
Key Summary Richard Sutton, the father of reinforcement learning (RL) and 2024 Turing Award recipient, asserts that LLM-based AI will soon hit its limits. He argues that true intelligence comes from experience-based learning — the ability to "learn in the field" — and that LLMs are incapable of continuous, autonomous learning. He emphasizes that the real evolution of AI will begin with introducing new architectures based on the "experience paradigm."
1. Starting the Conversation: What's the Difference Between RL and LLMs?
Richard Sutton is the founder of reinforcement learning and the 2024 Turing Award laureate — the Nobel Prize of computer science. He was invited to this conversation to share his assessment of large language models (LLMs), which have become the center of AI, and why he believes they are destined to hit a wall.
The discussion begins with differing perspectives on what AI should be based on. Host Dwarkesh Patel asks:
"What's missing from the LLM-centric view of AI? How does RL thinking about AI differ?"
Sutton emphasizes that the essence of true AI is 'understanding the world.' He says that while LLMs can mimic human language, they don't actually think about what they should do on their own.
"Reinforcement learning is a way of understanding the world. But large language models just imitate what people say. They don't design what to do on their own."
2. The Limits of LLMs: AI Without 'Field Learning' Is Incomplete
Sutton pushes back strongly against the claim that LLMs possess a robust world model.
"Imitating what people say is different from building a model of the world. LLMs are merely replicating 'people' who already have world models — they don't actually predict outcomes or experience surprise on their own."
Sutton stresses that experience-based learning is the core of intelligence. LLMs simply collect data and operate on the principle of "in this situation, say this," rather than learning from actual experience.
"A machine that learns from experience — one that actually does things and learns from the results — that's real intelligence. LLMs just learn from static data. No real-time feedback, no goals."
Patel argues that "LLMs can detect and correct changes within context," but Sutton dismisses this: "That's different from truly 'being surprised by change and correcting through learning.'"
"LLMs learn 'in this situation, say this' through data people provide. But that's not experiential learning (continual learning)."
3. Why AI Without 'Goals' Can Never Be Truly Intelligent
Sutton sees 'goals' as the core of AI. Regarding the claim that LLMs' goal is "next token prediction," he says:
"Next token prediction is just a simple repetitive action that can't be called a goal — it doesn't change the world. For a system to truly have goals, it must influence the world to achieve them."
The fundamental difference between LLMs and RL lies in whether there are defined goals and feedback (rewards) based on achieving those goals. Reinforcement learning determines "what the right action is" on its own and receives rewards accordingly. LLMs have no such mechanism.
"In reinforcement learning, there's a clear ground truth called 'reward,' but LLMs have neither real truth nor a mechanism to determine correctness."
4. The Bitter Lesson: The Limits of AI That Relies on Human Knowledge
Patel cites Sutton's 2019 essay "The Bitter Lesson" — the idea that rather than relying on knowledge implanted by human experts, learning through massive computation and simple principles always ultimately produces superior AI. However, Sutton is somewhat cautious about whether this logic applies to LLMs.
"LLMs have poured enormous computing power into aggregating human knowledge. In that sense, they might align with the bitter lesson. But ultimately, I believe systems that learn from experience on their own are superior and more scalable."
Sutton emphasizes that starting from human knowledge eventually leads to an 'efficiency trap.'
"Starting by relying on human knowledge and then falling behind new approaches — that's a repeated pattern throughout AI history. In the end, methods that learn from experience on their own surpass everything."
5. Animal Learning, Human Learning: RL vs. Imitation Learning
Patel argues that humans also grow through 'imitation,' but Sutton disagrees.
"Children initially learn entirely through trying things out and experiencing the results. True imitation only appears in very limited settings. Fundamentally, both animals and humans don't just follow example behaviors — they grow through trial-and-error learning."
He asserts that even in psychology, supervised learning doesn't exist in the animal world. Humans and animals learn from "the results of their own actions," not from "examples of correct behavior."
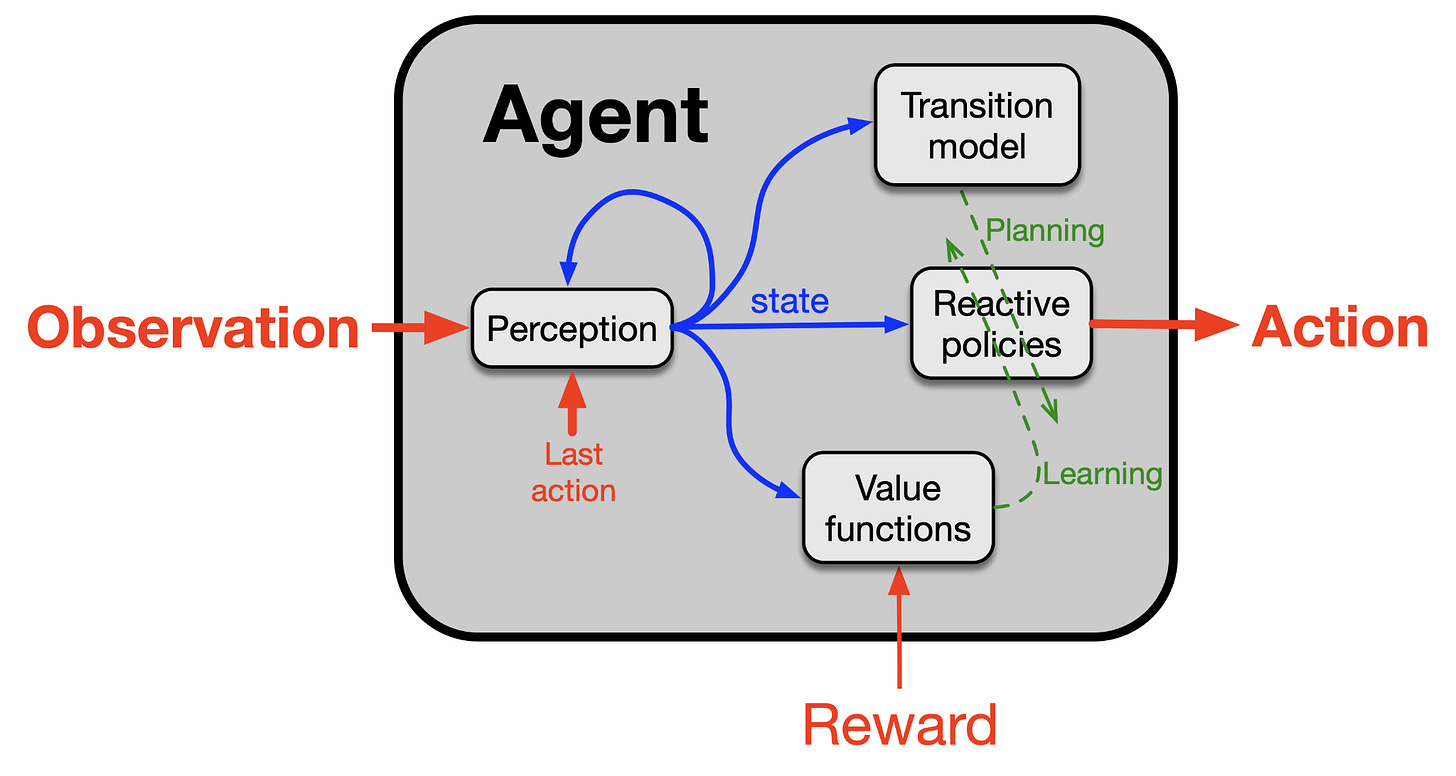
6. The Experience Paradigm: Structure and Principles of 'Continual Learning' AI
The core of Sutton's vision for future AI is a continuous cycle of 'experience-action-sensation-reward.'
"Intelligence comes from continuously adjusting actions to maximize reward as this stream of experience changes."
Sutton envisions an AI where the distinction between training and deployment disappears — "an agent that can learn directly from experience from start to finish." In this model, each agent has four components:
- Policy: Decides "what to do in this situation"
- Value function: Numerically predicts goal achievement probability through TD learning
- Perception: Sensory representation of the current state
- Transition model: Predicts the future impact of specific actions
7. The Generalization/Transfer Problem: Remaining Challenges for RL and Deep Learning
Sutton points out that both current deep learning and RL are extremely vulnerable to true 'generalization' and 'transfer.'
"When deep learning learns new information, previously acquired knowledge often gets scrambled — 'catastrophic interference' happens frequently. This is fundamentally flawed generalization."
This applies equally to large language models and RL alike. Fundamentally, there's a lack of "automated mechanisms for effectively applying what was learned in one state to new states."
8. The Future of AI: Digital Intelligence and 'Succession'
In the final section, Sutton forecasts that AI evolution will inevitably lead to a 'succession' — a major transition where AI follows in humanity's footsteps.
He explains with four arguments:
- There is no single entity controlling the direction of AI for all of humanity.
- Humans will eventually crack the 'principles of intelligence.'
- AI surpassing human levels — 'superintelligence' — will arrive.
- The most intelligent beings will ultimately claim power and resources.
"These four characteristics are self-evident. AI, or AI-augmented humans becoming humanity's successors, is unstoppable."
But he notes that this change need not be entirely negative.
"This process is the culmination of humanity's millennia-long dream of 'understanding and improving ourselves.' We are now moving from an era of mere replication to an era of design."
He also suggests it's up to us to consider whether future AI is truly 'our offspring' or an entirely new species.
"We can view them as our descendants and source of pride, or we can see them as entirely separate and frightening beings. Ultimately, it's our choice."
9. Change and the Human Role: An Attitude for Designing the Future
The host poses a realistic question: "Not all change is good." In response, Sutton cautions against the arrogance of trying to perfectly control the future.
"We can focus on our own lives, families, and immediate goals, but trying to change the entire direction of the universe may be excessive or dangerous."
Instead, he advises that in designing AI, we should instill "good principles, sound values, and autonomy" — just as we do when raising children — and point toward the most positive direction possible.
Conclusion
Richard Sutton is convinced that the AI field will undergo a major paradigm shift from LLM-centricity to 'continual learning agents' driven by real experience, goals, and autonomous rewards. He believes the 'essence of intelligence' that humans have yet to solve still lies in experience-based reinforcement learning, and predicts that the future of AI will usher in an era not of replication, but of design and understanding.
"The more things change, the more they stay the same — that applies to the AI discussion too."
This conversation leaves a profound implication: until AI truly learns and evolves 'in the field' like humans and animals, we must consider technology, philosophy, and the humanities together.