
Why This Article Was Written
There have been very few detailed posts about large-scale web crawling in recent years. The last useful reference was Michael Nielsen's 2012 post. Since then, much has changed: more CPU cores, SSDs becoming standard, explosive growth in network bandwidth, and diverse cloud instances. But the web itself has also become more dynamic and heavier.
The author set out to answer: "What's different now? Where have the bottlenecks shifted? Can I still build my own Google for $40,000 like a decade ago?" -- and conducted an experiment to build a web crawler and crawl 1 billion pages in just over 24 hours under similar constraints.
Problem Definition: Goals and Constraints
1. Crawl 1 Billion Pages in 24 Hours
- Preliminary experiments suggested one billion pages in a day was feasible.
- Actual average uptime per machine was 25.5 hours (including restarts).
2. A Budget of a Few Hundred Dollars
- Nielsen's crawl cost roughly $580.
- The author completed the crawl in 25.5 hours for $462.
- Multiple smaller and larger-scale experiments were also conducted.
3. HTML Only
- No JavaScript execution. Using the "old-school" method of collecting links from
<a>tags. - Part of the curiosity was: "Can you still crawl much of the web this way?"
4. Politeness
- Respect robots.txt, include contact info in the user agent, exclude domains on request, crawl only the top 1 million domains, and maintain at least 70-second intervals between requests to the same domain.
"I felt it was essential to be polite and not cause harm to site operators."
5. Fault Tolerance
- The system needed to be able to stop and resume mid-crawl.
- Not perfectly fault-tolerant, but some data loss was acceptable.
System Design: How It Was Built
Overall Architecture
Unlike typical crawler designs (which separate parsing, fetching, storage, and state management across different machines), the system used a self-contained architecture where each node handles everything. Each node is responsible for a shard of the total domain space, with the following setup:
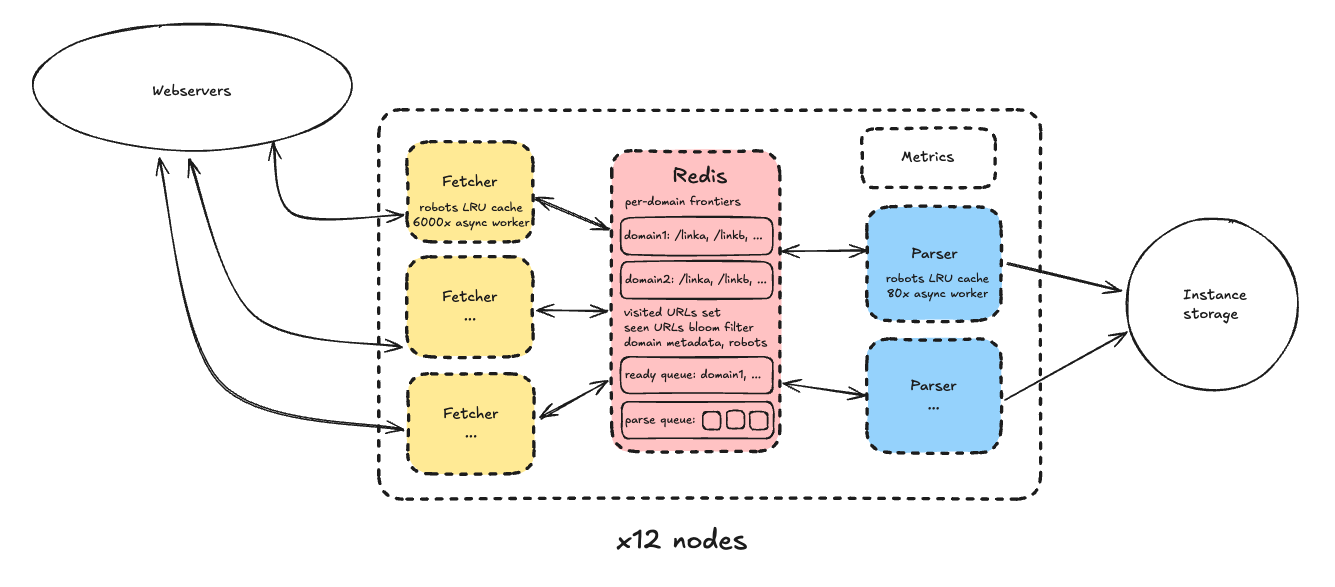
Node Components
- Redis instance: Manages crawl state
- Per-domain frontier (URL queue)
- Domain queue (sorted by next-crawlable time)
- Visited URLs, metadata, and storage paths
- Bloom filter: Fast check for already-added URLs (speed over perfection, minor false positives accepted)
- Domain metadata (robots.txt, exclusion status, etc.)
- Parse queue
- Fetcher process pool
- Pulls the next domain/URL from Redis, crawls it, and pushes results to the parse queue
- Each process uses asyncio to handle thousands of concurrent tasks (6,000-7,000)
- LRU cache minimizes Redis load
- Parser process pool
- 80 async workers for HTML parsing, link extraction, and storage
- Parsing is CPU-intensive, so fewer workers than fetchers
- Other
- Storage uses instance storage (S3 excluded due to cost)
- Pages truncated at 250KB for the experiment
- The first fetcher acts as leader, recording metrics to Prometheus
Final Cluster Specs
- 12 nodes
- Each node:
i7i.4xlarge(16 vCPU, 128GB RAM, 10Gbps network, 3,750GB storage) - Each node: 1 Redis + 9 Fetchers + 6 Parsers
"Domain seed lists were sharded by node, so each node crawled its own region of the internet."
Why Only 12 Nodes?
- Sharding too thinly causes hot-shard problems on popular domains
- Redis performance degrades around 120 ops/sec, capping out at 15 processes
Alternative Design Experiments
- SQLite, PostgreSQL: Too slow for frontier queries
- Single-node vertical scaling: Tried multiple "pods" on an
i7i.48xlarge, but performance didn't meet expectations, so the approach shifted to horizontal scaling (multiple nodes)
Lessons Learned: Real Bottlenecks and Surprising Changes
1. Parsing Was the Biggest Bottleneck!
Initially, parsing was so slow that one fetcher needed two parsers. CPUs are better than in 2012, so why? Profiling revealed: average web page size grew from 51KB in 2012 to 138-242KB in 2025.
"I never expected parsing to be such a major bottleneck."
Solutions
- Switched from lxml to selectolax (a modern C++-based HTML5 parser, up to 30x faster)
- Truncated pages at 250KB (above average, so most pages are stored intact)
With these changes, one parser could process 160 pages per second, and the final setup of 9 fetchers + 6 parsers achieved approximately 950 pages per second!
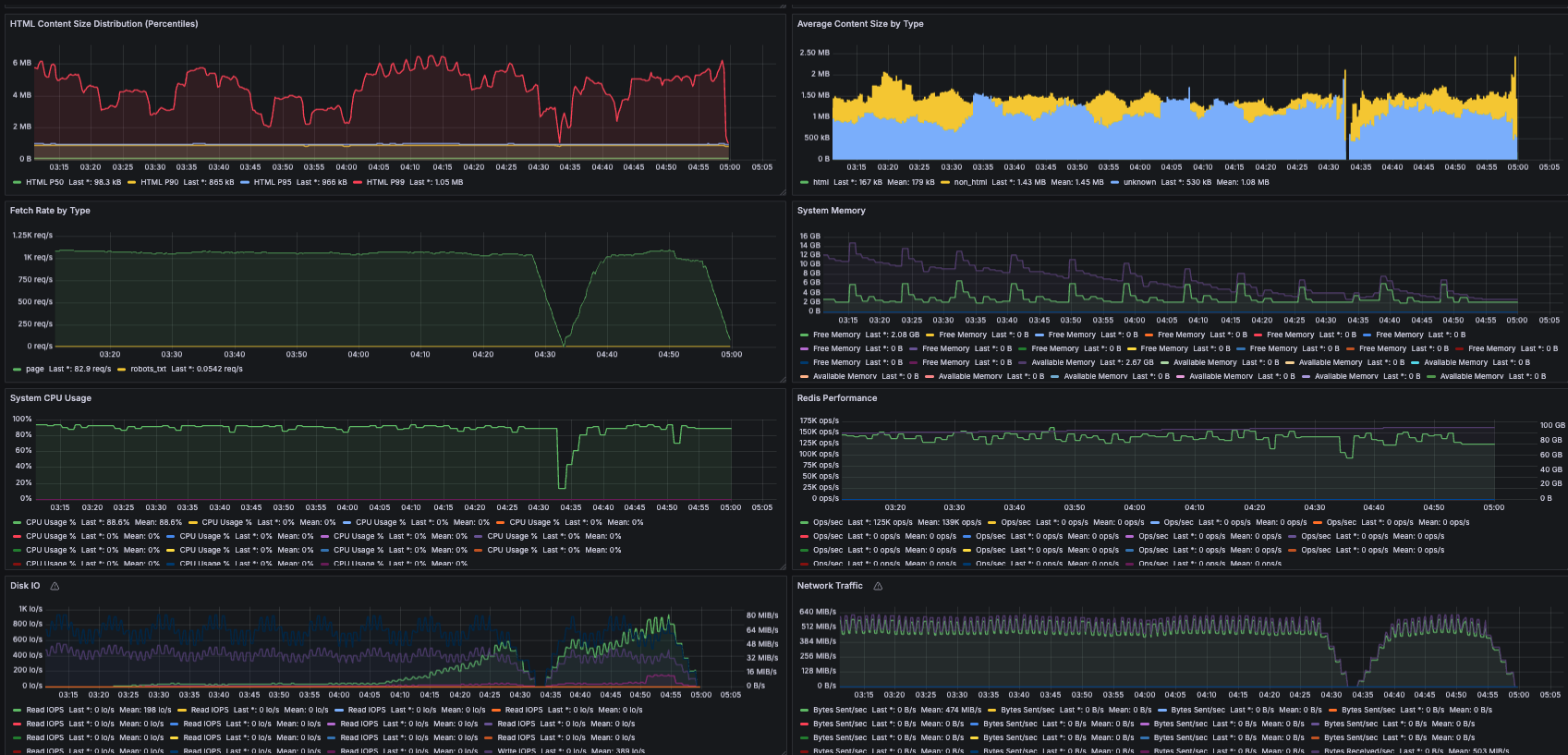
2. Fetching: What Got Easier and What Got Harder
In the past, network bandwidth and DNS were the bottlenecks. In this experiment, CPU was the bottleneck.
- DNS: No bottleneck since only the top 1 million domains were crawled
- Network: Only 8Gbps of 25Gbps per node used (32% utilization)
- SSL: SSL adoption surged from 30% in 2014 to over 80% in 2025. SSL handshakes consumed 25% of total CPU -- CPU saturated before network
"The SSL handshake was the most expensive function, consuming 25% of total CPU."
3. Large-Scale Crawl in Practice
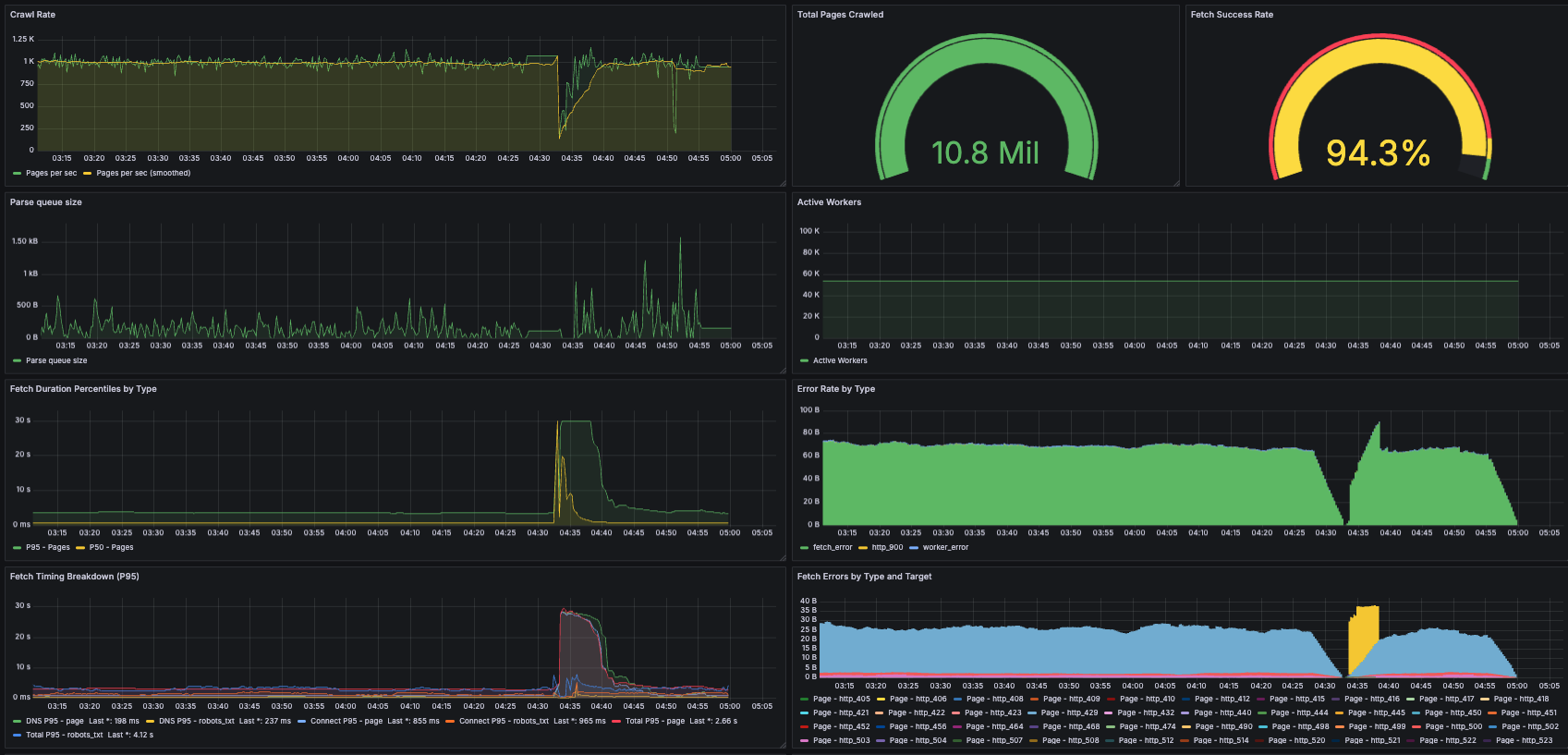
- Several issues arose during the 12-node large-scale experiment:
- No log rotation configured -- root volume filled up
- Frontier memory explosion: Popular domains (Yahoo, Wikipedia, etc.) accumulated hundreds of millions to billions of URLs, crashing nodes
- Recovery involved manually restarting nodes and trimming frontiers
"Nodes started dropping like flies. Fortunately, the fault-tolerant design made it easy to resume."
Discussion: Theory vs. Practice, and the Road Ahead
1. Theory vs. Reality
- Theoretical analysis (e.g., 10 billion pages in 5 days with 5 machines) compared to actual performance
- In practice, accounting for network utilization and core allocation, comparable efficiency is achievable
2. Future Challenges
- Much of the web is still accessible without JavaScript execution. However, sites like GitHub render actual content via JS, so large-scale crawling with dynamic rendering would be much more expensive.
"It was surprising how much of the web is still accessible without JS."
-
Distribution and characteristics of the 1 billion crawled pages: Live URL ratios, HTML vs. multimedia ratios, etc. -- still unanalyzed
-
The web's evolution and the future of crawling: Large-scale crawling in the AI era, Cloudflare's pay-per-crawl model -- a new balance between site operators and crawlers is needed
Conclusion: How Web Crawling Has Changed in a Decade
- Due to growing page sizes, universal SSL, and advancing network infrastructure, the bottleneck has shifted from IO to CPU (parsing and SSL)
- A modest budget and 12 servers can still crawl 1 billion pages in 24 hours
- The importance of polite and responsible crawling is emphasized
"I took politeness very seriously. I respected robots.txt, left contact information, and excluded domains on request."
Key Concepts Summary
- 24 hours, 1 billion pages, low budget
- Parsing bottleneck, SSL CPU overhead
- Horizontal scaling, Redis, async processing
- Politeness, fault tolerance
- Web evolution, dynamic rendering, the future of crawling
This article vividly illustrates the present and future of web crawling, and the real-world problems and solutions encountered along the way. It offers valuable insights for anyone building web crawlers or interested in large-scale data collection.