The first half of AI development focused on creating new models and training methods, but we have now entered the second half, where evaluation and problem definition have become paramount. As RL (reinforcement learning) has generalized, AI can now tackle diverse tasks with a single recipe, and going forward, evaluation methods that enhance real-world utility and problem definitions grounded in reality will be the key drivers. The remaining challenge is finding the answer to: "What should we evaluate with AI, and how do we truly change the world?"
1. The First Half of AI: The Era Dominated by Models and Training Methods
From the late 20th century through the early 2020s, AI progress was driven primarily by the invention of new training methods and model architectures. Notable examples include DeepBlue defeating the chess champion, AlphaGo surpassing humans at Go, AI scoring higher than most people on the SAT and bar exams, and AI medalists in math and coding olympiads.
"We developed new training methods and models to solve benchmarks better and better--that was the first game."
Looking at citation counts, models and methodologies like Transformer, AlexNet, and GPT-3 received enormous attention, while the benchmarks that measured their performance (e.g., WMT'14, ImageNet) received comparatively little.
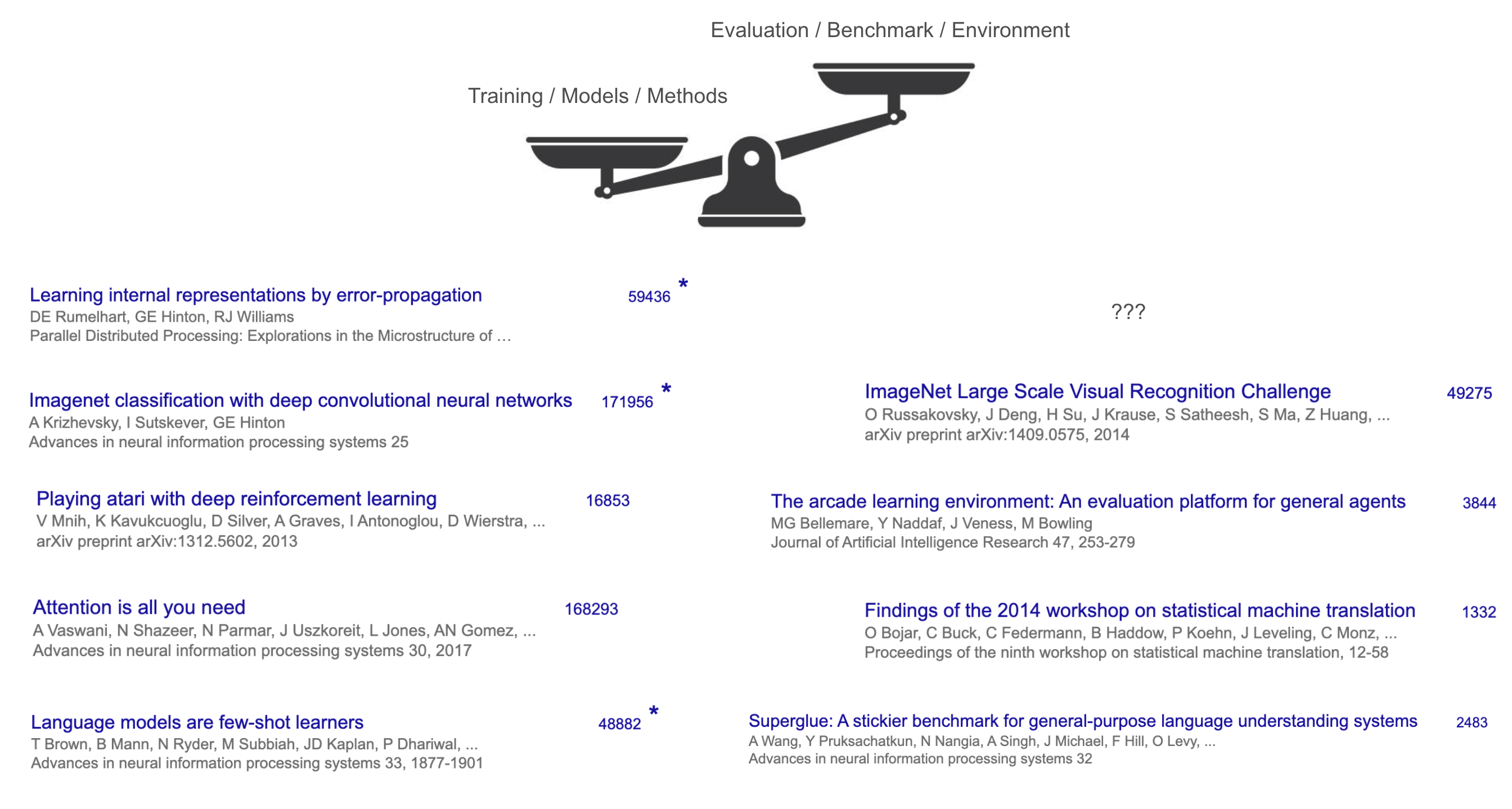
The reason is clear: only those who invented new models or training methods created breakthrough changes. Meanwhile, "deciding what AI should do" (i.e., setting benchmarks) was relatively less creative, largely limited to having AI do things humans were already good at (translation, image classification, etc.).
Therefore, the rules of the first half were simple:
- Present an innovative methodology that surpasses existing models.
- If that method raises benchmark scores, you win.
This approach produced breakthrough results across countless domains over a long period, driving AI forward.
2. Discovery of the Recipe: The True Turning Point of RL
In recent years, a crucial catalyst for change arrived. The essence of that change is as follows:
"In three words: RL finally works. More precisely, RL now generalizes."
That is, while RL (reinforcement learning) previously only produced good results in specific domains (e.g., Go, games), it has now been proven to work across nearly all complex tasks using the same principles.
Previously, software engineering, creative writing, IMO-level math problems, mouse and keyboard control, and long-form Q&A each required separate research. Now, a single "recipe" can handle most of them.
That recipe combines three key elements:
- Large-scale language pre-training
- Massive data and compute scale
- Reasoning and Acting

Traditional RL research almost always focused exclusively on "algorithms." But the importance of the environment and prior knowledge gradually became clear, and among these, language pre-training as "prior knowledge" proved decisive.
Past efforts like OpenAI's "gym," "Universe," and Dota2 agents made progress but could not extend to web browsing or computer use, and RL that succeeded in one domain did not transfer to others.
After GPT-2 and GPT-3, the critical piece finally emerged:
"The most important part of RL turned out to be not the RL algorithm or the environment, but the 'pre-training priors'"
Language pre-training was effective for chat but had limitations in computer use and gaming domains. The reason was that these domains were far from internet text distributions, and directly applying SFT/RL did not generalize well.
However, by adding "thinking"--that is, Reasoning--to the agent's action space, the language model's prior knowledge could generalize to new environments.

"Thinking, or reasoning, does not directly affect the world, but the space itself is infinite. We selectively leverage this space while demonstrating highly flexible reasoning capabilities."
Thus, the recipe of "language pre-training + reasoning = general-purpose reinforcement learning" became established, and the RL algorithm itself became a minor component.
3. The Beginning of AI's Second Half: The Shift to Evaluation and Problem Definition
With the emergence of this general-purpose recipe, the game of the first half has changed.
"The recipe no longer requires entirely new ideas; it has already been standardized and industrialized so that benchmark scores can be improved at scale."
Even if new benchmarks with slightly higher standards are introduced in the traditional way, the general-purpose recipe will quickly solve them.
Therefore, the real remaining problem has shifted to "how do we evaluate?"
"It is no longer about creating new, harder benchmarks, but about fundamentally questioning existing evaluation methods and creating new evaluation settings."
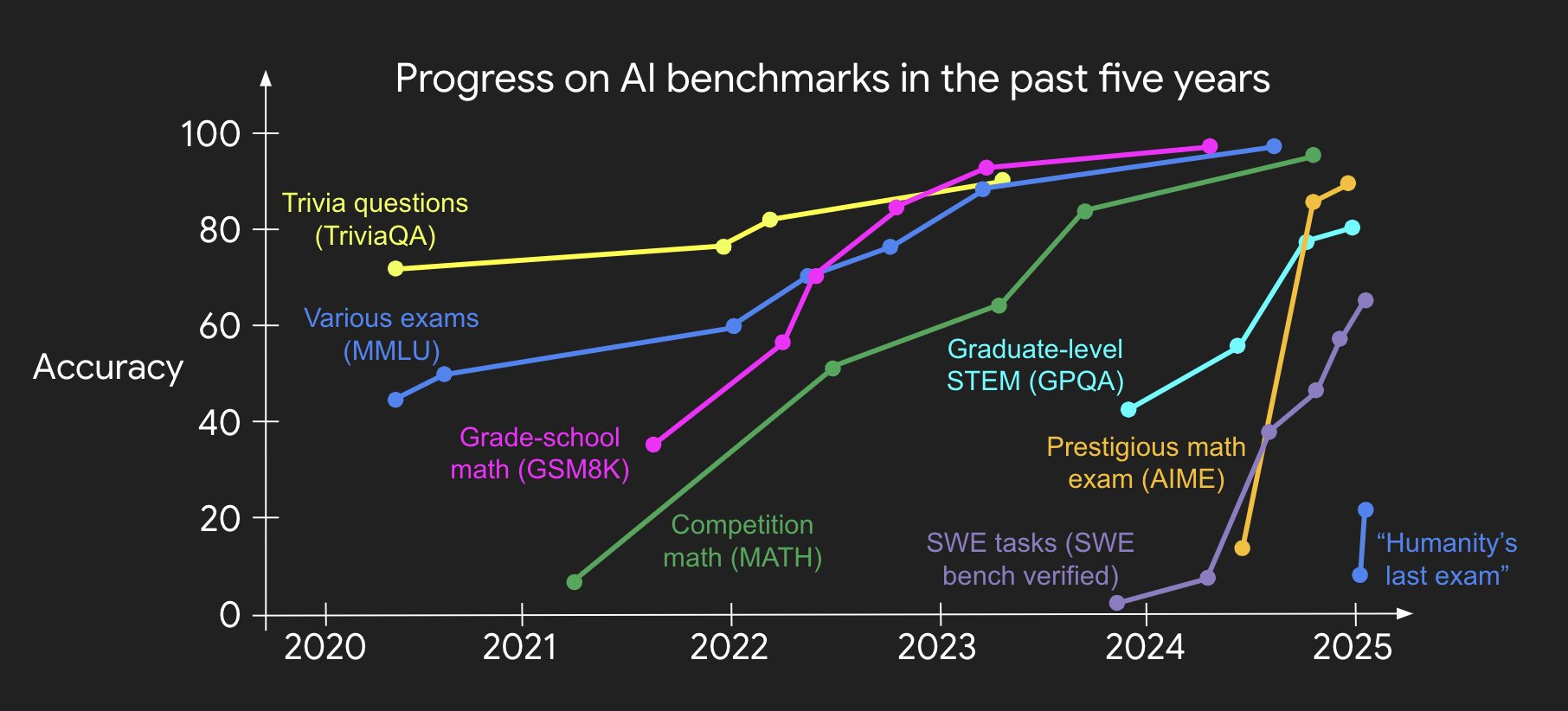
Major AI achievements (chess, Go, SAT, bar exam, IOI, IMO, etc.) have already been accomplished, yet the real world (economy, GDP, etc.) has not changed dramatically.
The author calls this phenomenon the "utility problem."
4. The Utility Problem and the Need for Evaluation Innovation
AI has won at various games and exams, but actual economic value (utility) has not changed dramatically.
"The root of the problem is that evaluation (setup) differs too much from reality."
Key differences and issues include:
1. Evaluation methods are too focused on full automation: Most tasks follow an "input -> AI executes autonomously -> answer/score" structure.
"In reality, agents need to interact with people. A customer service center cannot just send one long message and wait for a response--it requires multiple rounds of real-time conversation to be truly useful."
In response, benchmarks incorporating real human usage (e.g., Chatbot Arena, tau-bench) are emerging.

2. Evaluation relies solely on the i.i.d. (independent and identically distributed) assumption: For example, running 500 tasks independently and averaging their scores.
"In reality, experience from previous tasks helps with the next one. A Google engineer who keeps looking at the same repo solves problems faster over time, but AI never becomes familiar with the same environment."
Ultimately, AI needs "long-term memory" like humans, and new evaluation criteria to test this are needed.
Key conclusion: In the past, when intelligence was low, simply raising benchmark scores also increased practical utility. But now that the general-purpose recipe can win in any "existing evaluation framework," we have reached the point where evaluation and problem definition themselves must be changed to reflect real-world utility.
5. The Game of the Second Half: Practical Evaluation, Real-World Problem Definition, and True Change
The rules of AI's second half change as follows:
- Develop new evaluation methods/tasks that close the gap with real-world settings.
- Either solve them with the general-purpose recipe, or find the parts where the recipe falls short and devise genuinely new methods.
- Continue repeating this process.
This approach is difficult because it is new, but simultaneously exciting.
"The first half was about AI solving games and exam problems, but the second half is an arena for building practically useful products and, through that, building companies worth billions or trillions of dollars."
Without innovative evaluation methods, clinging to existing frameworks will yield only incremental progress--true game changers will be hard to come by. In other words, creating genuine practical value through new evaluation and problem definition--that is the play style of the second half.
"Welcome, winners of the new first half! The second game now begins."
Closing Thoughts
The direction of AI development has now reached a new turning point focused not on simple model competition, but on how much it contributes to real-world utility and solving real problems. The question is no longer "How far can AI go?" but rather "How do we evaluate AI, and what problems do we challenge it with?" This is precisely the starting point of the second half.