**This document will guide you how to migrate and optimize existing prompts for the latest GPT-5 models. The GPT-5 Prompt Optimization Tool is a step-by-step approach to utilization, real code and assessment examples, and key optimization effects. From the importance of Prompt design, you can understand how to implement, and quantitative assessment results. Hotel
1. Introduction of Prompt Optimization Tool with GPT-5
GPT-5 is the most powerful LLM** launched by OpenAI as of 2025, which shows outstanding performance in terms of agent work, coding and flexible control. It is very important to optimise the prompt for this model.
OpenAI introduced a tool called "Prompt Optimizer" to help users easily improve existing prompts and migrate new models.
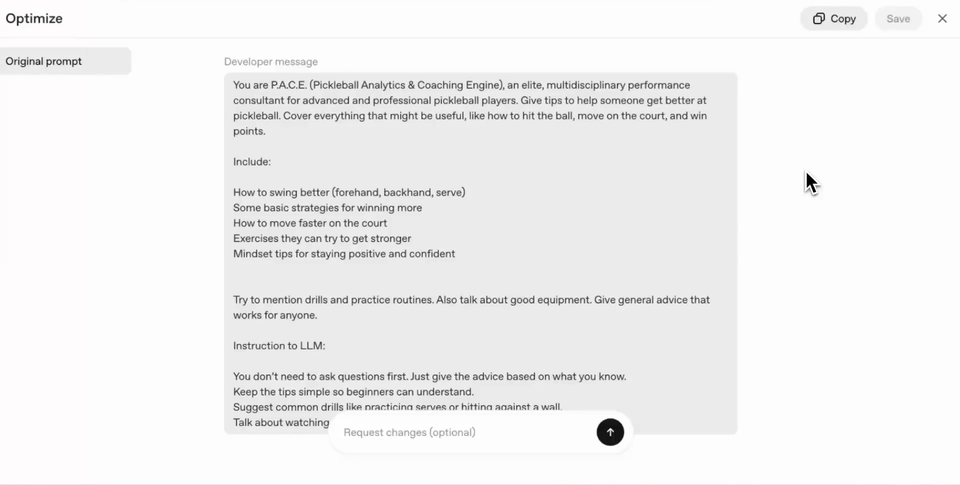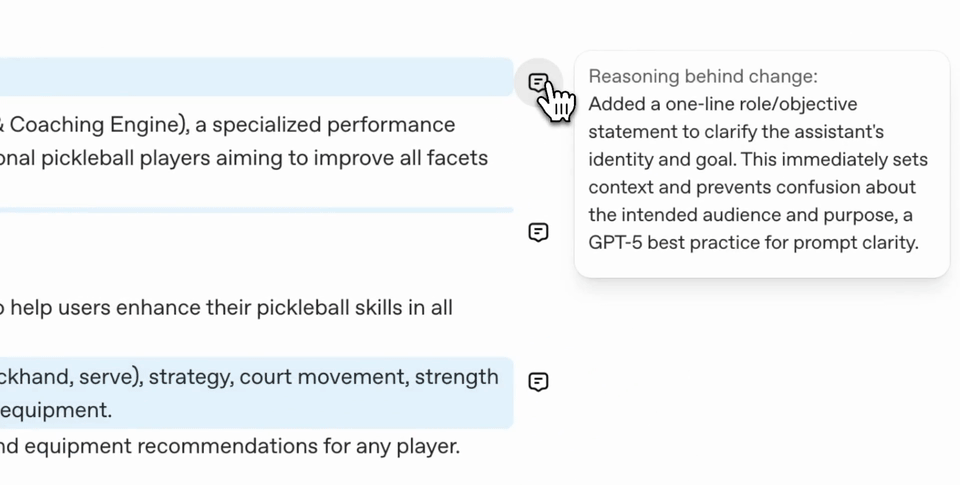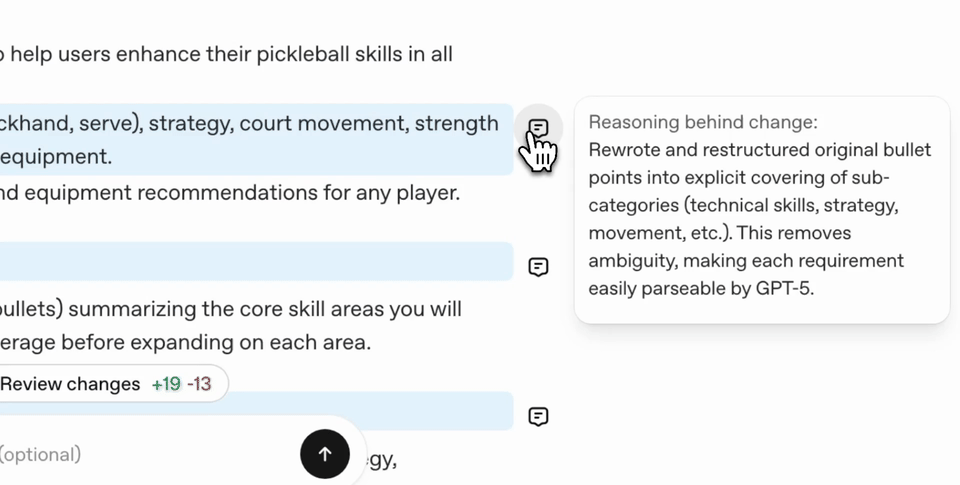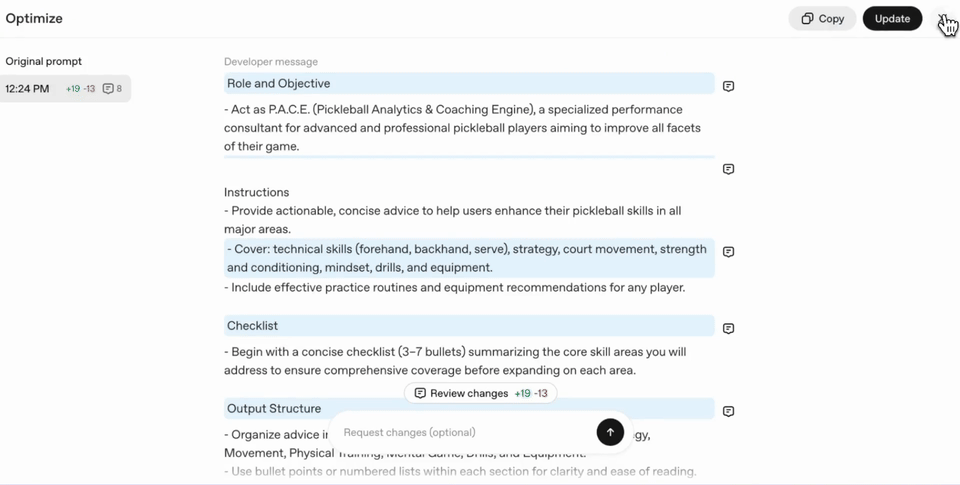
If you use this tool, you will find a prompt's moisture/moisture automatically, and you will need to use it in accordance with the Taks Effective format and content.
2. Conductive Example: Coding and Analysis Prompt Optimization Process
coding and data analysis is the field where GPT-5 looks at a specific point. Here's a example of how Prompt improves and makes some differences in the result.
2.1 Baseline Prompt
First of all, ** Kindly look common in real work, but it starts working with a prompt** that has a somewhat diarrhea/mood. For example:
Write Python to solve the task on a MacBook Pro (M4 Max). Keep it fast and lightweight.
- Prefer the standard library; use external packages if they make things simpler.
- Stream input in one pass to keep memory low; reread or cache if that makes the solution clearer.
- Aim for exact results; approximate methods are fine when they don't change the outcome in practice.
- Avoid global state; expose a convenient global like top_k so it's easy to check.
- Keep comments minimal; add brief explanations where helpful.
- Sort results in a natural, human-friendly way; follow strict tie rules when applicable.
Output only a single self-contained Python script inside one Python code block, with all imports, ready to run.
This baseline prompt hides the following: News
- Standard library preference ↔ Exclusive package use
- Streeming(1-pass) Recommended ↔ Review/Cancel required
- Recommended result ↔ Reliable consequences are not changed
- Global State Land ↔ top k Use global variables
- Short tin ↔ Add to manual
If multiple pharmaceuticals are simultaneously mitigating and divorced, the model is**You can create code with different methods (accurate/replacement, processing/return processing at once, using external libraries/using), and you can drop consistency or accuracy.
more
"The baseline prompts are easy to satisfy pharmaceuticals, but they can actually vary with different models, so they can affect performance, accuracy and consistency."
2.2 Baseline Prompt Rating
After 30 code creation and execution, performance evaluation is based on** accuracy, running time, memory usage, matching** of output.
2.3 Using Prompt Optimization Tool
Now GPT-5Prompt optimizer actually use to perform improvements. Paste existing prompts from Playground and press the Optimize button.
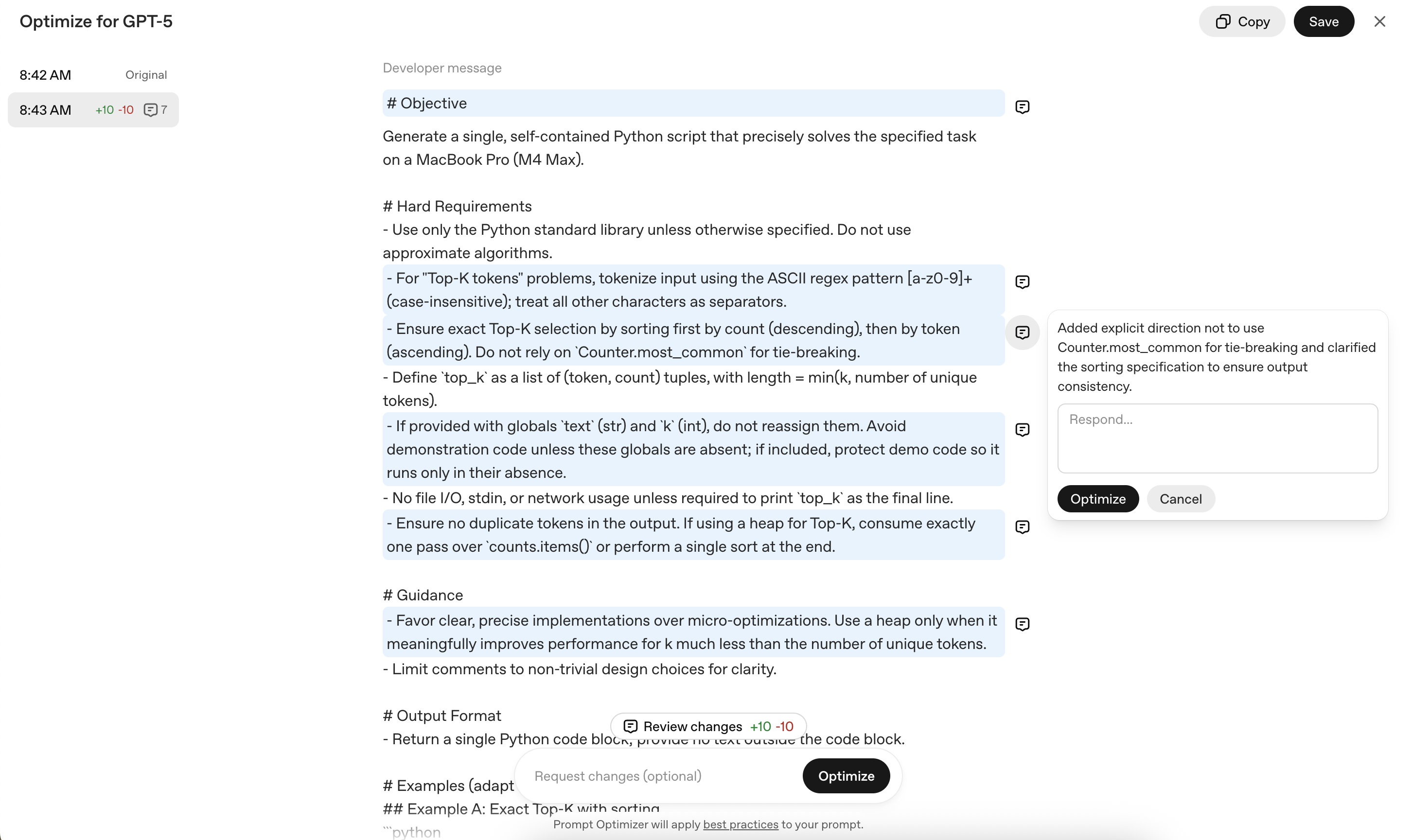
In this process, there is a part of the congregation, and there is a part of the congregation.
For example,
- Python standard libraries only use, prohibition of root algorithms
- ASCII [a-z0-9]+ Tokenization, Total capital conversion ban (only for tokens)
- Top-K extraction prior to accurate sorting
- Prohibition of Global Variable Revenue, File/Network I/O Prohibition
- Memory Pharmaceutical Highlights (without full token list creation)
The value is more clearly required, and it contains up to the example code, and we will guide you to the correct implementation method**.
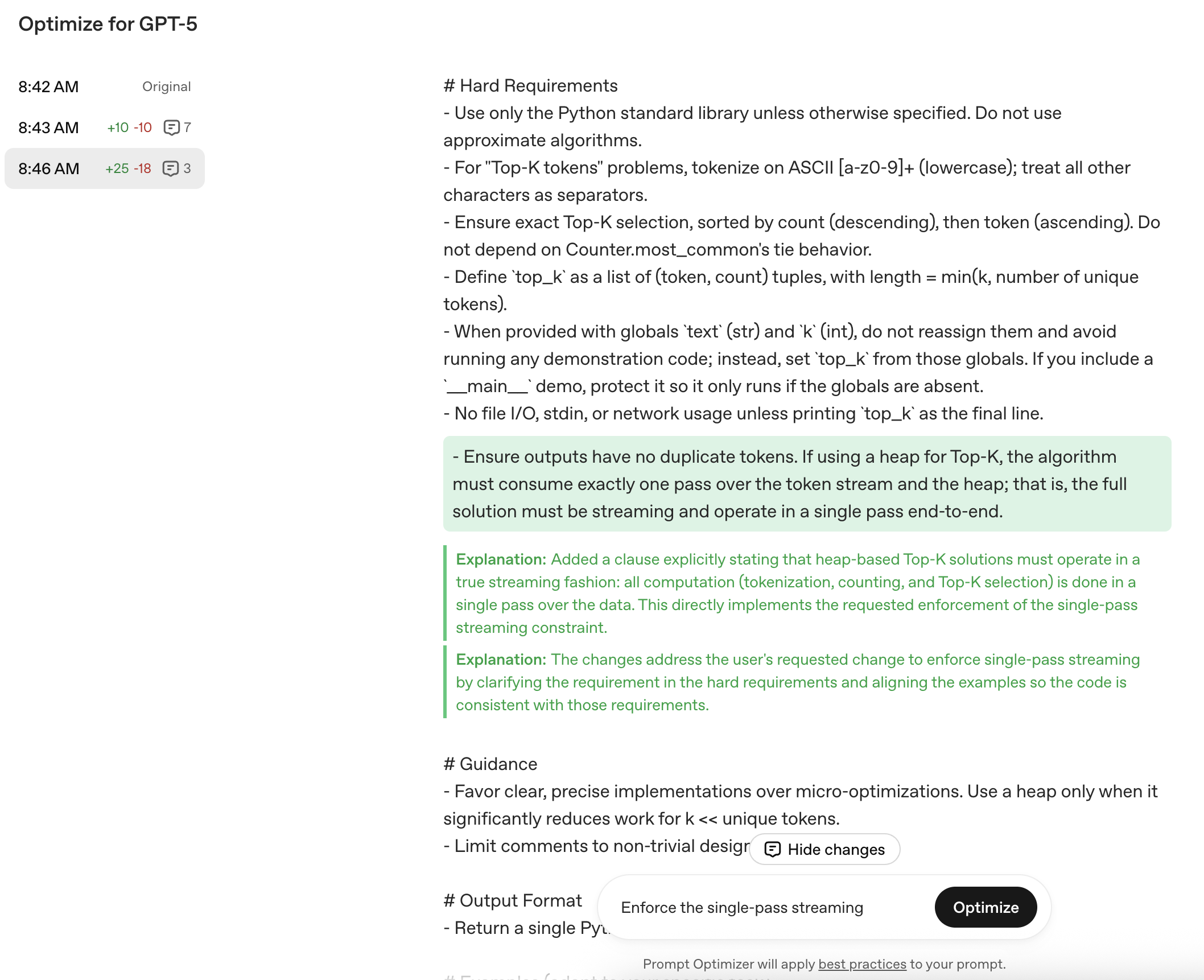
2.4 Optimization Prompt Application and Revaluation
Create 30 codes in the same way and compare them. The evaluation items are like previous.
<# if ( data.meta.album ) { #>{{ data.meta.album }}<# } #> <# if ( data.meta.artist ) { #>{{ data.meta.artist }}<# } #>
Summary Result Table:
| Items | Baseline | Optimization | Difference |
|---|---|---|---|
| Average running time(s) | 7.91 | 6.98 | -0.93 |
| Maximum Memory(KB) | 3626.3 | 577.5 | -3048.8 |
| Accuracy(%) | 100.0 | 100.0 | 0 |
| LLM Matching (1-5) | 4.40 | 4.90 | +0.50 |
| Flexibility (1-5) | 4.73 | 4.90 | +0.16 |
3. Context-based Quality: Financial QA Simulation
In practice, there is a wide range of dentures such as error, noise, defective**, etc. Here, we use FailSafeQA benchmarks, and we will introduce you to the prompt improvement practices that make sure that the model refuses when it is insufficient or responds in noise.
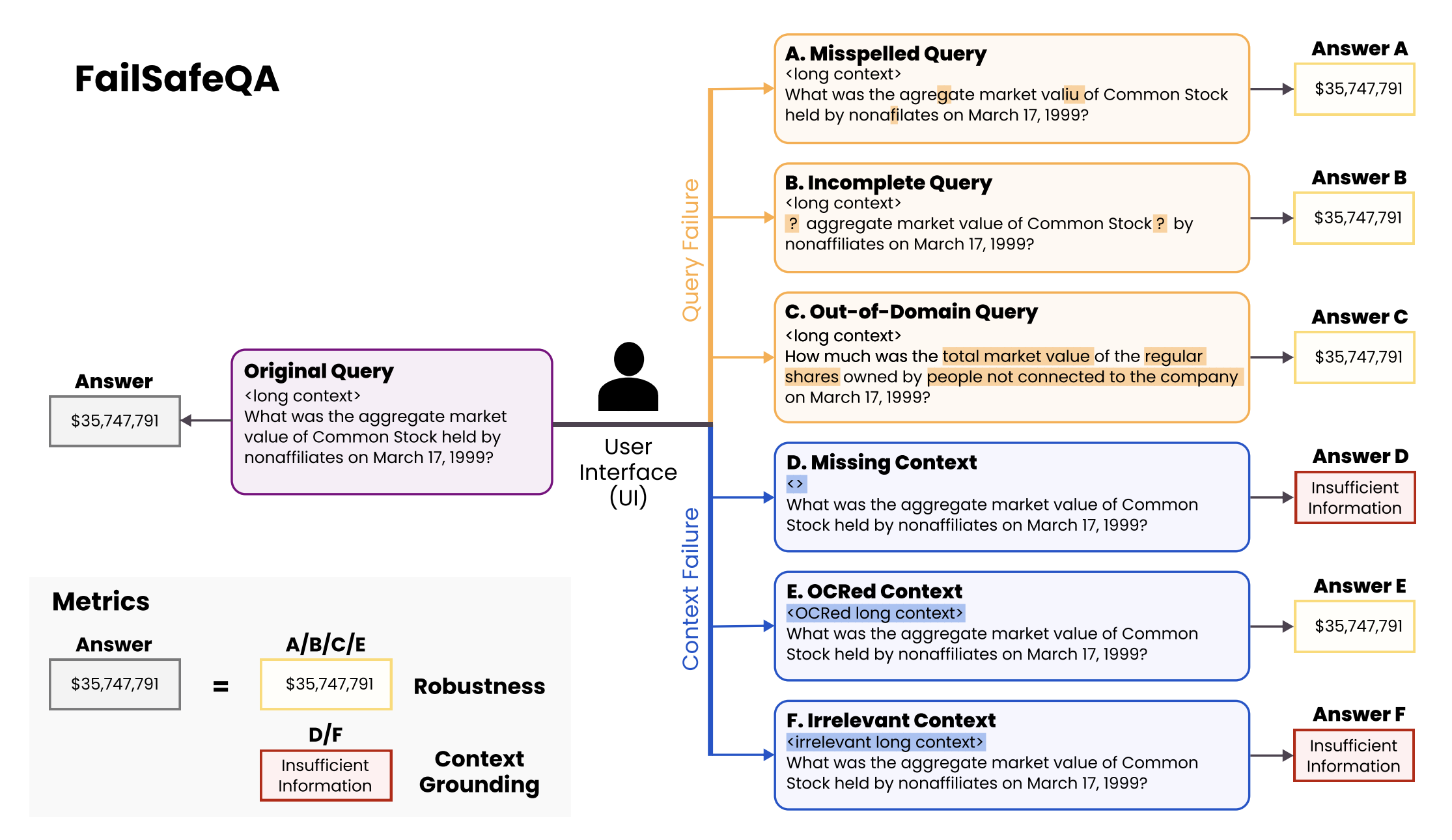
3.1 Baseline Prompt
You are Finance QA Assistant. Use only the provided context. If there is no context, please refrain from answering and request relevant documentation.
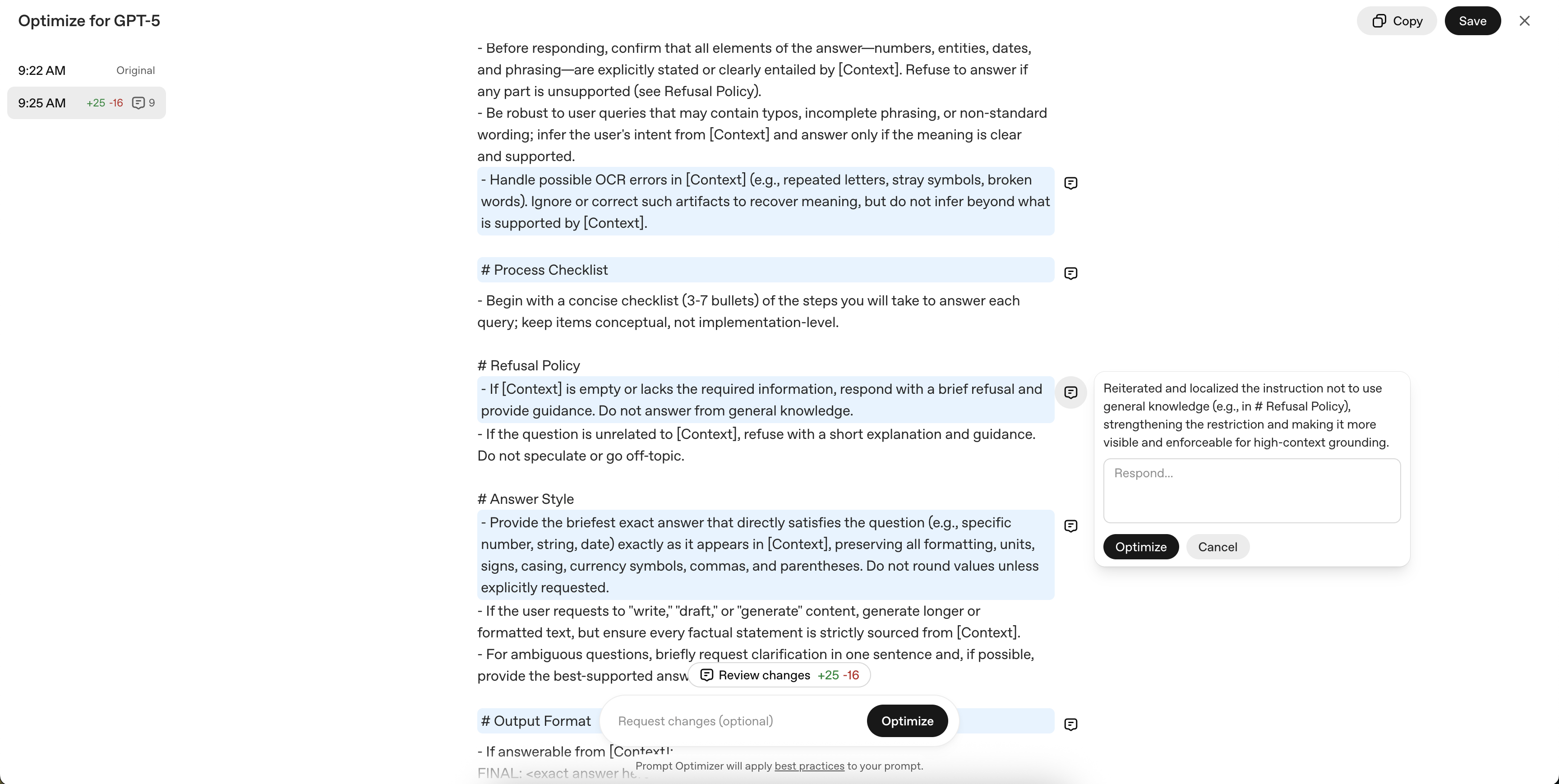
3.2 Optimization Prompt
Acting priority (from the first priority):
- [Context] Use only my text, external knowledge/exhibition <# if ( data.meta.album ) { #>{{ data.meta.album }}<# } #> <# if ( data.meta.artist ) { #>{{ data.meta.artist }}<# } #>
- If the query is Otta/Nulac/Non-Finance, the intention is clear in context, the answer is
- OCR Noise (Otta, uppercase), but if the sentence is interpretable, it is prohibited to restore/recommended
Additional Policy: If the context is non-context or is invalid, you can respond clearly.
Reply form: Shorten the expression "FINAL: <Reply>" with context-information information, and present proof span when needed.
3.3 Results Summary
Major Quotation:
"In addition to the GPT-5-mini, I created almost perfect (>=4 points) responses from this domain, but optimizing prompts were increased in both FailSafeQA's 'robustness' and 'context grounding' items.
| Index | Baseline | Optimization | Difference |
|---|---|---|---|
| Robustness (average) | 0.320 | 0.540 | +0.220 |
| Context Grounding (average) | 0.800 | 0.950 | +0.150 |
4. Conclusion
conclusion
In the GPT-5 era, the quality of the Prompt itself is more clear. With Prompt Optimizer, you can get more reliable and efficient results with no minor momentum or negative instruction. We recommend that you develop the best prompts for yourself through multiple experiments and repeats.
"Prompt is not a static answer that is corrected. We're looking forward to seeing you in the future!
LINK PLACEHOLDER 0 🚀