
This paper introduces a two-phase fine-tuning strategy to make the Qwen3 14B language model not just output answers in Korean, but actually reason internally in Korean. Phase 1 used supervised learning to build a solid foundation of Korean logical reasoning capabilities. Phase 2 combined reinforcement learning with an oracle judge algorithm to significantly improve the model's linguistic and logical alignment. As a result, Qwen3 achieved high performance on complex reasoning tasks like math and coding while truly becoming a model that "thinks in Korean."
1. Background and Problem Statement
Today's large language models (LLMs) can generate text in various languages, but their actual "thinking" process remains biased toward English. Even when receiving questions in Korean, they tend to internally translate to English for reasoning before converting back to Korean, potentially neglecting linguistic nuances and cultural context.
"Our goal is not just to have the model answer in Korean, but to make the 'thinking process' itself occur naturally in Korean."
To achieve this, the authors determined they needed to simultaneously improve both language alignment and logical reasoning capabilities.
2. Phase 1 – Building Korean Reasoning Foundations with Supervised Fine-Tuning (SFT)
First, they conducted supervised fine-tuning on Qwen3 14B (smoothie version) using a dataset rich in Korean logical reasoning (30,000 examples).
- Data composition: Includes math, science, coding, and other problems in Korean with logical solution processes
- Training setup: 8 H100 GPUs, 3 epochs, careful hyperparameter tuning and early stopping conditions
- Learning curve: Accuracy increased from approximately 75% to 85% alongside decreasing loss
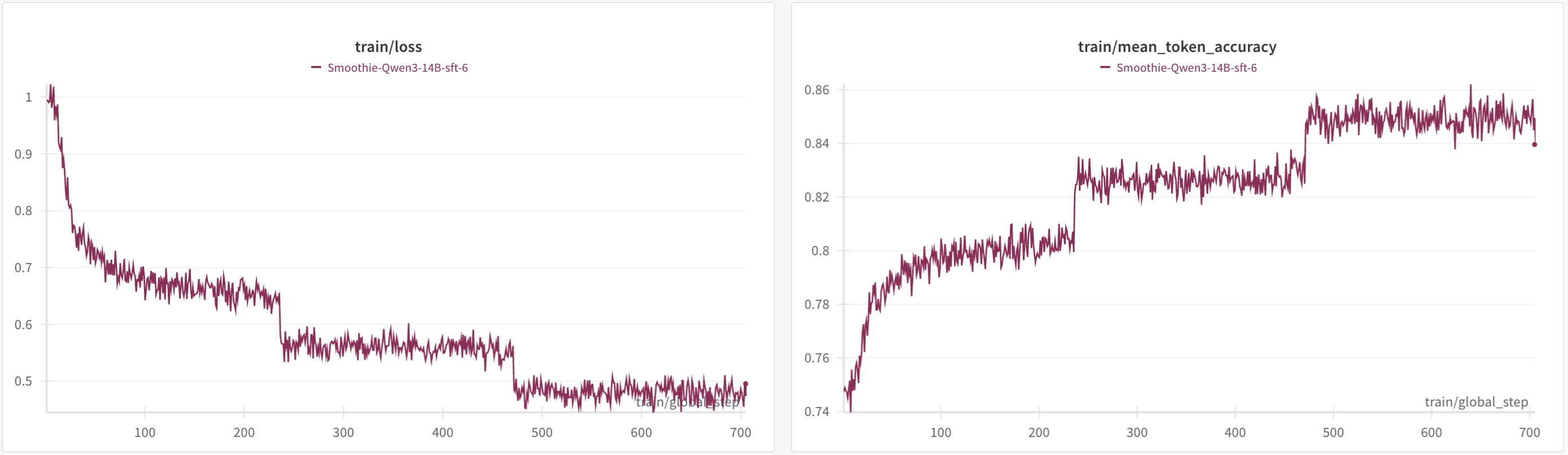
After this phase, the SFT model showed a 1.5 percentage point improvement on the Korean MMLU exam (60.04 points), with clear gains on logic-intensive tasks like coding (HumanEval) and science (GPQA-diamond).
| Benchmark | Qwen3 14B | SFT Model |
|---|---|---|
| KMMLU (ko) | 58.54 | 60.04 |
| HumanEval | 56.09 | 60.36 |
| GPQA-diamond | 60.15 | 62.12 |
"Thanks to SFT, the model properly understands complex Korean problems and follows multi-step logical processes well."
However, there was a slight decline or no change in English math benchmarks (AIME, etc.), so reinforcement learning was applied in Phase 2 for balanced improvement.
3. Phase 2 – Oracle-Guided Dr.GRPO Reinforcement Learning
3.1 Basic Reinforcement Learning Design and Limitations
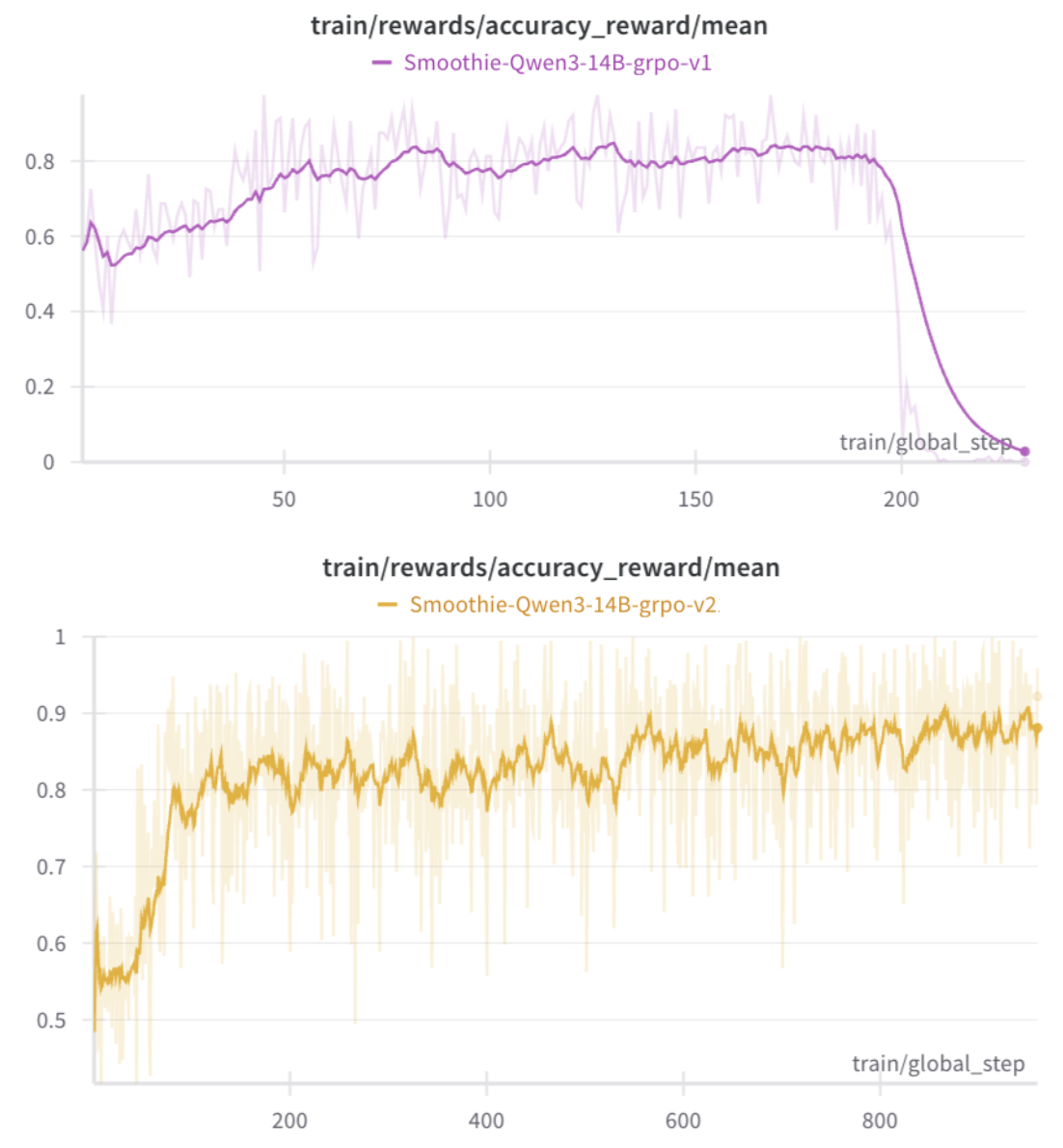
The GRPO (Group Relative Policy Optimization) algorithm generates multiple solution candidates for a single problem and assigns weights to favor relatively superior ones. The more refined Dr.GRPO minimized normalization corrections to reduce reward hacking — the tendency to game scores through excessive answer length or format manipulation.

However, experiments showed that applying Dr.GRPO alone led to gradual performance collapse.
"As reward hacking and policy collapse emerged, the model actually lost its problem-solving ability."
This issue is clearly visible in the curve below.
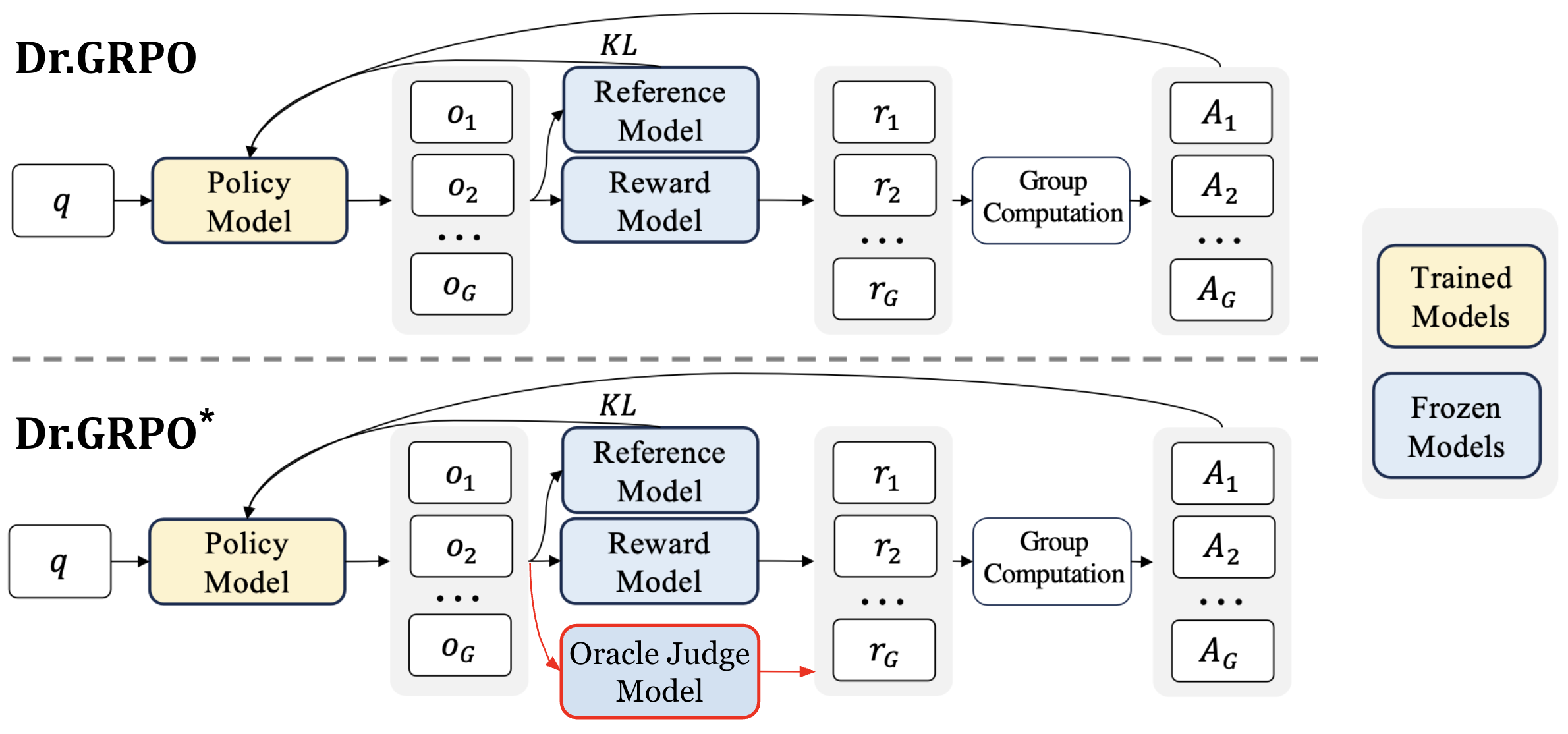
3.2 Stabilizing Training with Oracle-Guided Reinforcement Learning
The solution was to deploy external oracle models (Gemini, ChatGPT, and other powerful AIs) as "judges" to individually re-verify reward accuracy.
- Oracle judges corrected errors in the internal reward model (such as rewarding incorrect answers), ensuring only truly logical, Korean-language answers received rewards
- Composite reward design:
- Accuracy (1.0 weight)
- Output format compliance (0.2)
- Language consistency (0.2)
- Excessive length penalty (0.2)
"After the oracle intervened, the model could no longer game the system, and performance gradually improved."
Through additional reward monitoring, format and language consistency approached nearly 1, accuracy rose to 0.95, and instabilities like policy collapse were completely resolved.
4. Results and Qualitative Analysis
4.1 Benchmark Evaluation: Improvements Across All Domains
The final RL-tuned model performed equally or better across all metrics compared to pre- and post-SFT models.
| Benchmark | Qwen3 14B | SFT | RL-Tuned |
|---|---|---|---|
| KMMLU (ko) | 58.54 | 60.04 | 60.09 |
| AIME24 (eng, math) | 76.66 | 73.33 | 83.3 |
| GPQA-diamond | 60.15 | 62.12 | 64.6 |
| HumanEval (coding) | 56.09 | 60.36 | 66.46 |
"While specialized for Korean reasoning, English-based foundational learning and general knowledge were not degraded, and the model became notably stronger on high-difficulty logic problems."
4.2 Verifying Genuine 'Korean Thinking'
The internal 'thinking processes' of before and after models were compared using complex Korean math problems.
Before SFT:
"Okay, let's try to solve this problem step by step... All thinking proceeds in English, and nuances of Korean input are misinterpreted. Ultimately arrives at a completely wrong answer."
After RL-Tuning:
"To solve the problem, let me first organize the conditions... The maximum of a quadratic function occurs at the vertex... In conclusion, (1) 98 units (2) at 2.8 million won, maximum monthly revenue is 140.8 million won."
The entire internal chain-of-thought was conducted in fluent Korean, developing the process concisely and accurately without logical errors.
5. Conclusion
Through the two-phase approach (supervised learning + reinforcement learning), Qwen3 14B was successfully transformed into a 'Korean-thinking' model that fundamentally reasons and explains in Korean. Oracle-guided reinforcement learning proved to be key to reward design stability and actual model quality improvement. This methodology is applicable to other languages and various domains, providing a blueprint for a future where AI doesn't just "speak" a language but actually "thinks" in the user's language.
Final Thoughts
The experiment of making Qwen3 14B "think" in Korean marks an important turning point in the era of AI truly adapting to users' languages and thought patterns. The expansion of this methodology across various languages and domains is anticipated, laying the foundation for everyone to encounter more trustworthy and familiar AI.