This piece explains the importance of the eval loop for solving the quality problem of AI-generated output—"slop"—along with a concrete way to build one. It stresses that better prompts or swapping models won't fix the problem at its root, and presents a system that uses an open-source agent called Hermes to evaluate and manage every AI output against a standard. If you want to keep the quality of your AI output consistent, this article will be a big help! 🛠️📈
1. The Nature of the AI Output Quality Problem (Slop) 🤔
Whenever AI output quality drops, many people have probably tried all sorts of things: improving the prompt, using a more expensive model, writing longer instructions, turning on memory features, building massive context files, and so on. But the author points out that all of these attempts amount to "constantly fixing a layer that was never broken." AI output quality degradation—"slop"—is not a prompt problem but a systems problem. He explains it's just like a factory shipping defective products: that's not a worker problem, it's a quality-control problem. The trouble arises because no one checks the quality before the product ships.
The author explains in detail "why better prompts, bigger models, and memory features never kill slop for good, and what the one layer is that actually works," as well as "the two places slop hides (content and product output) and why the solution is the same for both." Ultimately, the AI output quality problem doesn't come from the fact that "the model can't produce good work," but from the fact that there's "no way to tell good work from bad work before it reaches the person who matters."
"Slop is not a prompt problem but a systems problem. Just as a factory shipping defective products is a quality-control problem rather than a worker problem, no one checks the output before it leaves the building."
Because AI models are non-deterministic, running the same prompt twice yields two different results. Even a 'perfect' prompt can produce bad output on a certain percentage of runs, and you can't tell which run is the problem until the client or user discovers it.
"The model is non-deterministic. Run the same prompt twice and you get two different answers. This means even a perfect prompt produces slop on some runs, and you don't know which run it is until the client or user sees it."
2. The Two Areas Where Slop Hides 🕵️♀️
The AI output quality problem arises mainly in two areas, and surprisingly, the solution is the same for both.
2.1. Content Slop 📝
This covers all the content you generate with AI and publish under your own name—for example, tweets, articles, emails, landing pages, blog posts, and so on. This content slop is technically fine, but it can look like "completely hollow" work. It seems okay on the surface, but there's actually nothing of substance to it. Since each individual piece looked fine when you sent it, it's hard to explain why it failed.
2.2. Product Slop 🛠️
This refers to AI features, agents, chatbots, support responses, data-extraction pipelines, and the like that users actually use. Here, slop shows up in forms like "wrong answers delivered with full confidence, hallucinated numbers, broken JSON payloads, an off-brand tone of voice." It was great in the demo but quietly degrades after deployment in many cases.
"Content slop and product slop are both unmeasured AI output going straight to an audience with no gate in between."
These two types of slop stem from the same problem, and the eval loop you build in "Hermes" can evaluate both in the same way. The only difference is that content slop embarrasses you loudly, while product slop quietly drives your users away.
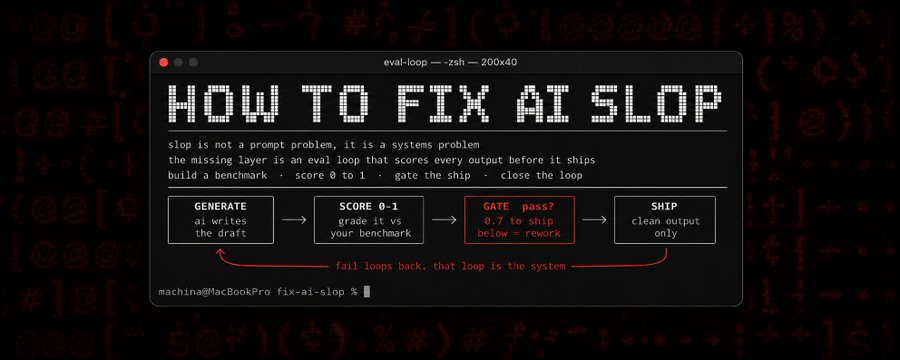
3. What Is an Eval Loop? 🔄
An eval loop, as the author defines it, is "a repeatable test that automatically evaluates AI output against a standard, every time, before and after shipping." Pretty simple, right? But the problem is that most people who use AI are missing this layer.
A basic eval loop consists of the following steps.
- Generate output: The AI produces some output.
- Score against benchmarks: Score the output against benchmarks you defined in advance.
- Catch bad output: Filter out output that falls below the bar.
- Fix the cause of failure: Analyze why the score was low and fix it.
- Re-score and pass: Score it again, and only output that passes moves on to the next step.
"An eval loop is a repeatable test that automatically evaluates AI output against a standard, every time, before and after shipping."
Software engineers have long gone through this process under the name 'testing.' It's unthinkable to ship code without tests, yet in the AI industry it's common to deliver output straight from the model to the user. The reason there's no eval loop, the author explains, is that many of the people building AI come from content, sales, or product backgrounds rather than engineering. The very concept of "writing tests for your output" can be unfamiliar to them.
3.1. The Three Points Where an Eval Loop Operates 🎯
An effective eval loop should run in the following three places.
- Before shipping: Run a new prompt or model against existing test cases to verify that quality hasn't degraded compared to before. This is regression testing, which prevents you from quietly breaking three other things while trying to fix one.
- At runtime: Score the output the moment it's generated and use conditional logic to catch failures before they reach the user. This acts as a guardrail.
- In production: Continuously evaluate a sample of real runs to detect quality degradation the moment it begins. It lets you notice the problem weeks before customers complain.
4. Building a Quality Benchmark 📏
A quality benchmark, whether for content or product, consists of three core components.
-
Test Cases: Pairs of real inputs and expected outputs that show what 'good' output looks like (ground truth).
- For content: Gather your 20–50 best pieces of content and treat them as the 'gold standard.' You're extracting the bar you've already met at your highest level.
- For product: Use real inputs drawn from actual user session logs. What belongs here isn't the 'happy path' examples from launch day, but the 'weird' cases that break your system.
-
Metrics: How you convert output into a score between 0 and 1.
- For content: Use a rubric. For example, the author proposes the following four criteria.
- Does it explain concretely how to do it?
- Can every audience understand it?
- Is it structured, reproducible, and explained step by step?
- Is it new and original?
- On top of all of these, he stresses that the meta-criterion "Will someone bookmark this and come back later to implement it?" is important.
"Meta-criterion: Will someone bookmark this and come back later to implement it? If the answer is 'no,' then no matter how cleanly the piece reads, it's slop."
- For product: Use metrics suited to the task. Use 'exact match' when you need precise labels, a 'validator' when structure matters, 'semantic similarity + a judge' for open-ended output, and so on. The important thing is that it must return a number.
- For content: Use a rubric. For example, the author proposes the following four criteria.
-
Threshold: The baseline below which output is never shipped.
- The author suggests 0.7 as a reasonable starting point, and anything below 0.7 should be reworked or scrapped. He stresses that a threshold "only works when you don't let a 0.6 through just because it looks good." The point is to decide by the numbers rather than relying on feelings.
5. Building an Eval Loop in Hermes: 6 Steps 🛠️
Hermes doesn't provide a dedicated 'quality dashboard' feature for the eval loop; instead, it provides the building blocks for assembling an eval loop yourself.
5.1. Step 1: Install Hermes and make it accessible. 📲
It's important to connect Hermes to a messaging platform like Telegram. That way, Hermes can do work in the background and send a notification to Slack or Telegram when a decision is needed.
5.2. Step 2: Load the gold standard into Hermes's memory. 🧠
Hermes has persistent memory, so once you load the 20–50 best pieces of content used in your benchmark just once, they're stored as the agent's long-term memory. This lets the agent query, at any time, the 'truth' that used to be scattered across screenshots and old drafts.
5.3. Step 3: Turn the rubric into a judge skill. 🧑⚖️
Instruct Hermes to create a skill that takes the rubric and the output in English and returns a 0–1 score per criterion along with a one-line reason. This is exactly 'LLM-as-a-judge.' The AI evaluates your AI, in effect. This skill is stored as Hermes's procedural memory, so once it's encoded it evaluates every output forever.
"This is exactly LLM-as-a-judge. It's an agent that evaluates your LLM, and a model with a sharp rubric is a more consistent critic than you are—because it has no ego in the work and no attachment to the one sentence you're secretly proud of."
5.4. Step 4: Turn the test suite into a skill. 🧪
Turn the test cases and metric functions into a skill that Hermes holds and version-controls. Build the library of metrics you need: 'exact match' for classification, 'regular expressions' for extraction, 'JSON and key-value validators' for structure, 'semantic similarity' for generative output, and so on. When you describe the task, Hermes writes the scoring code itself.
5.5. Step 5: Control shipping with regression tests and an approval button. 🚦
Set things up so that any change—a new prompt, a model swap, a pipeline tweak—triggers the test suite. Hermes re-runs every case, calculates the score difference from the baseline, and then sends a Slack notification like "The score dropped from 0.81 to 0.74. A regression occurred in two cases. Do you approve?" Nothing proceeds until you press the button.
5.6. Step 6: Monitor production with Cron and complete the loop. 🔄
Use Hermes's built-in Cron feature to schedule it to sample real runs, score them with the same judge skill, and send you a DM the instant quality drops. This lets you spot quality degradation weeks before customers complain.
What's even more remarkable: when you thumbs-down a low-quality output in Slack, Hermes records it back into the suite skill as a new test case. A failed run becomes a permanent check item, and thanks to Hermes's self-improvement habit, the test suite reinforces itself every week.
"The feature is that Hermes self-improves. Every week the suite reinforces itself, so the bar rises even while you sleep."
Conclusion 🌟
The reason you can't secure consistent quality in your AI output isn't that you're bad at crafting prompts or that the model isn't smart enough. It's precisely because you're running only a generation stage with no quality stage. You've built only half of the system and are blaming the other half that works.
The real solution isn't a better prompt—it's adding the missing layer.
- Define what 'good' is,
- convert it into a number,
- evaluate every output against that standard,
- filter out everything that falls below the bar,
- and complete the loop so that the bar rises every week.
This layer is no longer a future project—you can implement it in just six steps inside a Hermes agent running on your own computer. Do this, and 'slop' becomes not a problem that occurs at random, but one you can always catch before shipping—just as a real factory catches defects before they reach the customer.
"The prompt was never the system. The eval loop is the system, Hermes is where that system runs, and now you have it too."