Building a Smarter News Service
How I Consume Korean News in the US
It has been two years since I moved to the United States. As I consumed more English content, I realized firsthand how limited the information and content I had been exposed to in Korea really were. There are 183 times more English-language web pages than Korean-language pages, and I also came to see that insisting on Korean-only content is like insisting on living in a well.
When it comes to news, Korea tends to publish similar articles across all outlets, while in the US many media organizations present different perspectives and angles. There is also far more news overall, so it becomes important to carefully filter the content that is actually useful to you, and services that help with that are popular.
For example, Summly, which condensed news articles to around 200 characters, was acquired by Yahoo!. There are also personalized news services like Pulse, which LinkedIn acquired. The circa app, which tries to show multiple voices on a single topic at a glance, has been doing well, and Prismatic, which analyzes posts on Facebook and Twitter to surface related news, raised $15M in Series A funding.
So what about Korean news? As a founder and developer, I am always interested in technology trends and market conditions, so I am sensitive to news about those topics. I want to consume news intelligently, but the situation in Korea is far from that. The number of articles produced by local media outlets is small, and even those articles are often very similar from one outlet to another. When Naver News changed its content providers from Yonhap and others during its battle with major media companies, there were almost no users complaining that the quality of articles had dropped.
Now many people are used to consuming whatever appears on portals without thinking. The fact that entertainment and sports page views far exceed those of politics, current affairs, society, international news, technology, and every other section shows that we are no longer reading news to think; we are mostly just chewing on gossip.
So I started by observing how I personally consume Korean news in order to figure out how to do it better.
- Browsing portal news pages
- Reading news that appears on Facebook or Twitter
- RSS feeds
First, I scan the standard portal news pages once a day. That is the most common pattern, like older relatives who turn on the 9 p.m. network news every evening and consume it one-way. Second, I read news that comes through social networks like Facebook and Twitter. I have a lot of friends my age and in my industry on Facebook, and many people with the same interests on Twitter, so the news they share feels personalized and more satisfying. Third, I go directly to sites that produce content useful to me. For startups, for example, I visit beSUCESS, and for technology I go to ZDNet. RSS helps reduce the effort.
Looking at all this, I realized I was putting in a lot of effort just to meet good news and good content. But I also realized that it still falls far short of the efficiency I get when I consume English news through the various US services mentioned above. I tried services like Genie News and NewsSummer, but they were not good enough in terms of discovering content worth reading. So I decided to apply the approaches used by those American services myself.
The approach is as follows.
- Crawl all news articles and content in real time from domestic media outlets, well-known blogs, and more, and store them in a database.
- Extract nouns from the crawled articles and index them.
- When a user logs into the app with a Facebook account, analyze the posts they have written on Facebook to infer that user's interests.
- Based on the user's inferred interests, recommend related news by considering extracted nouns, publication time, and other signals.
- Show news in a three-sentence summary rather than the full article first, and display related keywords explaining why the article was recommended.
- Track which recommended articles the user actually reads, saves, shares, or deletes, and feed that back into the next recommendation cycle.
To implement this, I used a variety of open-source projects and also published most of my source code. For the source list of domestic media and blogs, I used HanRSS. It had a popular RSS page, so I added newly listed blogs to my crawling list right away. (https://github.com/xissy/node-hanrss)
RSS alone does not give you the full article body, so I had to crawl each article directly from the site list created above. For that, I used a module that reads site-specific policies from JSON files and automatically scrapes the relevant sections. (https://github.com/xissy/node-crawl-baby)
That worked fine for most media sites, but Naver, Tistory, and a few others required special handling because of redirect logic in the page. I also had to implement that. (https://github.com/xissy/node-blog-request)
Next, I needed to isolate the pure article body from the header, footer, menu, and so on. For that I ported a Java-based open-source project called Boilerpipe. (https://github.com/xissy/node-boilerpipe)
The crawled article bodies were stored in the database together with metadata such as outlet and publication time. For extracting the basic meaning unit - nouns - and indexing from those article bodies, I used the Korean morphological analyzer mecab-ko. Mecab is an engine built in Japan, but it works very well for Korean. I want to thank Lee Yong-woon of Ridibooks and Yoo Young-ho of LG Electronics again for building and publishing it; they are people I would love to meet in person when I am back in Korea. I also ported it for use here. (https://github.com/xissy/node-mecab-ffi)
For article bodies, I extracted both the full text and a summary. I modified a simple text-summarization module that was already available publicly, adding Unicode support and features such as extracting sentences in order of importance. It worked well for summarizing news articles, which are already fairly well-written, into a few sentences, but it did not work reliably on more scattered writing. Since this project mainly handled news, I did not pursue that problem further. (https://github.com/xissy/node-summary)
When a user logs in with a Facebook account, I fetch the user's posts and likes, extract nouns from them, and store everything in the database. For each word, I measure how often it was mentioned and also build a graph of related words that were mentioned together. This becomes the foundation for inferring the user's interests, which is the basic data used for news recommendations. I then add article publication time as another factor on top of the similarity between user interests and article summaries.
Each news item shows the title, summary, outlet, publication time, and related keywords, and users can open the full article, like it, or delete it. The article list can also be requested in views such as recommended, read, liked, or deleted, and all of this was built as a RESTful API using Node.js and Express so it could be easily consumed by web and mobile clients.
I recorded user actions such as reading, liking, and deleting articles, and used those signals in the next round of recommendations via collaborative filtering. Users who liked the same article were treated as sharing interests. This was implemented using the Recom.io API that already existed, but at the moment the only users are me and a few people around me, so with collaborative filtering you really need more users before you can judge recommendation quality. (http://recom.io)
I also built both Android and iOS mobile apps. Android was implemented natively with android-query, and the iOS app is based on native code but uses UIWebView with zepto.js, pure.css, and rivets.js only for the content rendering portion, making it a hybrid app. Appcelerator Titanium is slow, and Apache Cordova and trigger.io feel too web-like, but building a custom hybrid app this way reduces native code while still letting me work in familiar HTML5 with styles and AJAX calls, so it gave me both performance and productivity. Since the flat design trend in iOS 7, I have seen many apps pull this off well. (https://github.com/xissy/ios-news4me, https://github.com/xissy/news4me-android)
Press enter or click to view image in full size
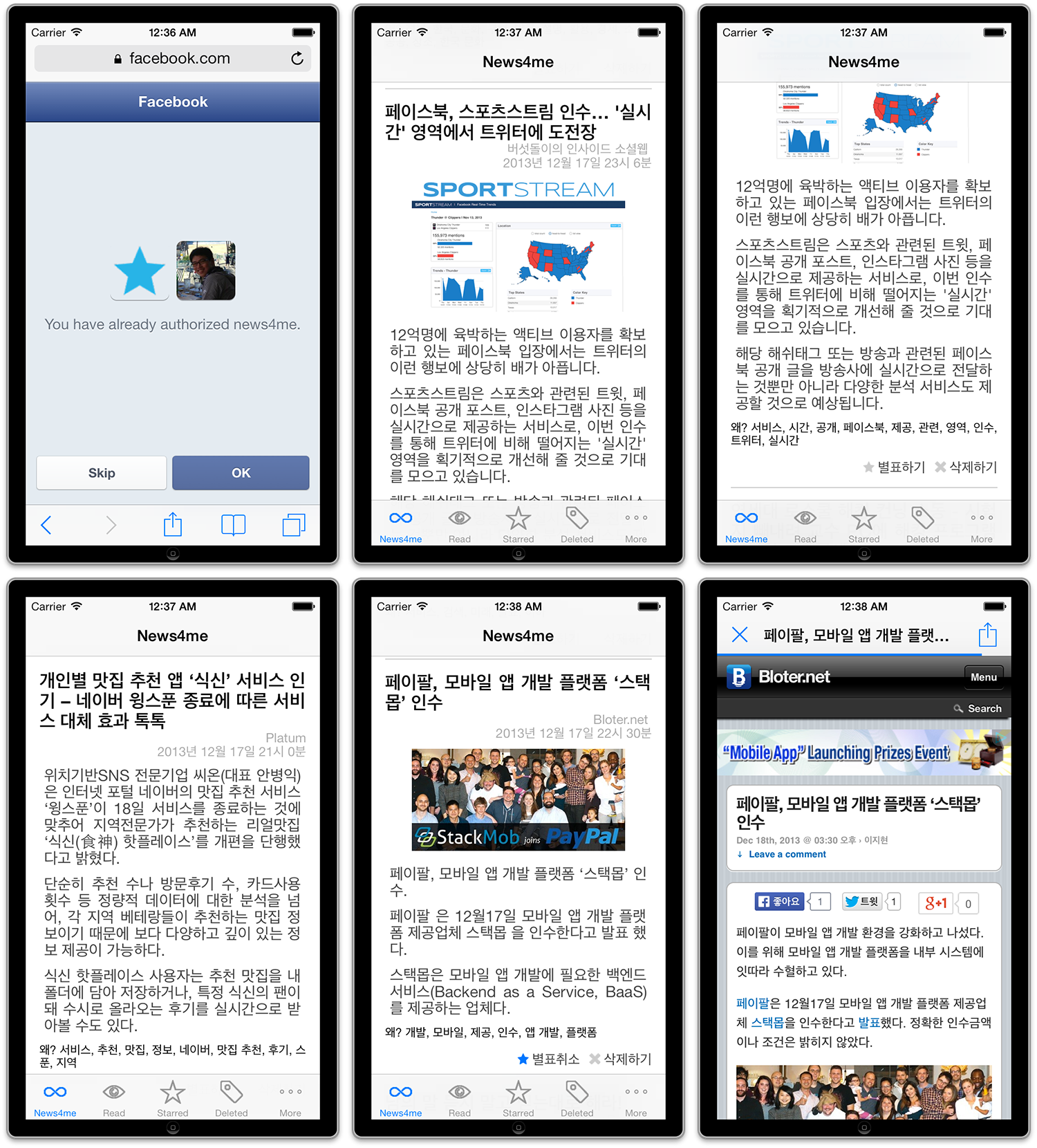
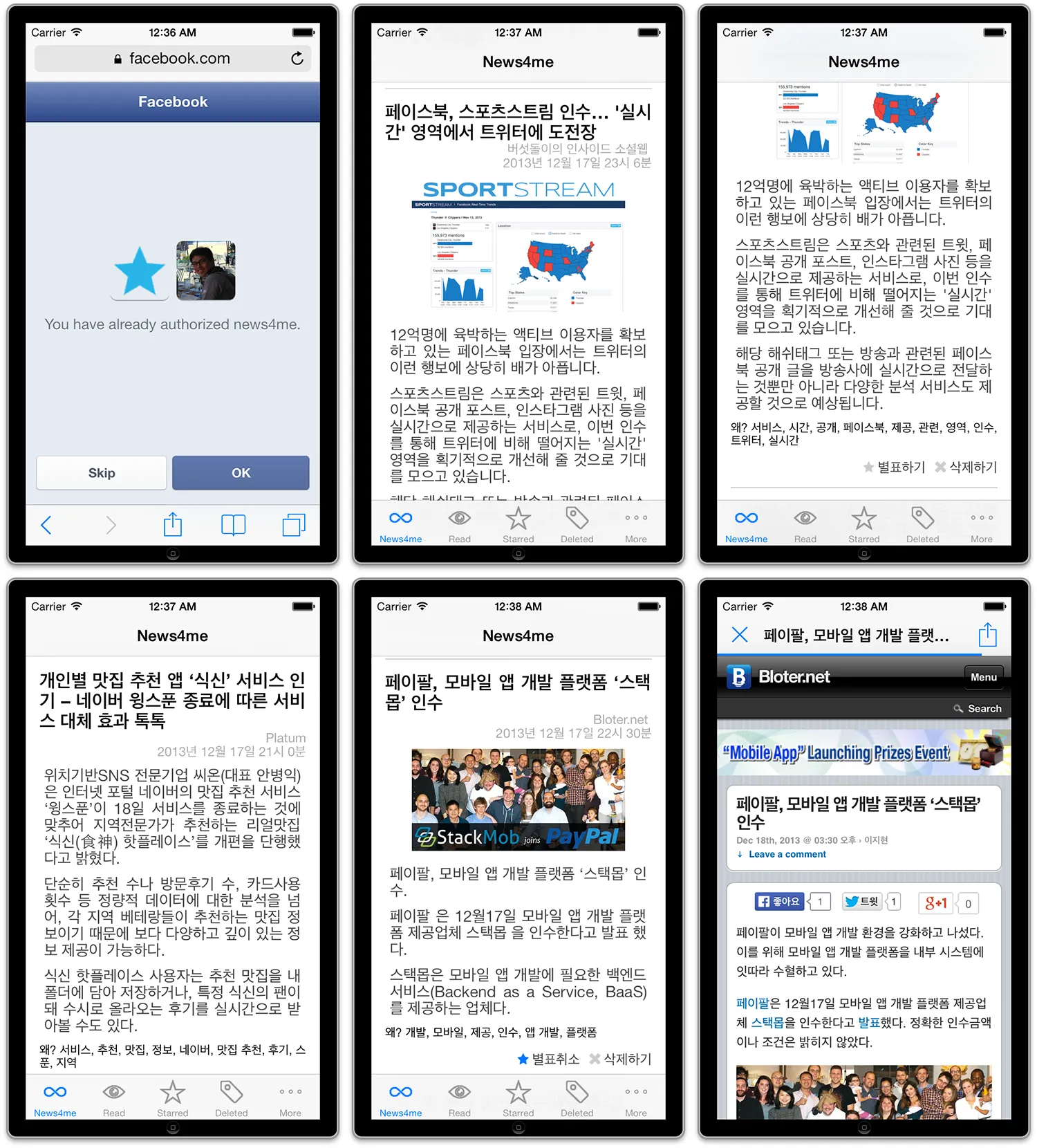
iPhone app screen. You can see that my interests are being reflected properly.
Press enter or click to view image in full size
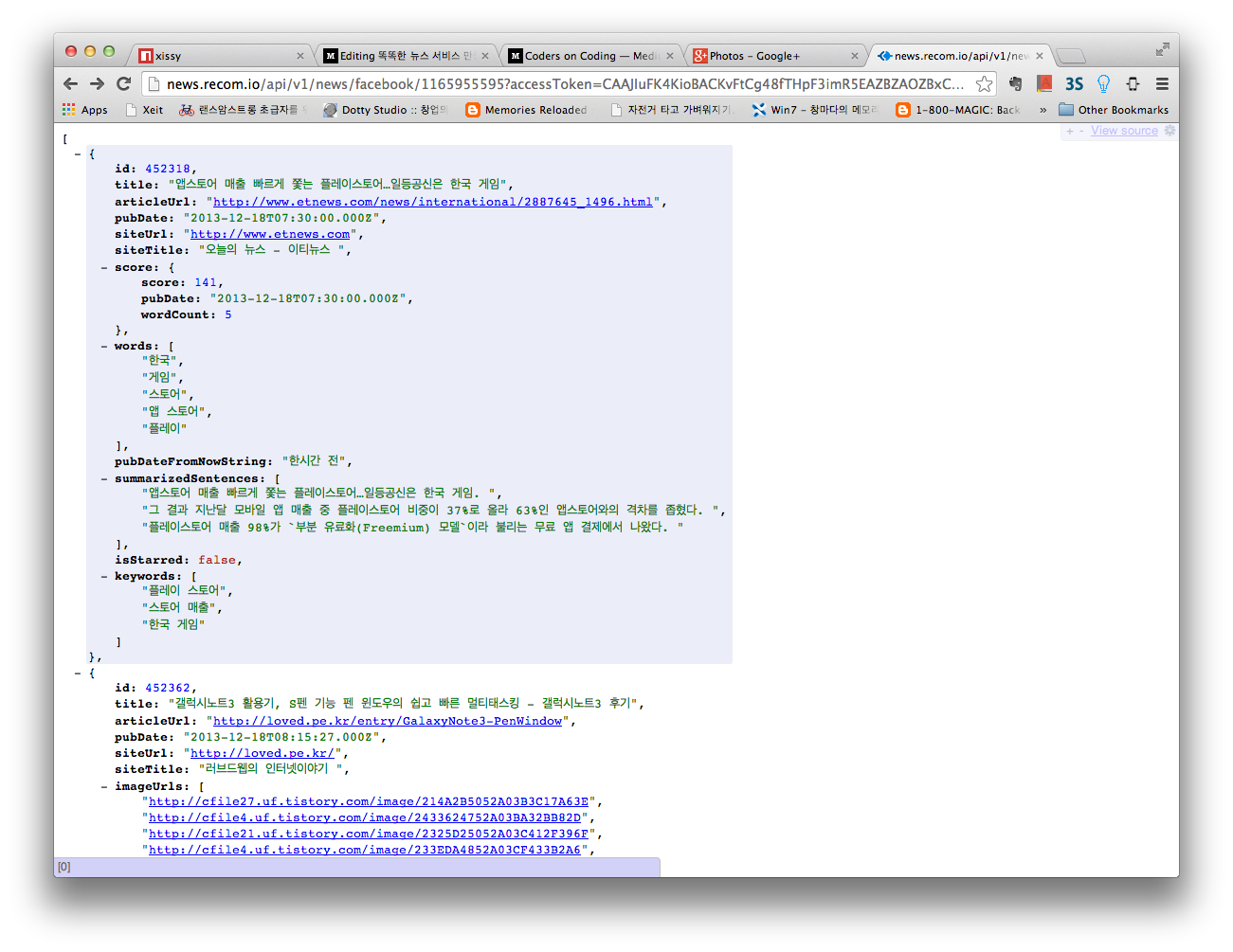
API call screen. All features are implemented as APIs, and the mobile app is just a shell.
Press enter or click to view image in full size
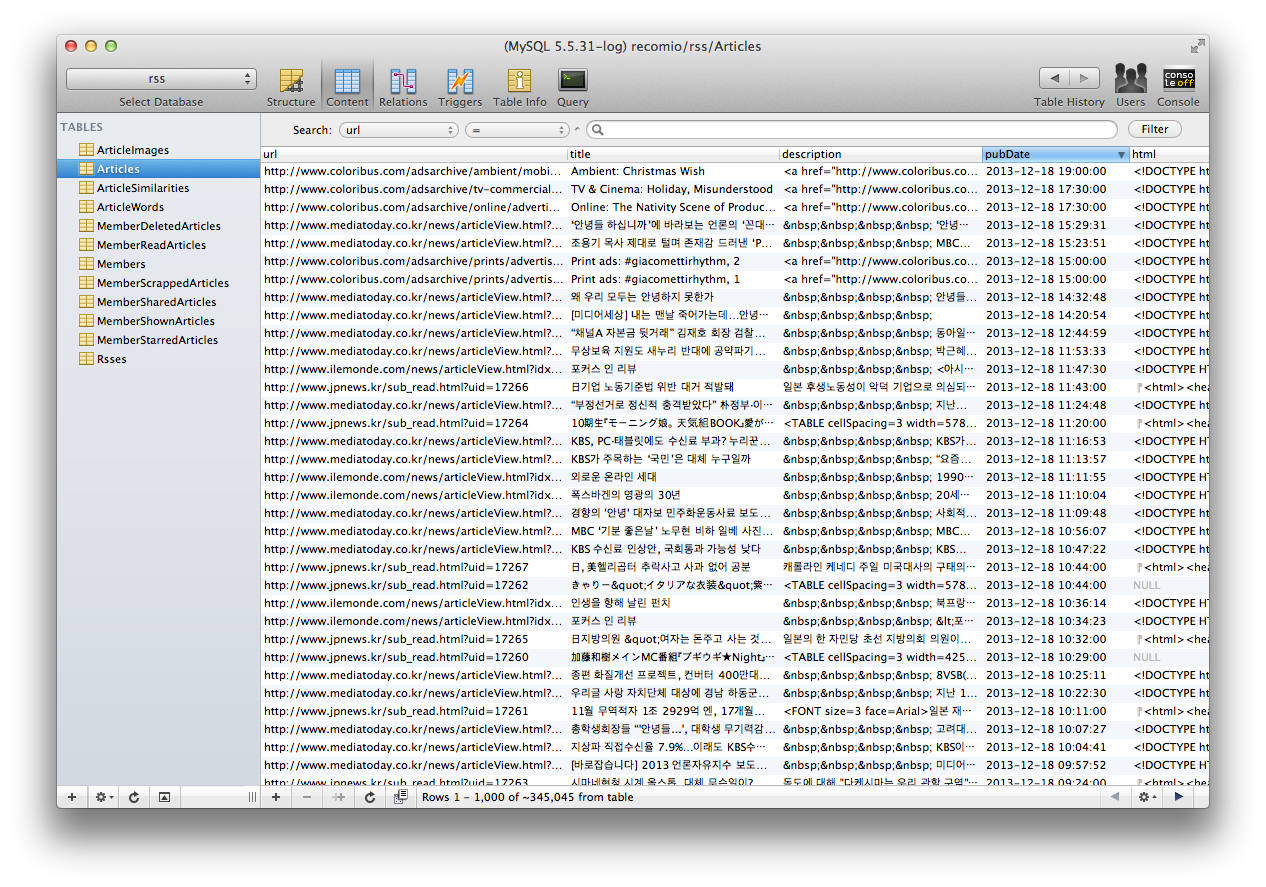
News articles stored in the database.
That is the background and implementation of the smart Korean news service I built. I use it happily myself, but I have not had time to polish it and upload it to the App Store because my main job is busy. Still, I am convinced that if attempts like this are researched and improved by others as well, better services will definitely emerge. If there is a team in Korea that wants to build a new news service, I hope my experience can be useful.
I am also willing to consult if you give me money or equity. ☺
