
Meta has uncovered the inefficiency that occurs when large language models (LLMs) repeat the same work during complex reasoning, and has introduced a new approach called "behavior handbooks" to overcome it. By storing and reusing reasoning methods as modular "behavior" units, the approach can significantly improve both reasoning efficiency and accuracy. The findings are presented step by step -- from experimental design and results to meaningful implications for real-world applications.
1. The Problem -- Inefficiency in AI Reasoning
Meta discovered a fundamental problem: LLMs repeatedly perform identical steps within long chains of thought. A representative example is how, when adding fractions with different denominators, the model unnecessarily re-explains the process of finding a common denominator multiple times.
"Large language models keep redoing the same work inside long chains of thought. For example, when adding fractions with different denominators, the model often re-explains finding a common denominator."
This unnecessary repetition generates more tokens (text fragments) and increases processing time, leading to higher costs and lower accuracy.
2. The Solution -- The Concept and Structure of Behavior Handbooks
The core of Meta's proposed solution is to create reusable reasoning units called "behaviors" and store them as a form of procedural memory in "behavior handbooks." Unlike conventional RAG (Retrieval-Augmented Generation) systems that store factual knowledge, this approach stores processes and procedures (methodology).
"A behavior is a reusable procedure represented by a simple name and instructions, such as 'inclusion-exclusion principle.' A behavior handbook is a repository that stores step-by-step guidelines for how to do things. This differs from how RAG stores facts."
Below is an actual handbook image.
3. Behavior Curation -- The Model Learns from Itself
The first step in building a behavior handbook works as follows:
- Problem presentation and solving: An LLM (here, LLM A) receives a math problem and solves it using standard methods.
- Reflecting on the solution process: The model reviews its own solving process and asks itself, "What were the repetitive or reusable steps here?" Behaviors are extracted through this procedure.
"The model asks itself, 'What were the recurring, separable steps?' and derives behaviors from them."
The actual workflow image is also included.
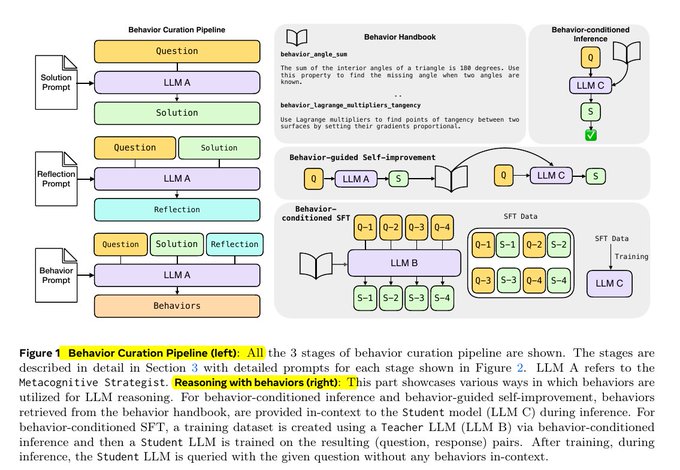
4. Behavior-Conditioned Reasoning -- Problem-Solving with the Handbook
Once the handbook is built, in test scenarios the model (student) retrieves only the most relevant behaviors along with the problem and explicitly references them during reasoning.
- For MATH problems, behaviors are selected by topic tags; for AIME (American Invitational Mathematics Examination) problems, embedding search (BGE-M3 model + FAISS) selects the 40 most relevant behaviors.
- This shortens the reasoning chain while maintaining or improving accuracy. Performance improves even further when the token budget increases (longer context).
"At test time, the student (model) receives the problem along with a small set of extracted behaviors and explicitly references them during reasoning."
The related structure is shown below.

5. Behavior-Based Self-Improvement and Comparative Experiments
This new behavior-centric approach was also proven superior to the "critique-and-revise" baseline.
- The model first solves a problem, extracts behaviors on its own, then uses those behaviors as hints to re-attempt the problem.
- As the token budget increases (allowing longer solutions), accuracy gains widen, reaching up to approximately 10 percentage points higher accuracy than the baseline.
"The same model extracts behaviors from its initial solution, then uses them as hints for the next attempt. This method outperforms critique-based re-solving in most conditions. The gap grows as more tokens become available."
6. Handbook Retrieval and Scalability
The handbook stores both problems and behaviors as embeddings in a FAISS index, enabling very fast search and scalability.
- Even as the number of domains grows, only a small set of behaviors is actually used at a time, keeping context burden low
- The library can keep growing while the context size the model references remains effectively limited
7. Cost and Efficiency
The behavior handbook approach does add input tokens (behavior instructions), but output tokens (actually generated responses) are significantly reduced. Since generation is the slow and expensive part, overall cost actually decreases, and latency is also shortened.
- Across many APIs, input costs are cheaper than output costs, so total expenditure can also decrease
"Even though behavior input tokens increase, output tokens are drastically reduced. Since output generation is the slowest and most expensive part, overall cost drops and response speed improves."

8. Additional Discussion and Reactions
This research generated diverse reactions in the industry.
"The fact that models repeat basic steps in complex reasoning processes is entirely logical."
"We should use RL (reinforcement learning) with a penalty per token needed to reach the final answer to make models learn faster."
"These results are the kind of bold idea that could only come from Meta's research lab."
"Behaviors + signals > improvisation. Memory, habits, and routines are the sparks of AGI. Let's see who achieves resonance first."
Conclusion
Meta's behavior handbook approach offers a practical solution for evolving how LLMs "think" about complex problems. By modularizing repetitive reasoning steps for reuse, it experimentally demonstrates meaningful improvements in accuracy, speed, and cost. This approach is expected to find applications across an increasingly wide range of AI domains.