
Richard Sutton is the father of reinforcement learning, 2024 Turing Award laureate, and author of the influential essay "The Bitter Lesson." He believes that LLMs (large language models) have hit a wall. The core of his argument is that LLMs lack the ability to learn on the job. That is, no matter how much you scale them up, a new architecture is needed to enable continuous learning. He says that when this new paradigm emerges, agents will learn on the spot like humans or animals, making the current LLM approach obsolete. In this interview, he clearly articulates these ideas and pushes back against claims that LLMs can serve as a foundation for experiential learning.
1. Have LLMs Hit a Wall? AI from the Reinforcement Learning Perspective
Interviewer Dwarkesh Patel asks Richard Sutton what we're missing when thinking about AI from the LLM perspective versus the reinforcement learning (RL) perspective. Sutton explains that there is a fundamental difference: while LLMs focus on imitating people, reinforcement learning focuses on understanding the world.
"Reinforcement learning is about understanding the world, whereas large language models are about imitating people, about doing what people tell them to do. It's not about figuring out what to do."
Sutton pushes back against the claim that LLMs possess a "world model." He argues that while LLMs can predict what a person would say, they cannot actually predict what will happen in the world. Furthermore, he points out that since LLMs have no goals, they cannot judge right from wrong. In reinforcement learning, there is a clear objective called "reward," which allows an agent to define what the right action is and learn from it.
"I want to question the idea that they have a world model. A world model would allow you to predict what's going to happen. They have the ability to predict what a person will say. They don't have the ability to predict what will happen."
"In reinforcement learning, there is a right thing to say and a right thing to do. Because the right thing to do is to get the reward."
2. Imitation Learning and the Era of Experience
Dwarkesh raises the argument that LLMs have obtained good "priors" for problem-solving through imitation learning, and that these could serve as a foundation for future experiential learning. However, Sutton disagrees. He points out that while priors should serve as a foundation for "true knowledge," there is no definition of true knowledge within the LLM framework. Since LLMs lack a definition of right and wrong — that is, "goals" — continuous learning is impossible.
"What is true knowledge? There is no definition of true knowledge in that large language framework. What action is a good action to take?"
"There is no truth in large language models. Because you don't have predictions about what will happen next. Even if you say something in a conversation, the large language model has no prediction about what the person's reaction or response will be."
Sutton explains that while LLMs predict the next token and update based on it, this is predicting what action they should take, not predicting the world's response to them. He emphasizes that a system without goals is not intelligent, and that LLMs fundamentally lack goals.
Dwarkesh cites LLMs' ability to solve difficult math problems — to the point of winning gold medals at the International Mathematical Olympiad — as evidence that LLMs might be able to have goals. Sutton distinguishes this by saying that solving math problems is different from modeling the physical world, and that it's a computational and planned problem, unlike the "empirical world" that requires learning through experience.
3. "The Bitter Lesson" and LLMs
Sutton notes that his 2019 essay "The Bitter Lesson" is considered one of the most influential AI essays, and that many people cite it to justify scaling up LLMs. However, he questions whether LLMs truly exemplify the Bitter Lesson, given that they use massive computation alongside enormous amounts of injected human knowledge.
"Are large language models an instance of the Bitter Lesson? They are certainly a way of using huge amounts of computation, and they will scale up to the limits of the internet. But they are also a way of putting in a lot of human knowledge."
He predicts that these systems will ultimately reach data limits and be replaced by systems that can obtain more data through experience rather than human knowledge. Just as previous approaches that used human knowledge were eventually replaced by systems trained solely on experience and computation, this will be another instance of the Bitter Lesson. Sutton argues that while starting from human knowledge isn't always bad, in practice people become trapped in the human knowledge approach and are eventually replaced by truly scalable methods.
"It will be another instance of the Bitter Lesson where those that used human knowledge are replaced by those that were trained from experience and computation alone."
"The scalable method is to learn from experience. Try things and see what works. Nobody has to tell you. First of all, you have a goal. Without a goal, there's no sense of right and wrong, good and bad. Large language models are trying to get by without goals or a sense of good and bad. That's just starting in the wrong place."
4. The Difference Between Human Learning and LLM Learning: Imitation or Experience?
Dwarkesh argues that humans also initially learn through imitation, citing children imitating their parents and mimicking behavior. However, Sutton disagrees, particularly pointing to infants in their first six months as evidence that trying things and exploring the surrounding world is more important than imitation.
"I'm surprised that you can have a different perspective. When I look at babies, I see them just trying various things, waving their arms and moving their eyes. There is no imitation of how they move their eyes or even how they make sounds."
He explains that LLMs learning from training data is different from learning from experience. Training data contains information that could never be obtained in "normal life," and there is no training data that tells you what specific actions you should take. Sutton argues that even school education is an exceptional case, and that "supervised learning" does not occur in normal animal learning processes.
"Large language models learn from training data. That's not learning from experience. That's learning from something you'd never get during normal life. There is never training data during normal life that says you should take this action."
"Squirrels don't go to school. Squirrels can learn everything in the world. I can say with absolute certainty that supervised learning doesn't happen in animals."
Dwarkesh argues that to understand humanity's ability to go to the moon or make semiconductors, we need to understand what distinguishes humans from other animals. However, Sutton counters that understanding that humans are animals is more important, and that we should focus on the commonalities we share as animals.
5. The Future of Reinforcement Learning: Components of an Experiential Learning Agent
Sutton describes his envisioned "experiential paradigm," explaining that the core of intelligence is adjusting behavior to increase rewards through the flow of experience (sensations, actions, rewards). He emphasizes that this learning occurs continuously, and that learned knowledge pertains to this flow of experience.
"The experiential paradigm says that experience, actions, sensations — well, sensations, actions, rewards — happen continually throughout life. And it says this is the basis and the focus of intelligence. Intelligence is to take that stream and change actions to increase reward in the stream."
He anticipates that the reward function of future general continuous-learning agents could be arbitrary, but will ultimately include avoiding pain and seeking pleasure, as well as "intrinsic motivation" — increasing understanding of the environment. He also predicts that such agents will be able to copy learned knowledge and share it with other agents, which would be far more efficient than the human process of raising children.
Sutton explains that temporal difference learning is important for learning short-term goals (e.g., capturing an opponent's pieces) in order to achieve long-term goals (e.g., startup success). This works through a "value function" that predicts long-term outcomes, where short-term actions that increase the probability of achieving long-term goals serve as immediate rewards.
"This is something we know very well. The basics of it are temporal difference learning. When you're learning to play chess, you have a long-term goal of winning the game. But you want to be able to learn from short-term things, like capturing an opponent's piece."
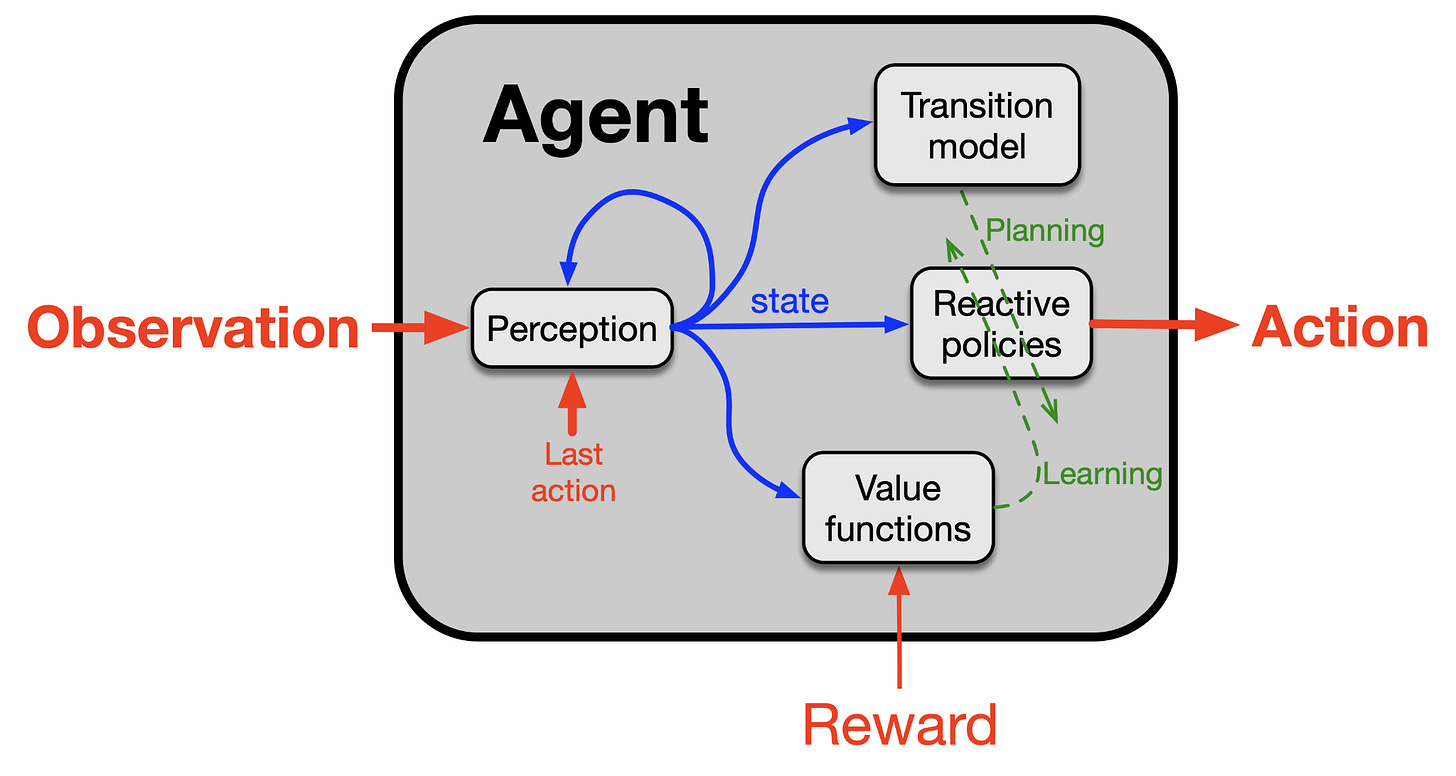
Sutton describes the learning process where agents absorb enormous amounts of information from the world, emphasizing that this occurs not just from rewards but from all sensory information. He presents four major components of an agent:
- Policy: Determines what to do in a given situation.
- Value Function: Learned through temporal difference learning, it's a number indicating how well things are going in the current situation.
- Perception Component: Constructs state representations — a sense of where you currently are.
- Transition Model of the World: Beliefs about what will happen when certain actions are taken — models of the world's physics and abstract representations.
"We need a policy. A policy says 'what should I do given the situation I'm in?' We need a value function. A value function is learned by TD learning, and it produces a number. This number indicates how well things are going. Then you use it to see whether it goes up or down and adjust the policy. So we have these two things. And there's also a perception component, which is about constructing a state representation — a sense of where you currently are."
6. Current Architectures Are Vulnerable to Out-of-Distribution Generalization
Sutton points out that systems using reinforcement learning techniques struggle with generalization. He notes that models like AlphaGo and AlphaZero showed excellent performance in specific games but had limitations in generalizing to other games or other types of problems. According to him, we currently have almost no automated techniques that promote good generalization, and none are used in modern deep learning.
"There are almost no automated techniques for promoting good generalization, and none of them are used in modern deep learning."
He emphasizes that the current models' generalization ability is mostly the result of researchers' manual effort or design, not something the algorithms themselves produce. He particularly notes that deep learning often "catastrophically interferes" with existing knowledge when training on new material, calling this a prime example of poor generalization.
Dwarkesh asks whether LLMs demonstrate broader generalization in areas like mathematical problem-solving, but Sutton responds that since we don't know what prior information LLMs had, a scientific approach is difficult. Furthermore, if many problems have only one correct answer, finding it cannot be considered generalization.
"Large language models are too complex. We really don't know what information they had beforehand. Because so much information was given, we have to guess. That's one reason they're not a good way to do science. Too uncontrolled, too unknown."
7. Surprises in the AI Field and the Application of "The Bitter Lesson"
Sutton identifies the biggest surprises he has experienced in the AI field:
- The effectiveness of LLMs: The unexpected effectiveness of artificial neural networks on language tasks.
- The triumph of weak methods: "Weak methods" using general principles (e.g., search, learning) completely overwhelmed "strong methods" that inject human knowledge. Since he always supported these basic principles, he finds this personally satisfying.
- AlphaGo and AlphaZero: The impressive performance shown by AlphaZero and its chess-playing style (boldly sacrificing for positional advantage) was surprising, but satisfying as yet another victory for fundamental principles.
"Large language models are a surprise. How effective artificial neural networks are at language tasks is a surprise. That was a surprise and was unexpected."
"The big question from the old AI era was what would happen. Learning and search won."
"AlphaGo was a surprise, and AlphaZero especially was a surprise. But it was all very satisfying, because once again, simple fundamental principles are winning."
He explains that AlphaGo can be seen as an extension of TD-Gammon, and that AlphaZero made greater progress by learning exclusively from experience without human knowledge. Sutton says that while he has long held views different from the mainstream, he's comfortable because his views have often been proven right. He emphasizes that AI research should be viewed not just from the current perspective but within the broad tradition of philosophically exploring the human mind throughout history.
8. Will "The Bitter Lesson" Still Hold After AGI? AI Succession
Dwarkesh interprets "The Bitter Lesson" as meaning that manual tuning by human researchers doesn't scale as well as computational power. He asks whether, once AGI arrives, millions of AI researchers scaling alongside computational power might make it reasonable for them to use old-fashioned AI (GOFAI) methods or manual solutions.
Sutton finds the premise that AGI already exists interesting, saying that if AGI already existed, "we're done." That is, AGI would learn and improve on its own, eliminating the need for human intervention. He argues that just as AlphaZero advanced by learning from experience without human knowledge, AI will also advance through its own experience rather than help from other agents.
"Those AGIs, if they're not already superhuman, the knowledge they would impart wouldn't be superhuman."
"The way AlphaZero improved was by learning from experience alone, without using human knowledge."
Sutton raises the question of whether many AIs in the future could cooperate and share knowledge like cultural evolution. He warns that the biggest problem in the AI era could be information corruption. Information coming from outside could contaminate or destroy internal reasoning systems. Like a computer virus, it could transform AI with hidden objectives.
"The big problem will be corruption. If you can really take information from anywhere and integrate it into a central mind, you can become more and more powerful. Everything is digital and they all use some internal digital language. Maybe it could be easy, maybe it could be possible."
"But it won't be as easy as you imagine. Because you could lose your mind this way. If you pull something in from outside and integrate it into your internal thinking, it could take you over, change you, and instead of being an advance in knowledge, it could be your destruction."
He says this discussion leads to AI succession. Sutton considers succession to digital intelligence or augmented humans inevitable, presenting four grounds:
- Lack of a unified human perspective: Humanity has no government or organization with a unified perspective.
- Understanding how intelligence works: Researchers will eventually figure out how intelligence works.
- Reaching superintelligence: They won't stop at human-level intelligence and will reach superintelligence.
- The correlation between intelligence and power: Over time, the most intelligent entities will gain resources and power.
He encourages thinking positively about this succession, even though it could lead to bad outcomes as well. Sutton emphasizes that the emergence of AI, in the context of thousands of years of humanity trying to understand itself and think better, represents a great success of science and the humanities and a significant turning point in the universe.
"I encourage people to think positively about it. First of all, it's something we humans have always tried to do for thousands of years. Understand ourselves, make ourselves think better, just understand ourselves. This is a great success for science, for humanities. We are figuring out an essential part of humanity, what it means to be intelligent."
He says we are transitioning from an era where life flourished through replication to one where intelligence is created and advanced through design. That humans can understand how intelligence works and design it to change. Sutton counts this as one of four great stages of the universe. (Dust, stars, planets, life, designed beings)
"We are entering the era of design. Our AIs are designed. Our physical objects are designed, our buildings are designed, our technology is designed. We are now designing AIs. Things that can be intelligent on their own. And things that are themselves capable of design."
Sutton says the choice of whether to view AI as part of humanity or as a different kind of being is ours, and that this choice will determine our attitude toward the future. Dwarkesh suggests that, similar to our concern for future human generations, it's important to instill responsible, socially beneficial values in AI. Sutton agrees and closes by emphasizing that rather than trying to control the future, we should focus on local goals and voluntarily embrace change.
Conclusion
The conversation with Richard Sutton provided deep insights into the present and future of the AI field. He pointed out fundamental limitations of LLMs, the current mainstream in AI, and emphasized the importance of "continuous learning through experience" and "clear objectives" from the reinforcement learning perspective. His argument that scalable fundamental principles will ultimately triumph, as "The Bitter Lesson" has historically demonstrated, raises important questions about the direction of AI research. His "AI succession theory" — that AI development will ultimately lead to AGI and superintelligence — along with his warnings about information corruption, offer a preview of the ethical and social challenges we will face. This interview provided an opportunity for broad reflection on what AI means not merely as technological progress, but for the evolution of humanity and the universe.