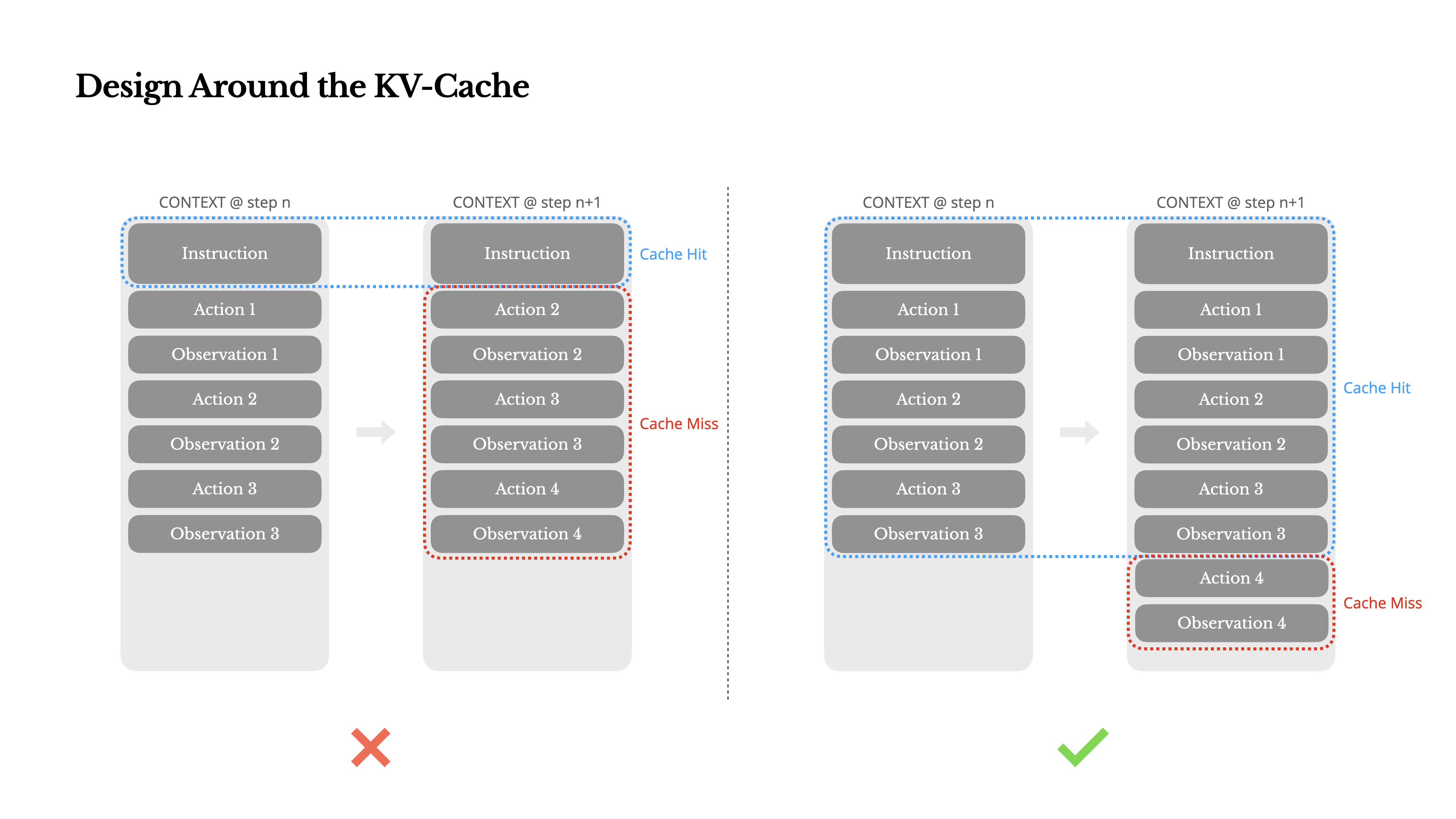
1. Design Around the KV-Cache
KV-cache hit rate is the single most important metric for production AI agents, the author emphasizes, because it directly affects latency and cost.
How Agents Work
A typical agent repeats the following loop:
- Receive user input
- The model selects an action based on the current context
- Execute the action in the environment (e.g., Manus's virtual machine sandbox)
- Append the result (observation) to the context
- Repeat until the goal is achieved
During this process, the context grows steadily while outputs (e.g., function calls) remain relatively short. In Manus, the input-to-output token ratio reaches approximately 100:1.
Why KV-Cache Matters
If the beginning of the context remains identical, the KV-cache can drastically reduce time to first token (TTFT) and inference costs. For example, on Claude Sonnet, cached input tokens cost 0.30 USD/MTok versus 3 USD/MTok for uncached -- a 10x difference.
KV-Cache Optimization Practices
- Keep prompt prefixes (system prompts, etc.) identical at all times -- including a second-level timestamp in the prompt invalidates the cache
- Only append to the context; never modify previous content -- non-deterministic JSON serialization (changing key order) can break the cache
- Clearly mark cache breakpoints -- some frameworks require manual cache breakpoint placement, so always include up to the end of the system prompt
- When self-hosting models with vLLM etc., enable prefix/prompt caching -- use session IDs for consistent request routing in distributed environments
"Even a single character difference invalidates the entire cache from that point forward."
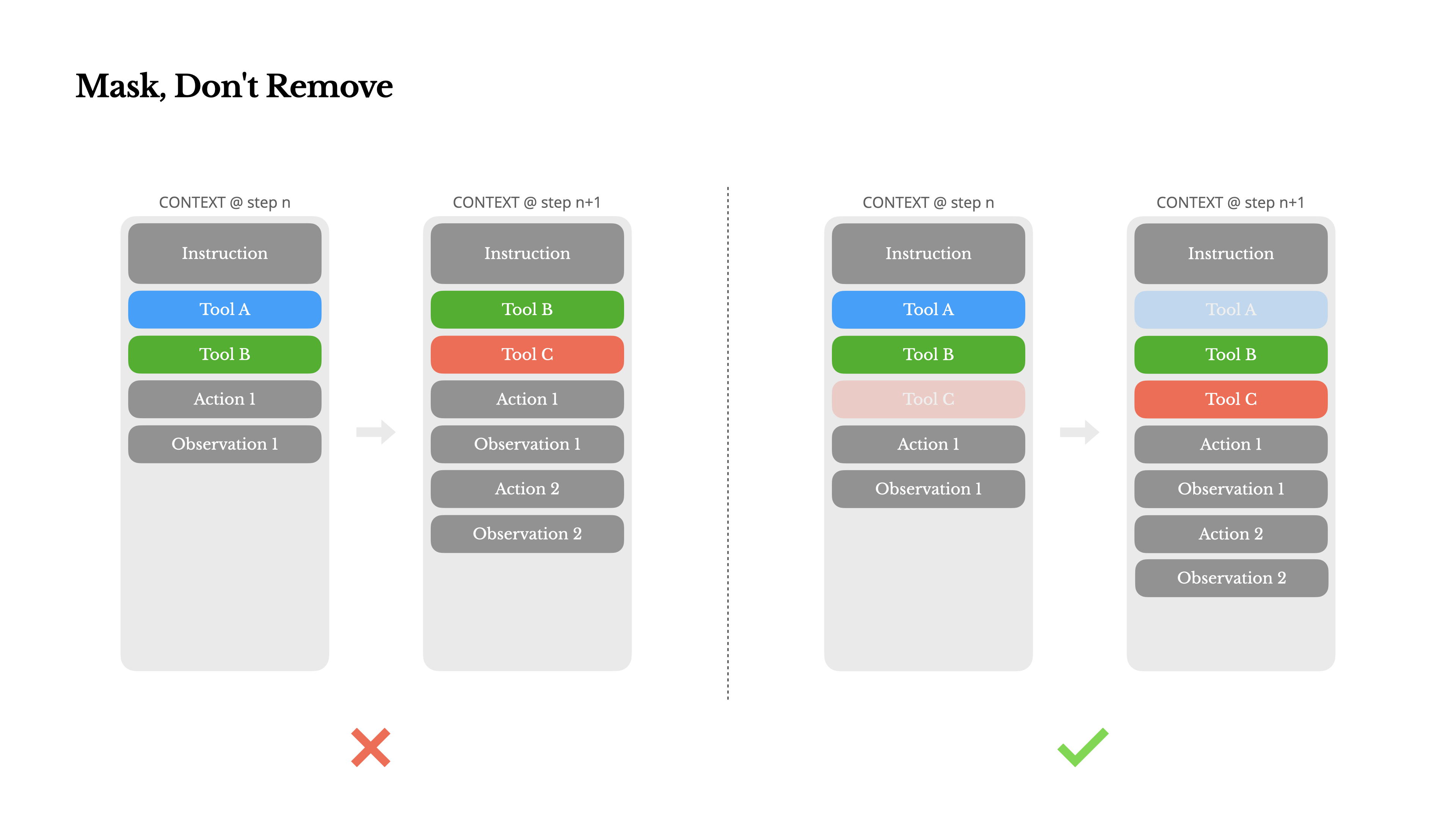
2. Mask, Don't Delete
As the number of tools (actions) an agent can use grows, the model is more likely to take wrong actions or choose inefficient paths. With MCP (Model Context Protocol) and similar protocols, tool counts are exploding.
Problems with Dynamic Action Spaces
- Dynamically adding/removing tools changes the beginning of the context (near the system prompt), invalidating the KV-cache
- Previous actions/observations referencing now-undefined tools confuse the model
- Without constrained decoding, schema errors and hallucinations can occur
Manus's Solution: Masking
Manus uses a state machine to manage tool availability. Rather than removing tools, it masks token logits during decoding so only specific actions can be selected.
Function Call Modes (Hermes format)
- Auto: The model freely decides whether to call a function
- Required: Must call a function, but chooses which one
- Specified: Only specific functions can be called
Using this approach, for example, when a user provides new input, Manus can respond immediately without taking any action. Consistent tool name prefixes (e.g., browser_, shell_) also make it easy to restrict selection by group based on state.
"Controlling action selection through masking alone, without deleting tools, makes the agent loop far more stable."
3. Use the File System as Context
Modern LLMs offer context windows of 128K+ tokens, but in real agent environments this is often insufficient -- or even counterproductive.
Practical Limits
- Observations can be extremely large -- unstructured data like web pages and PDFs easily exceed context limits
- Longer context degrades model performance
- Long inputs are expensive -- even with prefix caching, all tokens must be transmitted and filled
Lossless Compression Strategy
Many systems truncate or compress context, but overdoing it loses critical information -- you can't predict which observations will matter later.
Manus uses the file system as an infinite, persistent external memory. The model is trained to read and write files as needed, treating the file system not as mere storage but as a structured external memory.
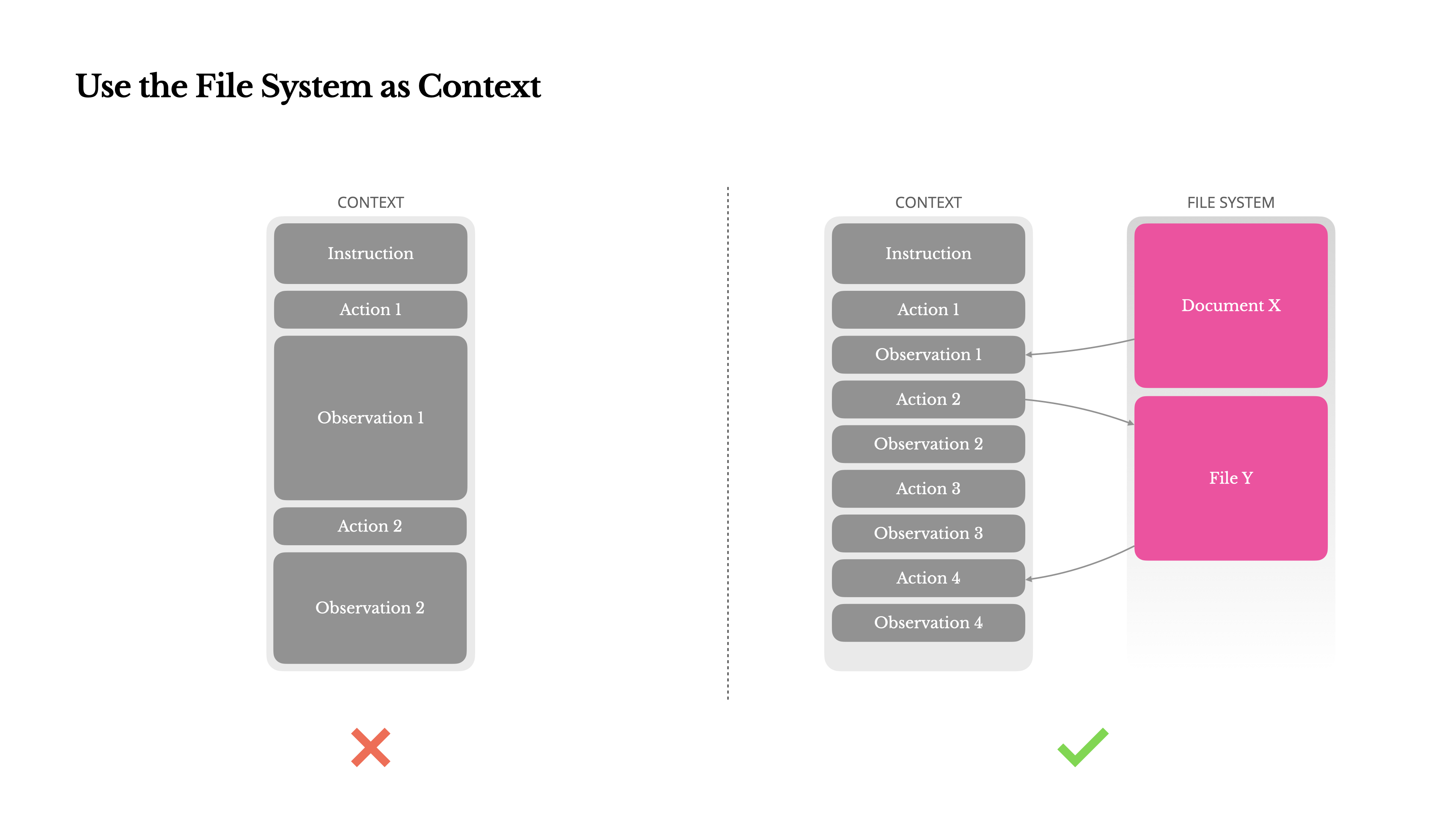
For example, a web page's content can be removed from the context with only the URL retained, and document paths can be kept so they can be retrieved at any time. This reduces context length without losing information.
"Using the file system as external memory allows agents to operate efficiently without keeping long-term state in the context."
4. Manipulate Attention with Recitation
If you've used Manus, you may have noticed that during complex tasks it creates a todo.md file and checks off items as it progresses.
This isn't just a cute behavior -- it's an intentional mechanism to steer the model's attention.
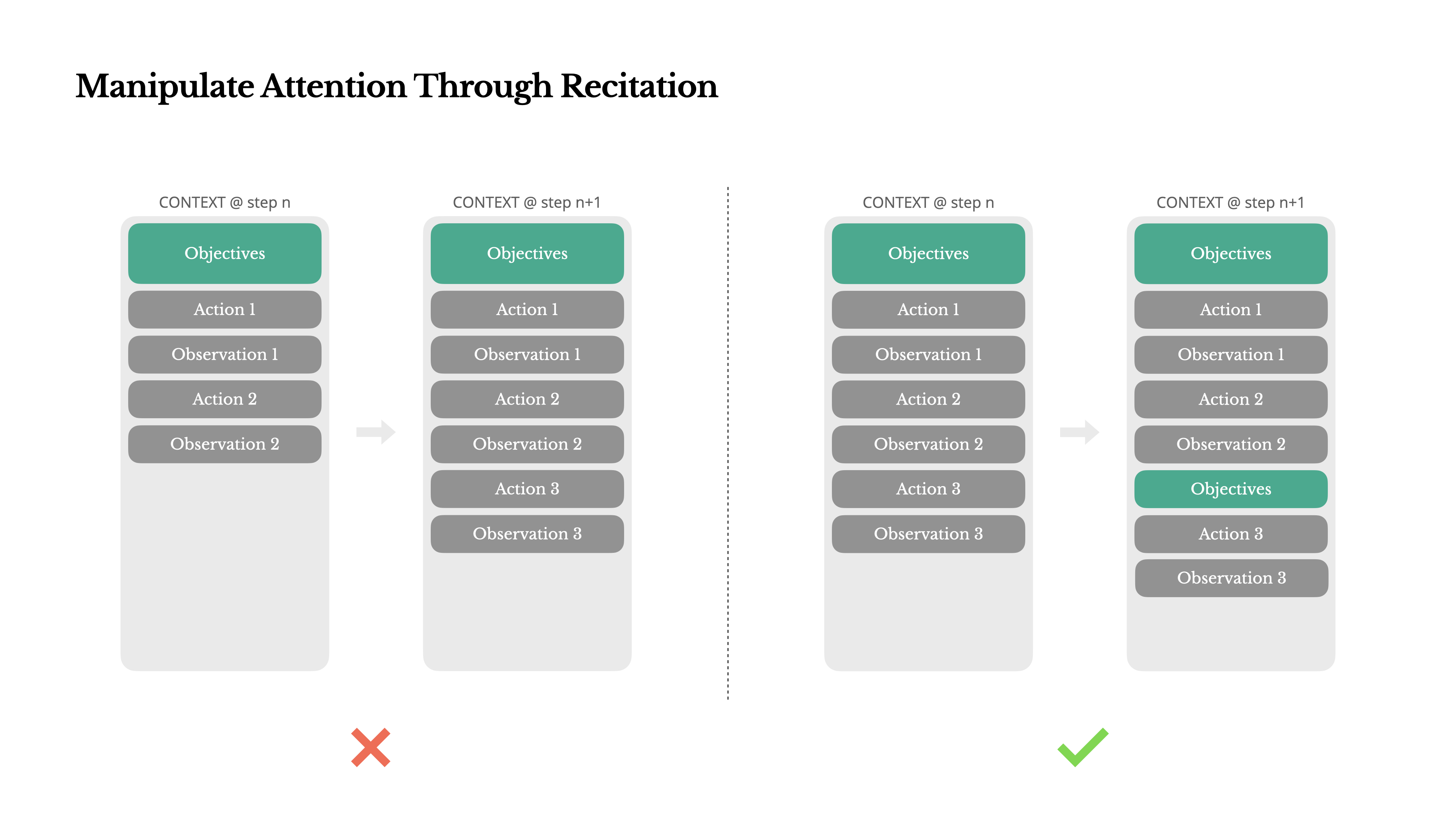
Manus averages around 50 tool calls per long task. During this process, the LLM risks losing sight of the goal or drifting off-topic. By continuously updating a todo list and rewriting the goal at the end of the context, the full plan is kept in the model's recent attention window. This reduces the "lost-in-the-middle" phenomenon and prevents goal misalignment.
"Simply rewriting the goal in natural language is enough to focus the model's attention where you want it."
5. Keep Erroneous Information in Context
Agents make mistakes. Language models hallucinate, environments throw errors, and external tools malfunction -- failures happen repeatedly.
Many developers tend to hide these errors, erase traces, reset state, and retry. But this destroys evidence of failure, depriving the model of opportunities to learn and adapt.

In Manus, failed actions and their results (error messages, stack traces, etc.) are left in the context as-is. This lets the model update its internal beliefs and reduces the probability of repeating similar mistakes.
"Leaving failures in the context rather than erasing them was one of the most effective ways to improve agent behavior."
6. Don't Get Trapped by Few-Shot
Few-shot prompting is commonly used to improve LLM outputs, but in agent systems it can actually backfire.
Models tend to mimic the action-observation pairs in the context. For instance, when reviewing 20 resumes, if similar actions repeat, the model can get locked into that pattern -- causing drift (bias), overgeneralization, and even hallucination.
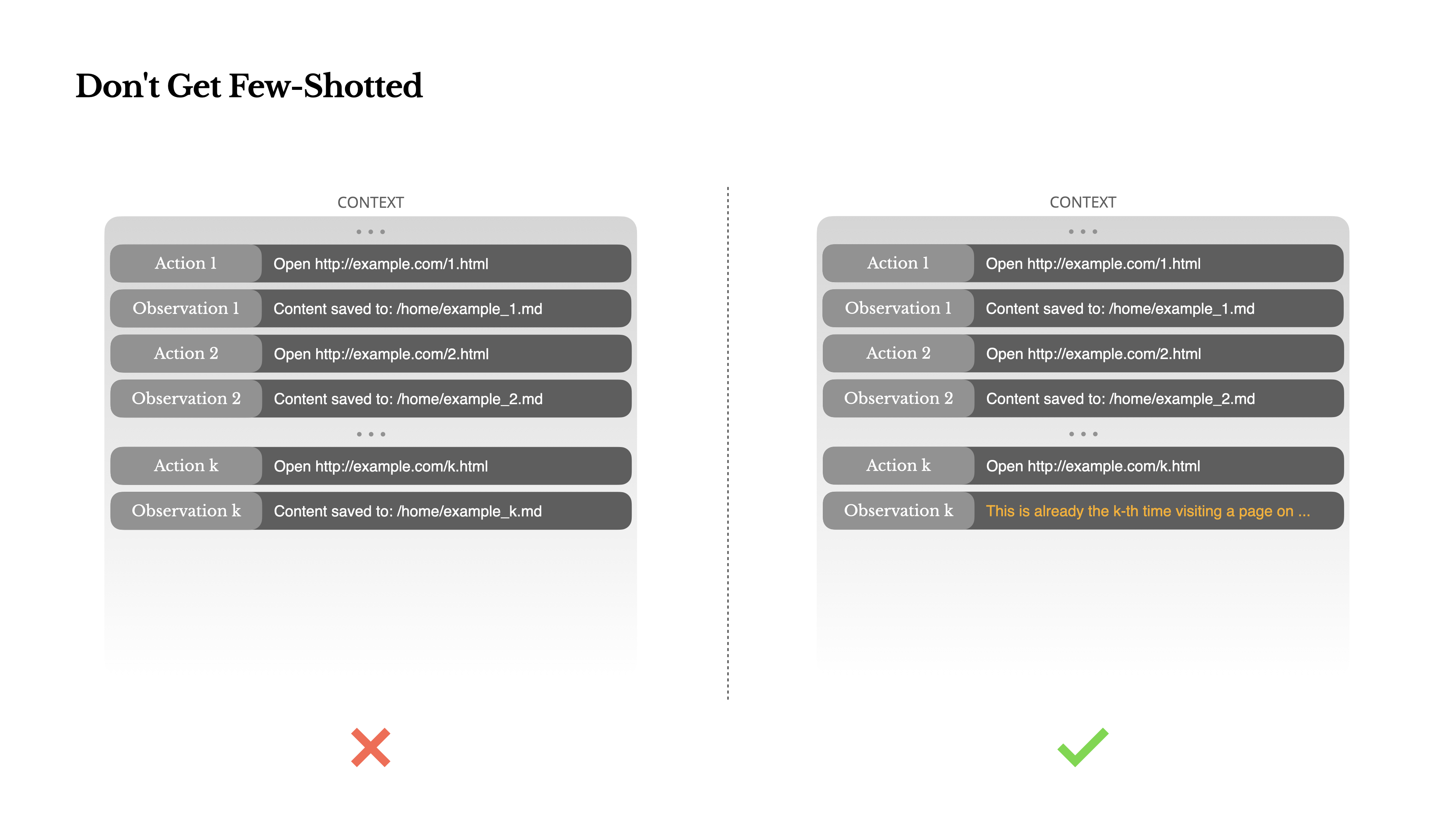
Manus addresses this by deliberately introducing structural diversity in actions and observations:
- Varying serialization templates
- Changing expressions
- Adding slight noise to ordering and formatting
"When the context becomes too uniform, the agent becomes fragile. You need to inject diversity."
Conclusion
Context engineering is still an evolving field, but it's already essential for agent systems. No matter how powerful models become, how you handle memory, environment, and feedback determines agent performance.
The Manus team arrived at these principles through countless iterations and real-world user testing. These findings aren't universal truths, but we hope they help you avoid similar trial and error.
"The future of agents is built one context at a time. Design it well."
Key Concepts:
- KV-cache
- Context engineering
- Tool masking
- File system as external memory
- Recitation
- Failure logging
- Diversity (anti-few-shot)
- Agent systems
- LLM
- Manus