As of 2025, we trace the evolution of large language model (LLM) architectures chronologically from GPT-2 to DeepSeek-V3, Llama 4, and Kimi 2. While they may look similar on the surface, there have been many structural changes aimed at improving efficiency and performance. This article provides a friendly overview of each model's key architectural changes and their significance.
1. Seven Years of LLM Architecture: Same Foundation, Revolutionary Details
From GPT-2 (2019) to DeepSeek-V3 and Llama 4 (2024-2025), the basic structure hasn't changed dramatically, but incremental improvements in efficiency and performance have continued. For example, positional embeddings shifted from absolute to RoPE (Rotary Position Encoding), Multi-Head Attention (MHA) evolved into Grouped-Query Attention (GQA), and activation functions moved from GELU to SwiGLU.
"On the surface, they still look similar, but have there really been revolutionary changes, or are we just refining the same foundation?"
In reality, datasets, training techniques, hyperparameters, and many other factors affect performance, so architecture alone doesn't determine results. Nevertheless, examining what structural experiments LLM developers are conducting in 2025 remains highly informative.
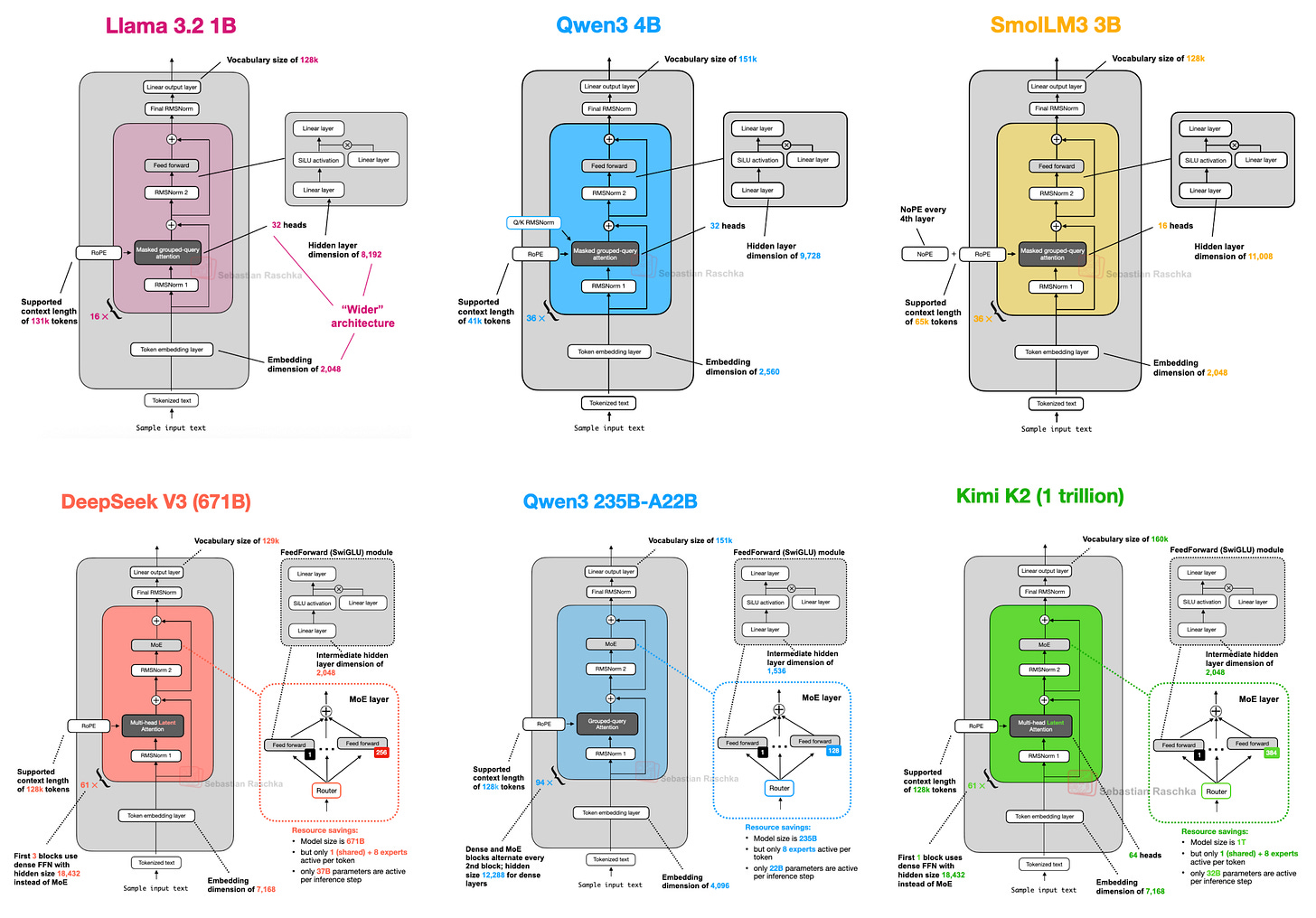
2. DeepSeek-V3/R1: Achieving Both Efficiency and Performance with MLA and MoE
DeepSeek R1, released in January 2025, is a reasoning-specialized model based on the DeepSeek V3 (announced December 2024) architecture. DeepSeek V3's two key structural features are:
- Multi-Head Latent Attention (MLA)
- Mixture-of-Experts (MoE)
2.1. MLA: A New Attention Mechanism That Maximizes Memory Efficiency
Traditional MHA computes keys and values separately for each head, while GQA reduces memory usage by sharing keys/values across multiple heads.
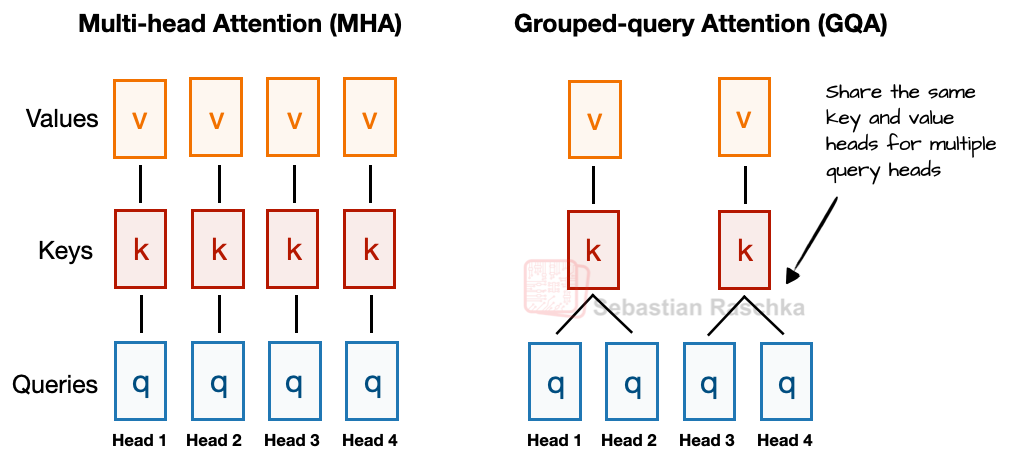
"The key idea behind GQA is that multiple query heads share keys/values, reducing parameter count and memory usage."
MLA goes a step further, compressing key/value tensors into a lower-dimensional space for storage in the KV cache, then restoring them to their original size during inference.

Experimental results show that MLA delivers better performance than GQA while also being more memory-efficient.

2.2. MoE: Massive Parameters, Efficient Inference
MoE replaces the FeedForward module in each transformer block with multiple "Experts." However, not all experts are used every time -- a router selects only a subset to activate.

For example, DeepSeek-V3 activates only 9 out of 256 experts (1 shared expert + 8 router-selected experts). This means total parameters are 671B (671 billion), but only 37B (37 billion) are used during actual inference, making it highly efficient.
"The shared expert is always activated for every token, preventing multiple experts from redundantly learning repeated patterns."

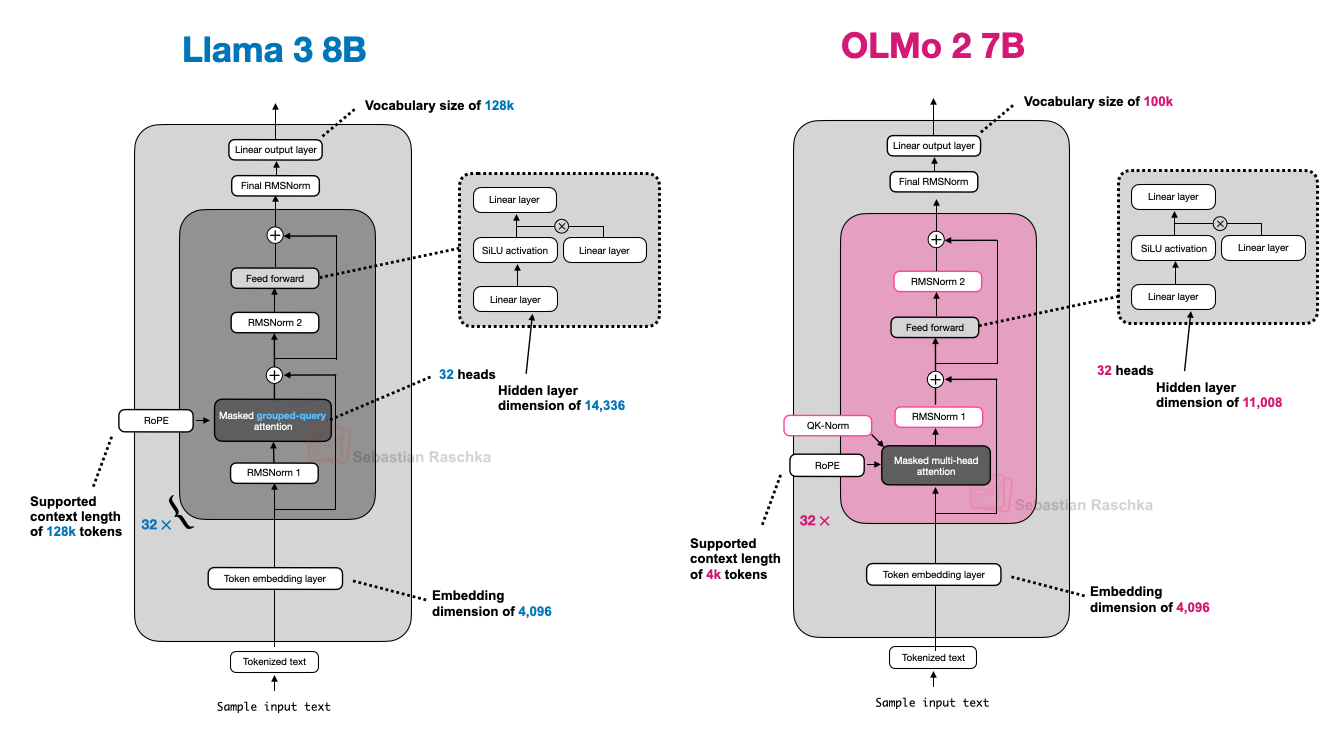
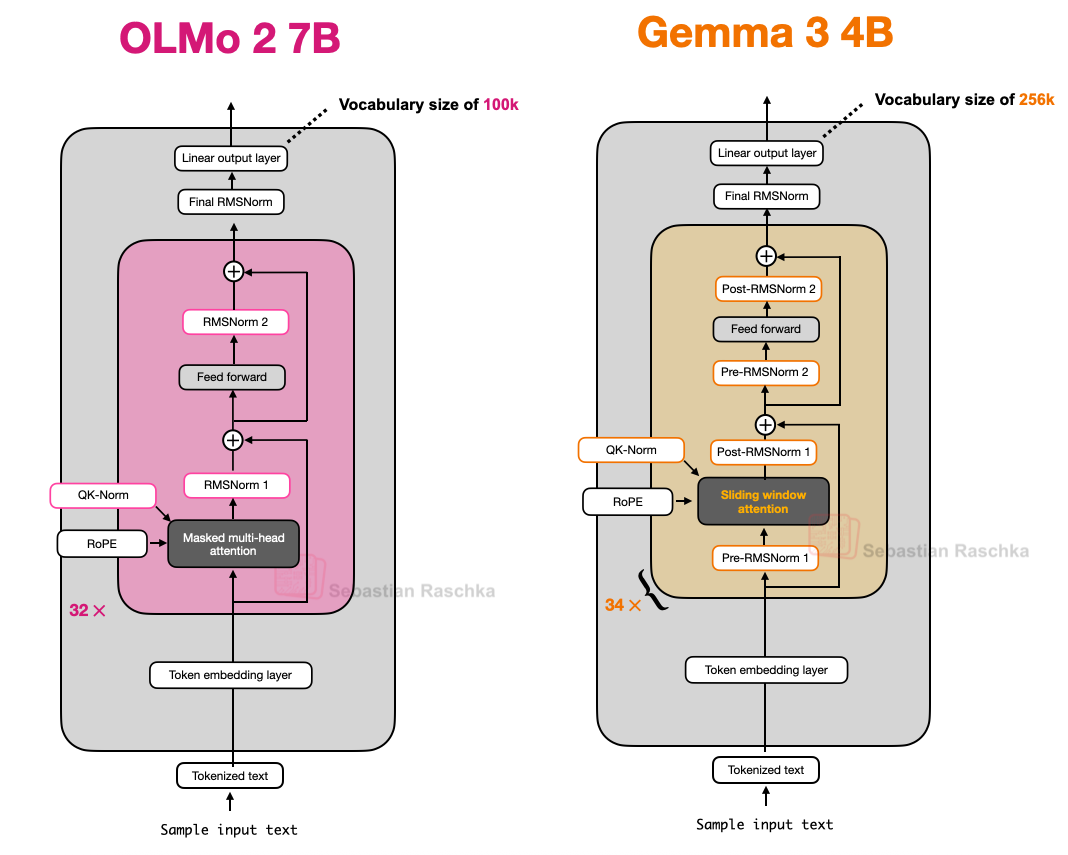
3. OLMo 2: Design Focused on Transparency and Stability
OLMo 2, developed by AI2 (Allen Institute for AI), features transparently published training data, code, and technical reports. While not top-tier in performance, its clean architectural design and transparency are major strengths.

3.1. RMSNorm and QK-Norm: Normalization Strategies for Stable Training
OLMo 2 uses RMSNorm and places the normalization layer differently from conventional models. Traditional GPT-style models use Pre-Norm (normalization then attention/FFN), while OLMo 2 adopts Post-Norm (attention/FFN then normalization).

"The reason for changing the normalization layer position is training stability."
In practice, the Post-Norm approach improves training stability.

Additionally, QK-Norm (query/key normalization) was introduced to apply RMSNorm within the attention mechanism for additional stability.
4. Gemma 3 & 3n: The Evolution of Sliding Window Attention and Efficiency
Gemma 3 (Google) introduces sliding window attention to significantly reduce KV cache memory usage.

4.1. Sliding Window Attention: From Global to Local
Traditional attention lets every token attend to every other token (global), while sliding window attention only attends within a fixed range (window), making it local.

Gemma 3 mixes sliding window (local) and global attention at a 5:1 ratio, also reducing the window size from 4096 to 1024. Experimental results show that memory efficiency is maximized with no performance degradation.

4.2. Unique Normalization Layer Placement
Gemma 3 places RMSNorm both before and after attention/FFN (Pre-Norm + Post-Norm), pursuing both stability and efficiency.
4.3. Gemma 3n: Mobile Optimization and PLE
Gemma 3n uses a Per-Layer Embedding (PLE) technique that keeps only some parameters on the GPU while loading the rest from CPU/SSD on demand, enabling efficient operation even on mobile devices.

5. Mistral Small 3.1: Optimized for Fast Inference
Mistral Small 3.1 24B is faster than Gemma 3 27B while delivering better performance on multiple benchmarks. The key lies in a custom tokenizer, reduced KV cache, and fewer layers, all minimizing inference latency.

6. Llama 4: MoE Goes Mainstream and Comparison with DeepSeek-V3
Llama 4 also adopts an MoE architecture, showing a very similar structure to DeepSeek-V3.
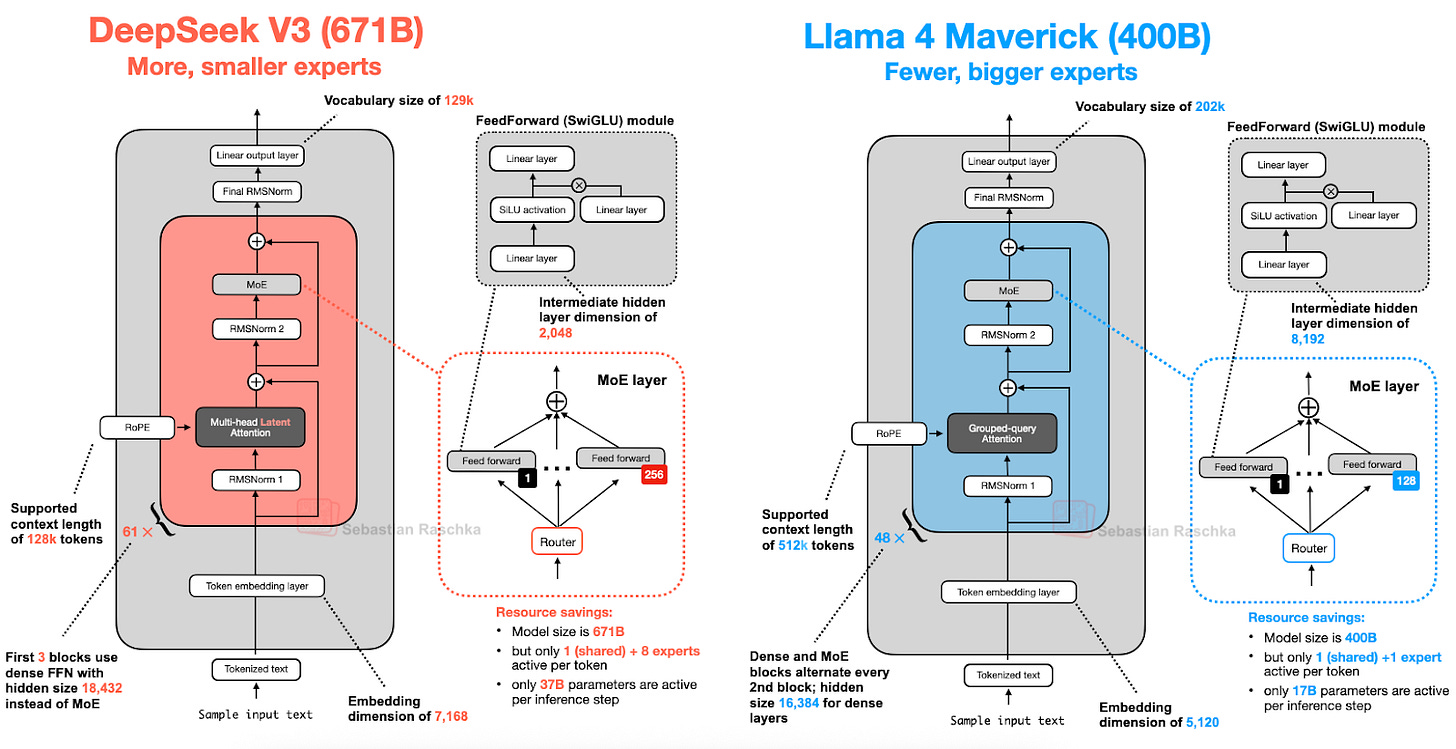
The differences are that Llama 4 uses GQA while DeepSeek-V3 uses MLA, and the number of experts and activation methods differ (DeepSeek-V3 activates 9, Llama 4 activates 2).
"In 2025, MoE has become the dominant architecture for large LLMs."
7. Qwen3: Flexible Architecture from Ultra-Small to Ultra-Large
Qwen3 is released in a wide range of sizes -- 0.6B to 32B (dense), 30B-A3B/235B-A22B (MoE) -- offering options from small models suitable for local execution/training to MoE models optimized for large-scale inference.

MoE models use only as many parameters as the number of active experts (e.g., 22B), pursuing both the learning capacity of large models and inference efficiency simultaneously.
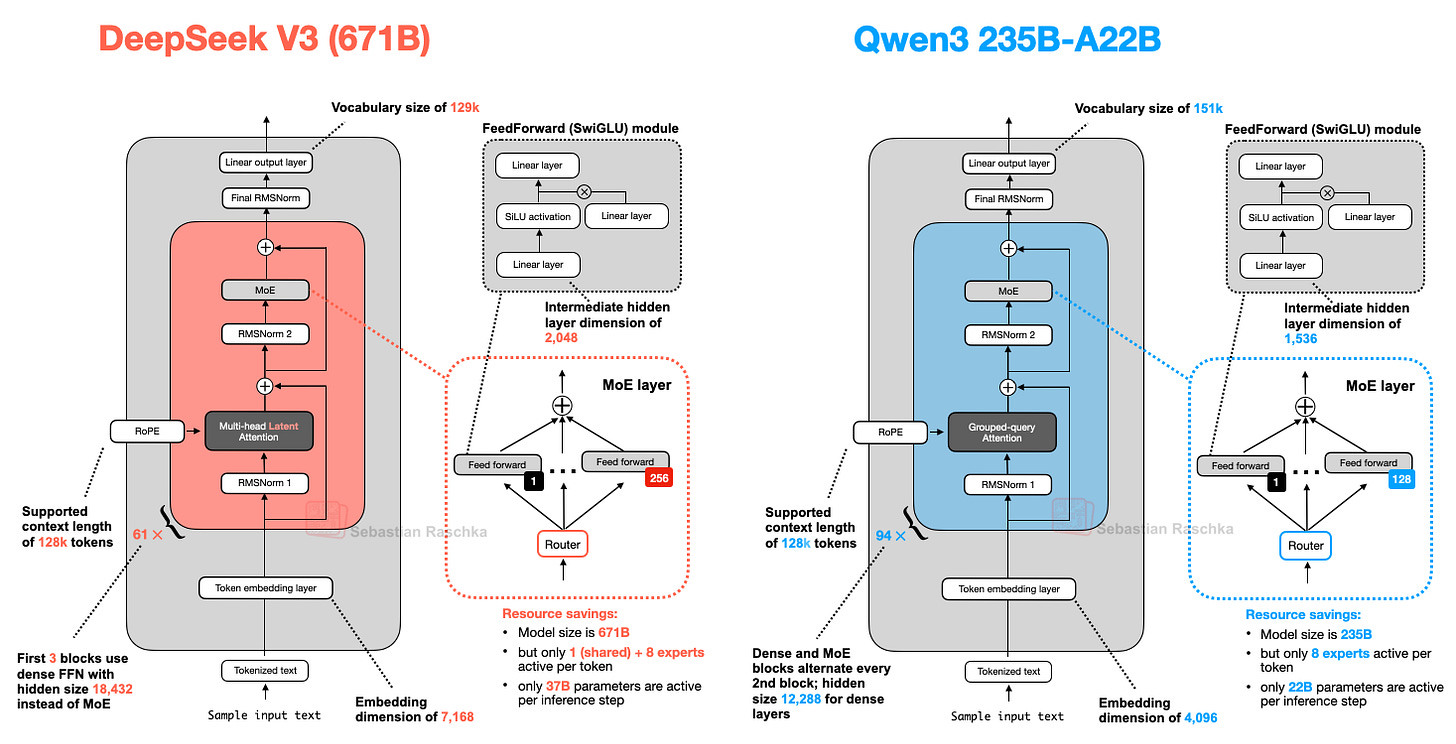
Interestingly, Qwen3 doesn't use shared experts. Developer Junyang Lin responded:
"At the time, shared experts didn't provide significant improvement, and we had concerns about inference optimization. Honestly, there's no clear answer."
8. SmolLM3: Eliminating Positional Embeddings with NoPE
SmolLM3 (3B) is a small model competing with Qwen3 1.7B/4B, Llama 3 3B, and Gemma 3 4B.

The most interesting aspect is NoPE (No Positional Embeddings) -- a structure that doesn't use positional embeddings at all.

Previously, positional embeddings (e.g., RoPE) were considered essential, but the NoPE paper showed that length generalization performance can actually be better without explicit position information.

9. Kimi 2: 1 Trillion Parameters, an Extended Version of DeepSeek-V3
Kimi 2 is an ultra-large open model with 1 trillion (1T) parameters, using the DeepSeek-V3 architecture as a base with more experts and fewer MLA heads.

It also applies the Muon optimizer to a large model for the first time, achieving very fast and stable training loss curve reduction.

In Closing
As of 2025, LLM architectures are maintaining the same fundamental skeleton while actively experimenting with diverse approaches for efficiency and performance. MLA, GQA, MoE, sliding window attention, NoPE, and normalization layer placement -- each model pursues memory efficiency, inference speed, training stability, and scalability in its own way.
"After all this time, LLM development is still fascinating. I look forward to seeing what innovations come next!"