The gpt-oss series (20B, 120B) released by OpenAI in 2025 is the first fully open-weight LLM since GPT-2, six years prior. This article compares the core architecture of gpt-oss with GPT-2 and Qwen3, traces the context of these changes, and analyzes the latest optimizations, efficiency improvements, and various benchmark results. It provides a detailed understanding of how the history of LLM development has unfolded and what open-weight models mean for the field.
1. The Release of gpt-oss: The First Large-Scale Open-Weight LLM Since GPT-2 in 2019
This week, OpenAI released two large language models with open weights: gpt-oss-20b and gpt-oss-120b. These are the first fully open-weight large-scale LLMs since GPT-2 in 2019. A notable point is that thanks to efficient optimization, they can run on a consumer GPU or even a single H100 card, which we'll cover in more detail later.
"The gpt-oss models were each trained with advanced pre-training and post-training techniques."
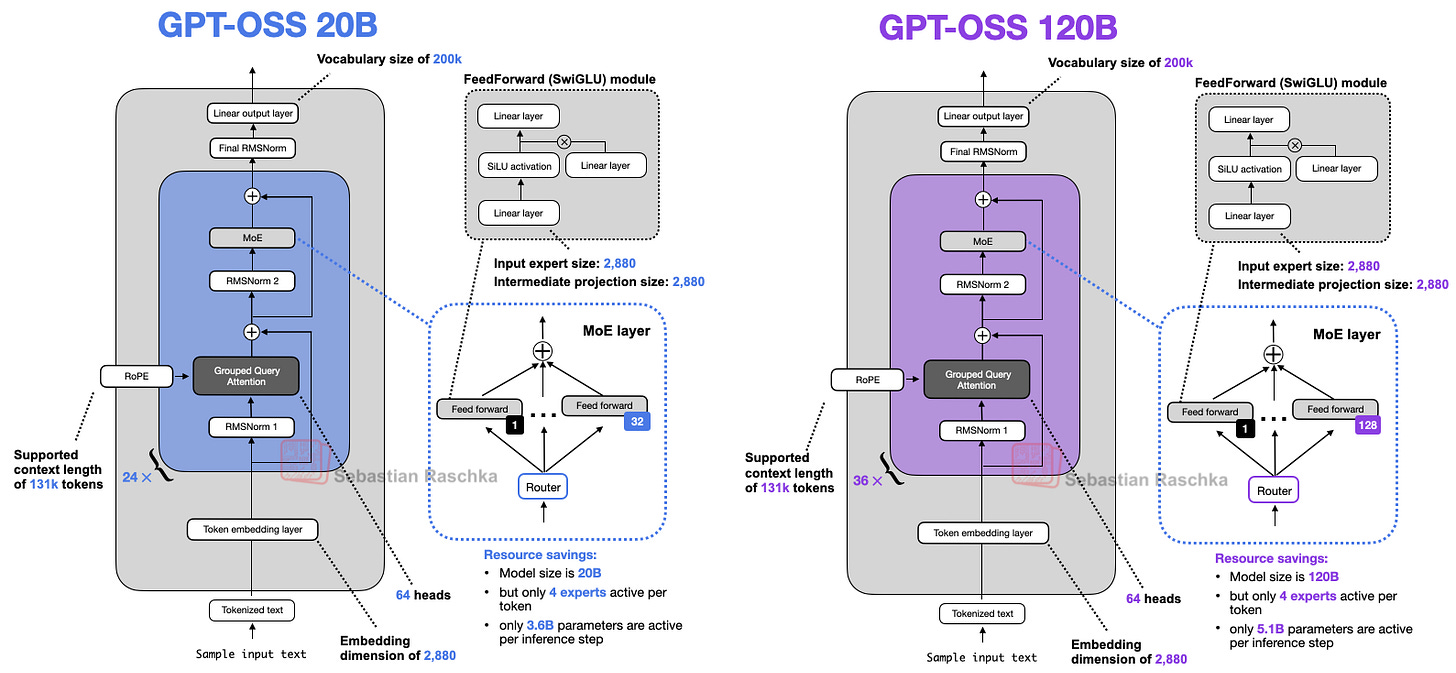
gpt-oss-20b can run on an RTX 50xx-class GPU (16GB VRAM), and the 120b on an 80GB H100. Before diving into the full analysis, the article helpfully explains the model architecture, scope of the release, and practical usage methods.
2. Comparison with GPT-2: The Big Picture of LLM Architectural Evolution
GPT-2 (2019) is a decoder-only LLM based on the Transformer architecture. gpt-oss shares the same roots, but there have been significant advances in several areas.
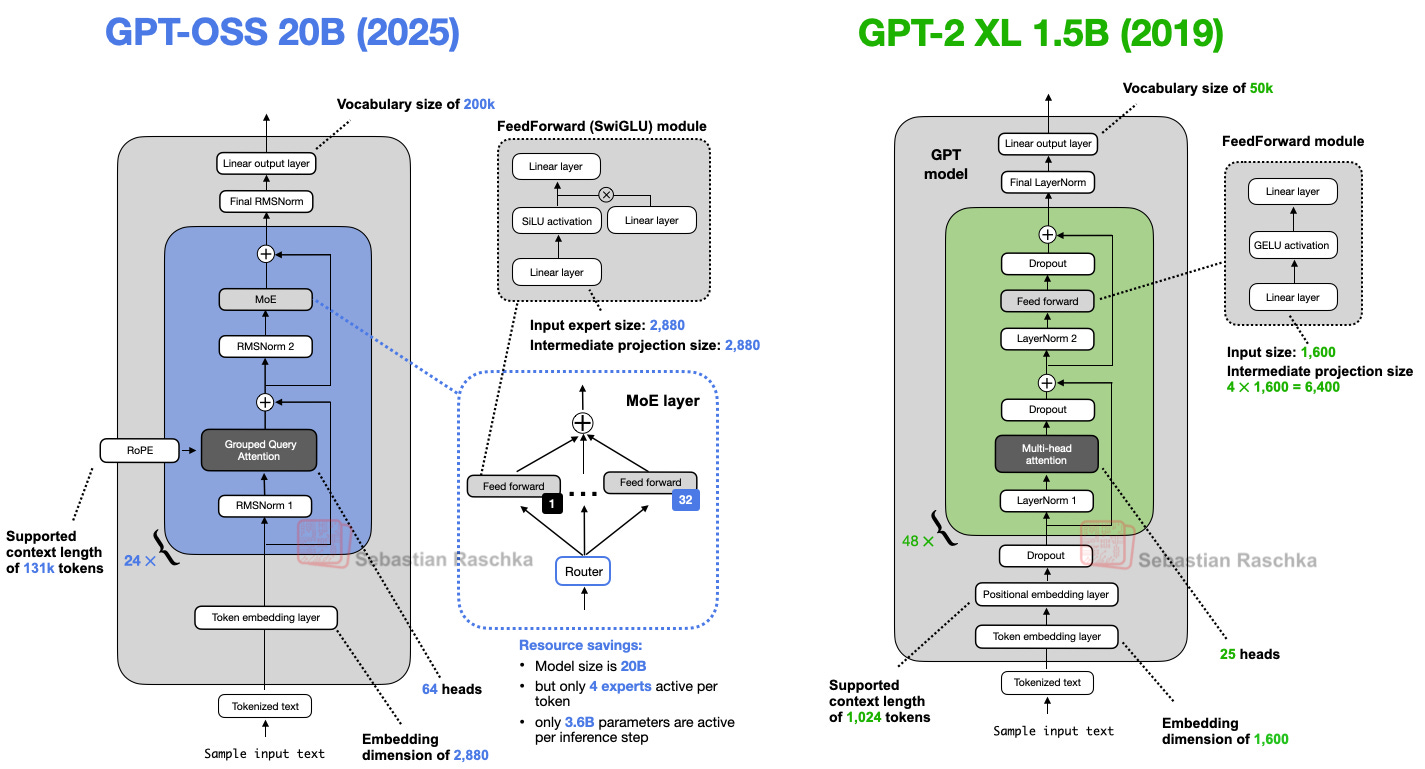
Let's look at the key architectural differences and their background:
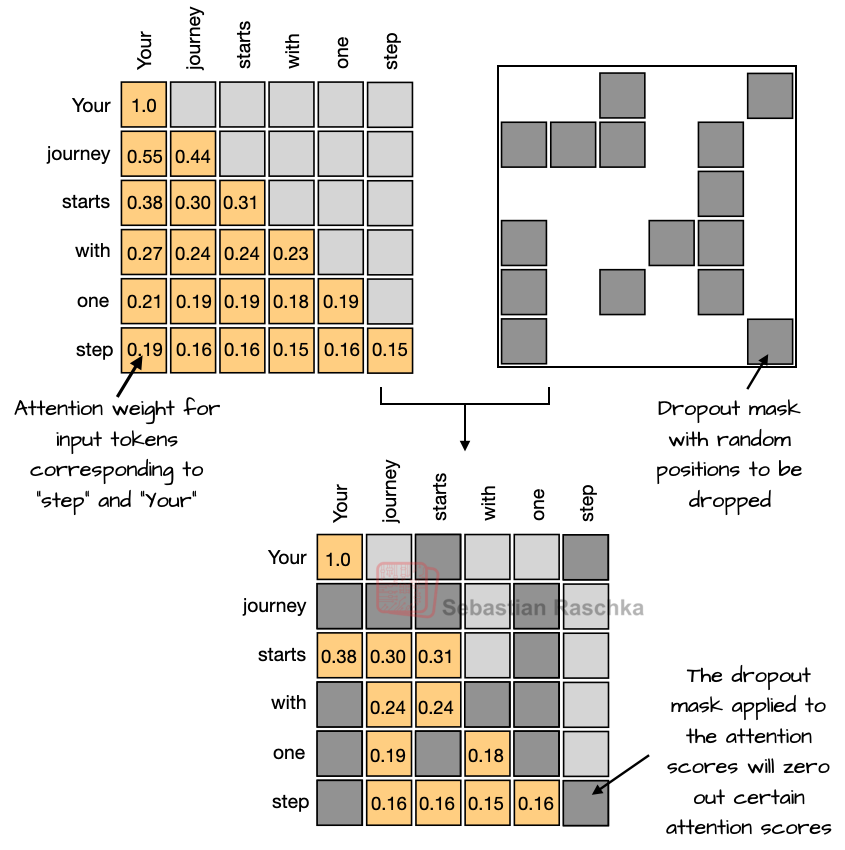
2-1. The Decline of Dropout
While dropout was widely used in the GPT-2 era to prevent overfitting, modern LLMs train on enormously large datasets for a single epoch, making dropout virtually ineffective.
"Dropout is not good for LLMs. Recent experiments have confirmed that it actually degrades downstream performance."
2-2. Positional Embeddings: From Absolute to RoPE
Early models used absolute positional embeddings, but RoPE (Rotary Position Embedding) has now become the standard. RoPE encodes position by rotating query-key vectors on a per-token basis.
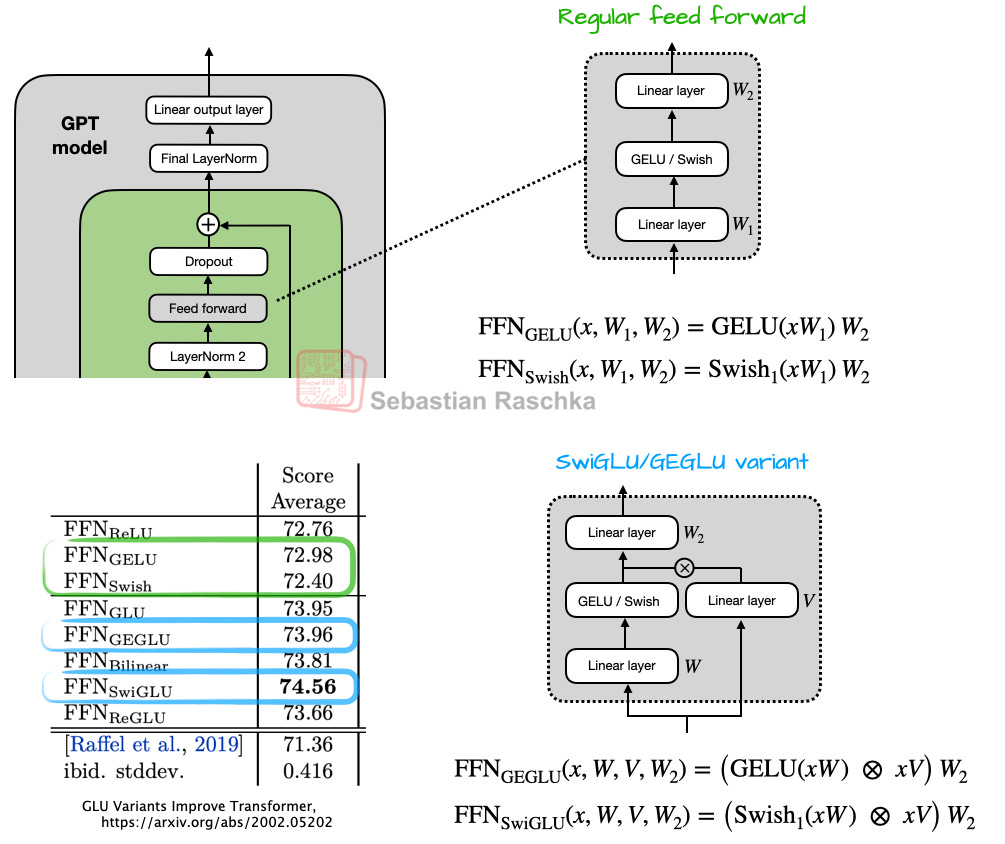
2-3. Activation Functions: From GELU to Swish/SwiGLU
GELU was initially used, but it has been replaced by newer functions like Swish and SwiGLU, which require less computation (achieving the same effect with fewer parameters) while delivering comparable performance.
"GLU-family activations like SwiGLU may appear to use more parameters, but in practice they achieve better performance with fewer parameters."
3. Key Innovations: Mixture-of-Experts, GQA, Sliding-Window Attention
3-1. Mixture-of-Experts (MoE)
Instead of traditional feed-forward layers, MoE introduces multiple expert modules where only a subset is activated (routed) at a time. This increases the total parameter count while keeping actual computation efficient, dramatically expanding training capacity.
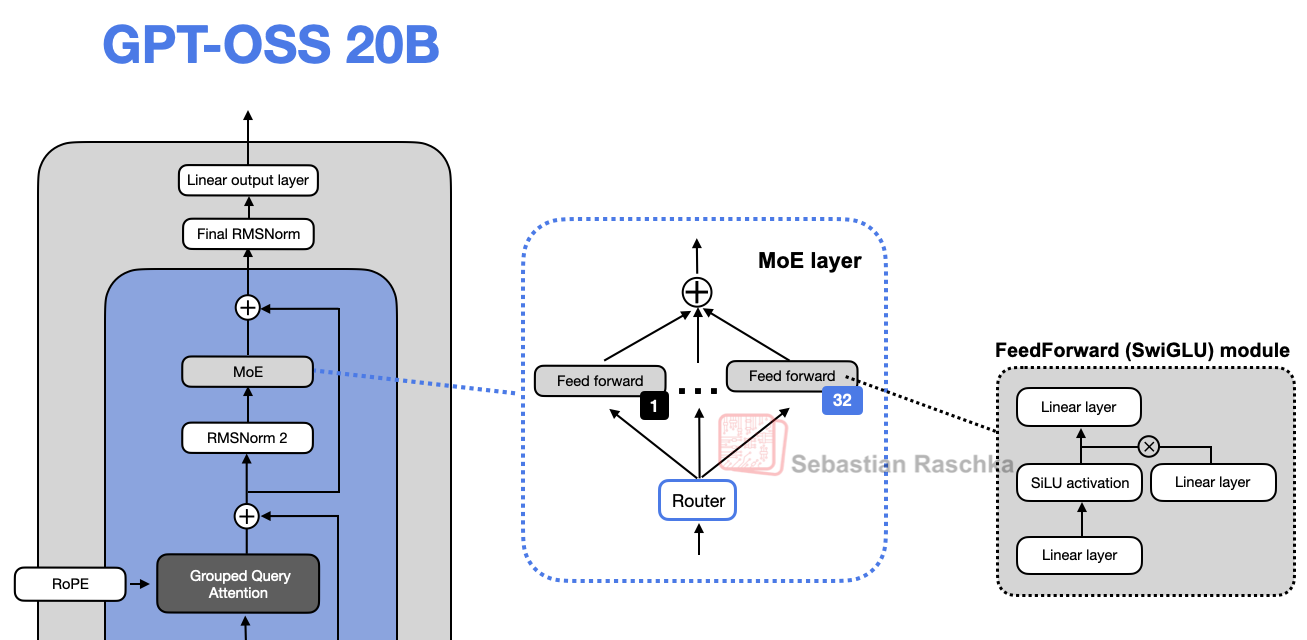
"Interestingly, in most MoE models, expert weights account for over 90% of the total model parameters."
3-2. GQA (Grouped Query Attention)
GQA is an efficient attention mechanism where multiple query heads share key/value pairs, reducing memory usage and computation.
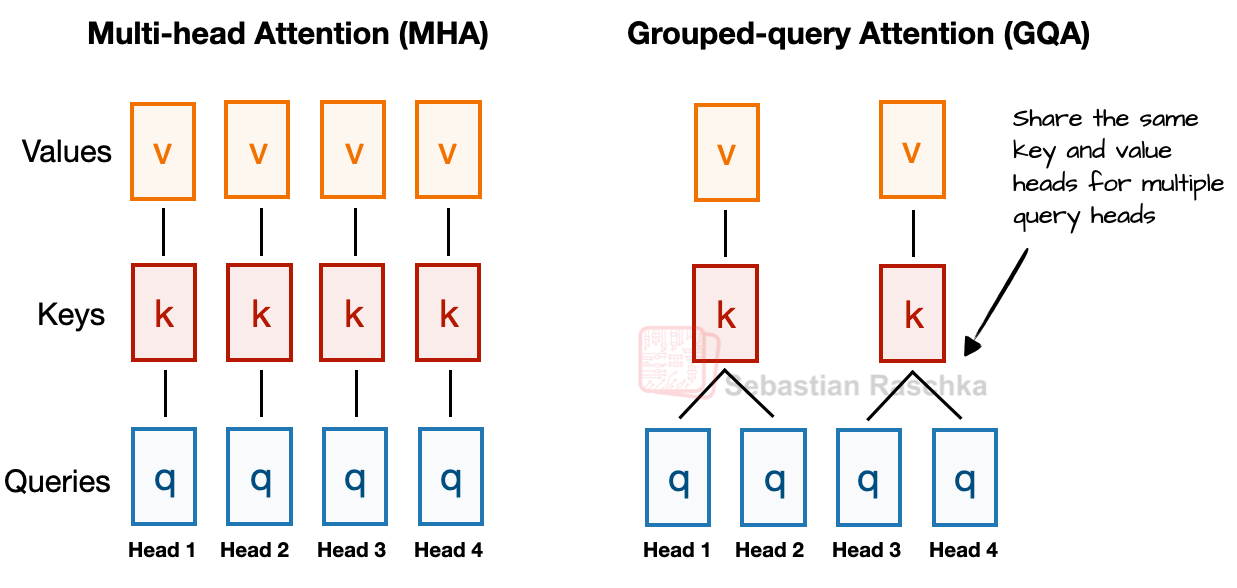
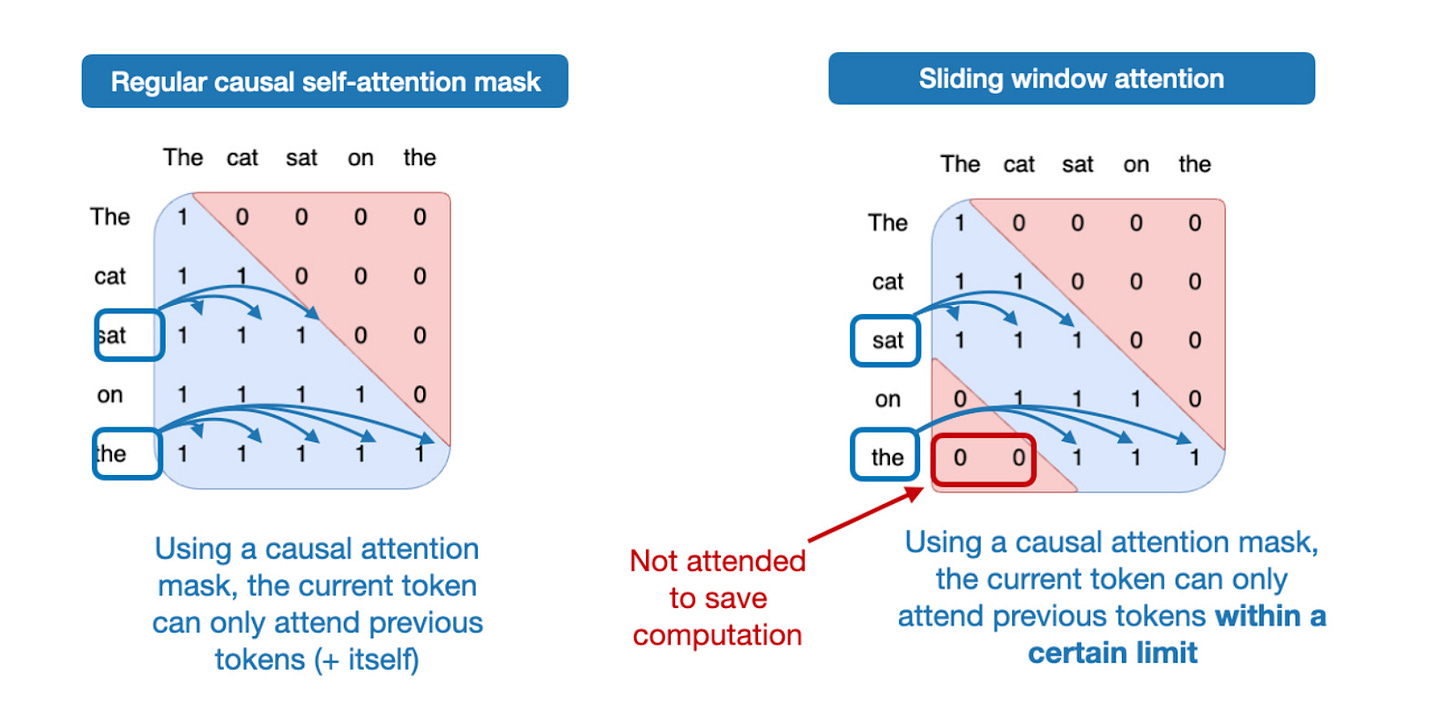
3-3. Sliding-Window Attention
Sliding-window attention, popularized by Mistral and others, restricts context to a 128-token window every other layer, dramatically reducing computation.
"gpt-oss doesn't use sliding window on every layer, but alternates -- one out of every two layers uses restricted attention to maximize efficiency."
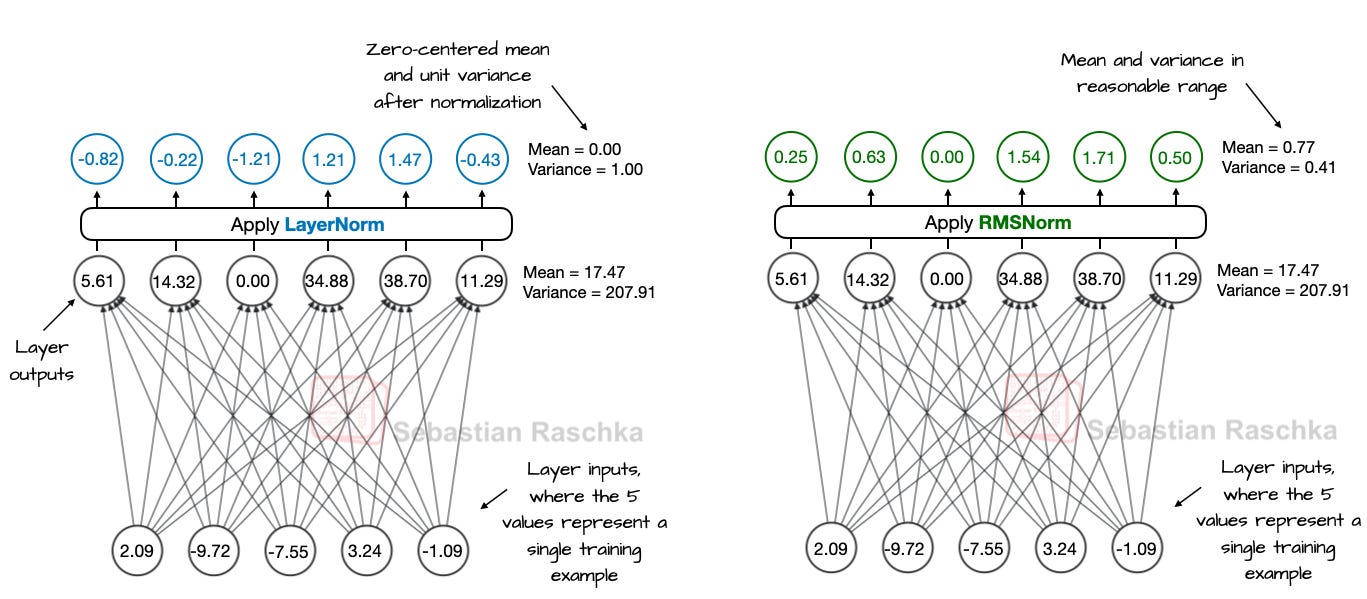
3-4. Introduction of RMSNorm
For all layer normalization, RMSNorm has been adopted instead of LayerNorm, as it requires less computation and is more GPU-efficient. It has become the de facto standard in modern LLMs.
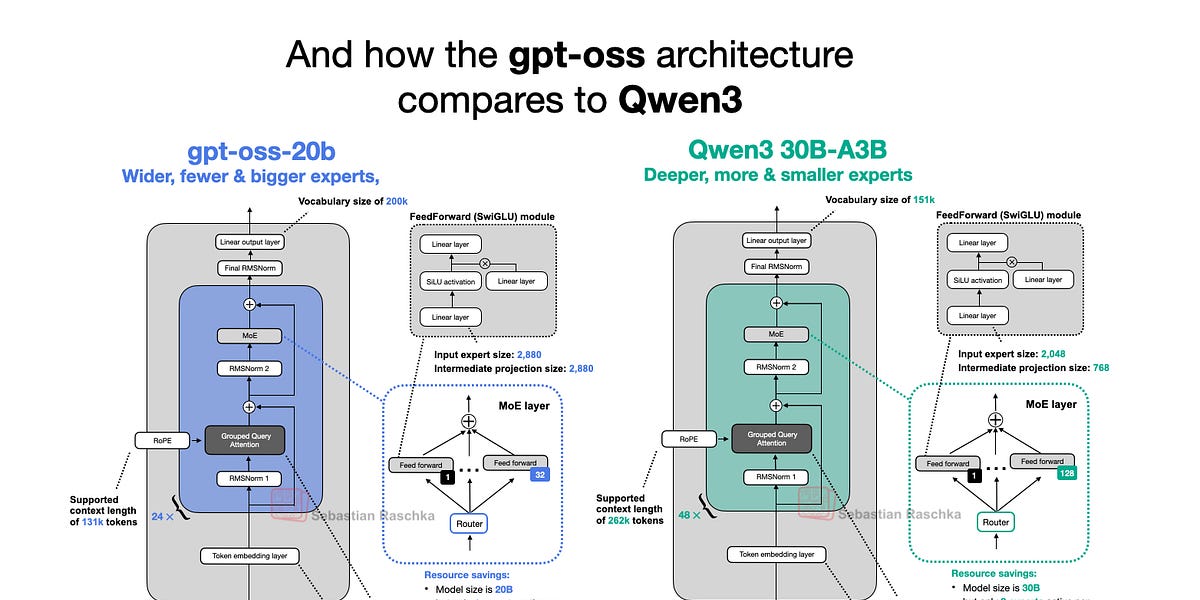
4. gpt-oss vs Qwen3: Deep and Narrow vs Shallow and Wide
Comparing with Qwen3, released in May 2025, provides a concrete look at recent LLM architecture trends.
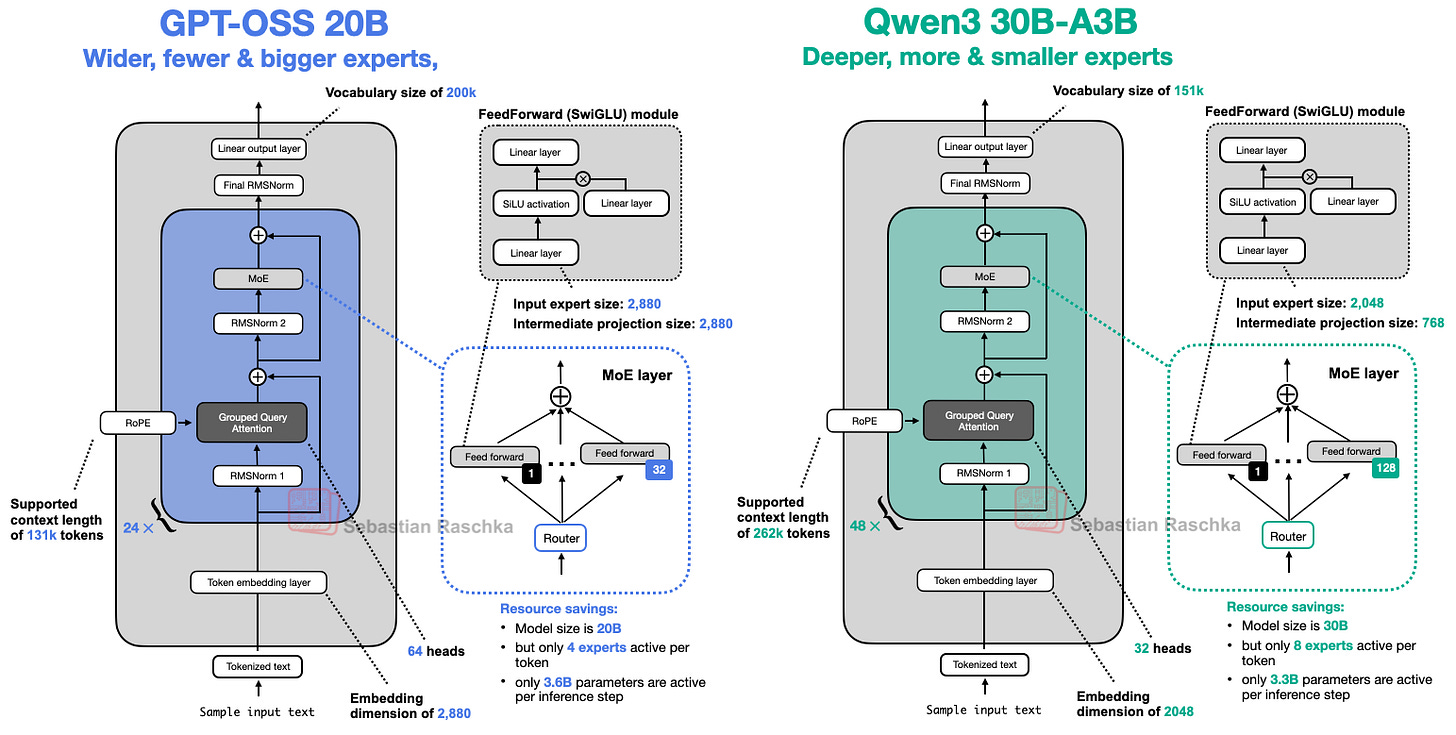
- Qwen3 has a deep structure with 48 blocks, while gpt-oss has a wide structure with 24 blocks (embedding dimension 2880 vs 2048, and larger expert sizes).
- Qwen3 has far more experts in total, but each individual expert in gpt-oss is larger.

"Deeper models are more flexible but harder to train (gradient explosion/vanishing), while wider models are more efficiently parallelized and faster at inference."
In fact, according to experiments in the Gemma2 paper, a "wider" structure achieved slightly better scores given the same parameter count.
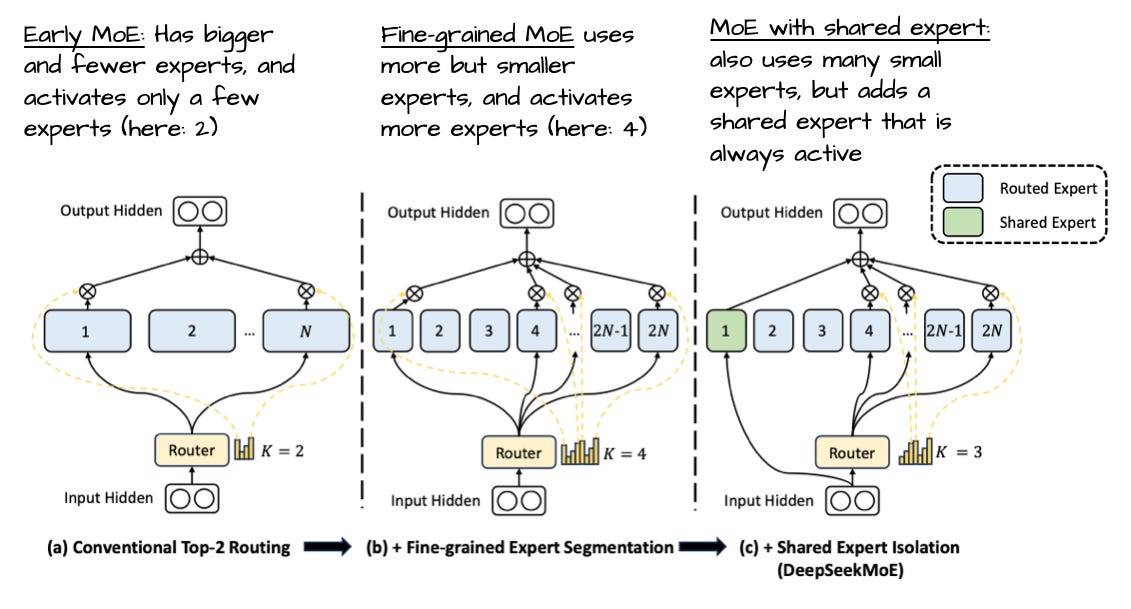
Moreover, the recent LLM trend is to increase the number of experts while shrinking each expert's size (see DeepSeekMoE).
5. Finer Details: Attention Bias, Sink, Licensing/Release Policies, and More
Some interesting smaller details are also covered.
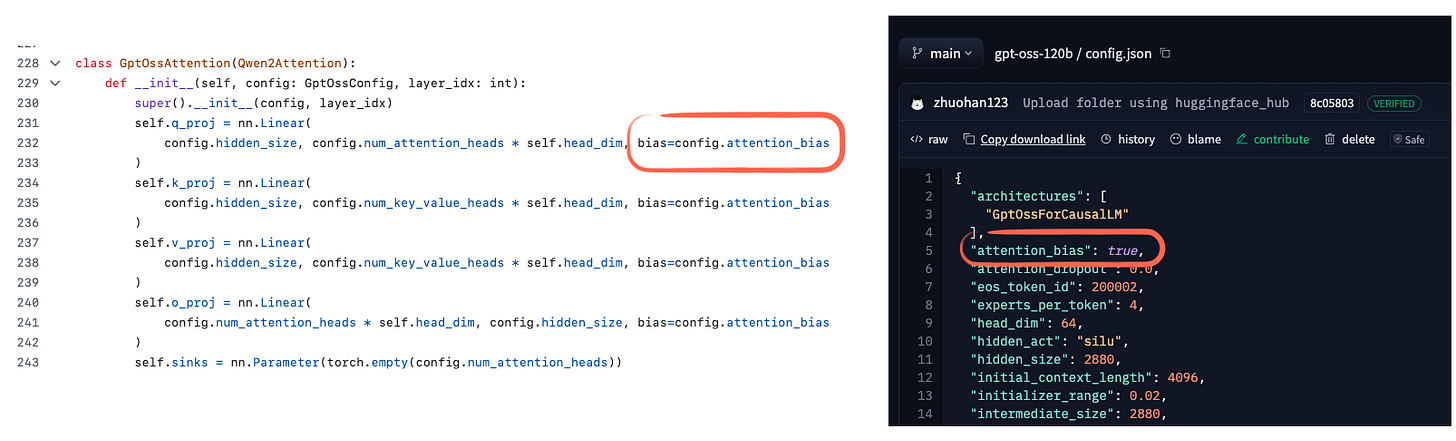
- gpt-oss reintroduced Attention bias (bias in key and value projections) for the first time since GPT-2, though recent papers show the effect is negligible.
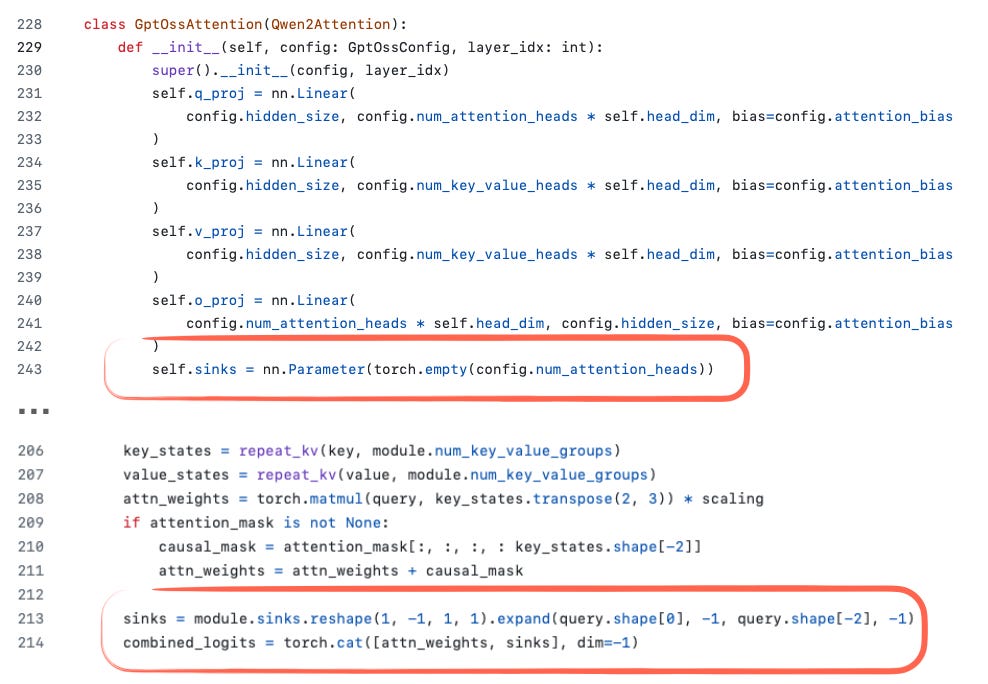
- Attention Sink is used to preserve certain information in long contexts -- rather than using actual input tokens, it applies a per-head learned bias logit added to the attention score.
Meanwhile, both gpt-oss and Qwen3 are released under the Apache 2.0 license (open-weight, not strictly open-source), with no usage restrictions.
"In the strict sense, gpt-oss is an open-weight model. That is, the weights and inference code are public, but the training code and datasets are not."
6. Training and Usage: Advanced Reasoning and MXFP4 Optimization
6-1. Training Information and Configuration
The gpt-oss series was trained with enormous compute (2.1 million GPU-hours on H100s) and cutting-edge source data (primarily English, STEM, coding, and general knowledge).
"The training compute for gpt-oss is comparable to DeepSeek V3, but the exact training data scale has not been disclosed."
6-2. Reasoning Effort Scaling
A particularly interesting feature is the ability to control response length and accuracy at inference time by specifying "Reasoning effort: low/medium/high".
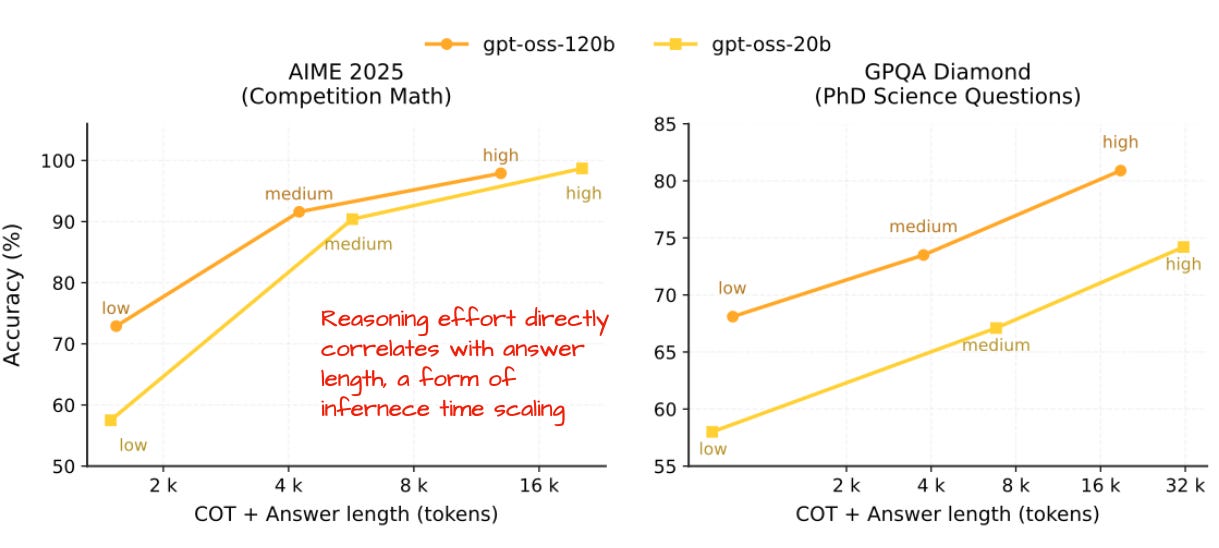
"For simple knowledge questions, typo corrections, and the like, you can lower the reasoning effort to save resources."
Note that Qwen3 also had a similar toggle, but recently separated the functions due to performance degradation issues.
6-3. MXFP4 Optimization
Even the massive gpt-oss-120b model can run on a single 80GB H100 thanks to MXFP4 quantization optimization.
- The 20B model only needs a latest RTX 50-series with 16GB, while hardware without MXFP4 support sees a significant increase in memory usage.
- In practice, the 20B model runs comfortably at around 13.5GB even on a Mac mini with ollama.
7. Performance and Limitations: Benchmarks, Usability, and Future Outlook
7-1. Benchmarks and Real-World Experience
Third-party benchmark results for gpt-oss are still limited, but based on official announcements and hands-on impressions, it demonstrates considerable competitiveness (especially on reasoning tasks!).
"As some users have noted, gpt-oss has a tendency toward hallucination, but this is likely because the reasoning-focused training came at the cost of some factual knowledge retention."
The open-weight LLM trend is increasingly intersecting with external tool integration (search, computation, etc.), which could accelerate the shift toward prioritizing "reasoning ability over fact memorization."
7-2. OpenAI, GPT-5, and Comparisons
Shortly after gpt-oss, OpenAI also announced GPT-5. What's particularly interesting is that this open-weight release shows benchmark performance close to their own high-end commercial models.
"Some called it overhyped, but this open-weight model release is genuinely powerful, and it shows that the gap between open and commercial models has narrowed significantly."
In Closing
The architectural evolution from GPT-2 to gpt-oss, and then to Qwen3 and the latest GPT-5, demonstrates a process of meticulous optimization in efficiency, reasoning capability, and practical utility -- all while preserving the essence of Transformer-based LLMs. In the era of open-weight LLMs, anyone can freely experiment with high-performance models locally or in the cloud, and pursue research and application development. The future of this field certainly looks promising.
"Now is truly a great time to work with open-weight and local models."
If you found this article helpful, consider supporting independent research through various channels (books, video courses, subscriptions, etc.)!