
Over the past few months, some users reported a decline in response quality from Claude. 📉 Taking these reports seriously, Anthropic investigated and identified three independent changes that affected Claude Code, the Claude Agent SDK, and Claude Cowork. Fortunately, the API was not impacted, and all issues were resolved as of April 20, 2026 (v2.1.116)! 🎉 This post explains what went wrong, how it was fixed, and what steps will be taken to prevent recurrence.
1. Change to Claude Code's Default Reasoning Effort Level 🧠
1.1. Switching Reasoning Effort from "High" to "Medium": Unintended Consequences 😥
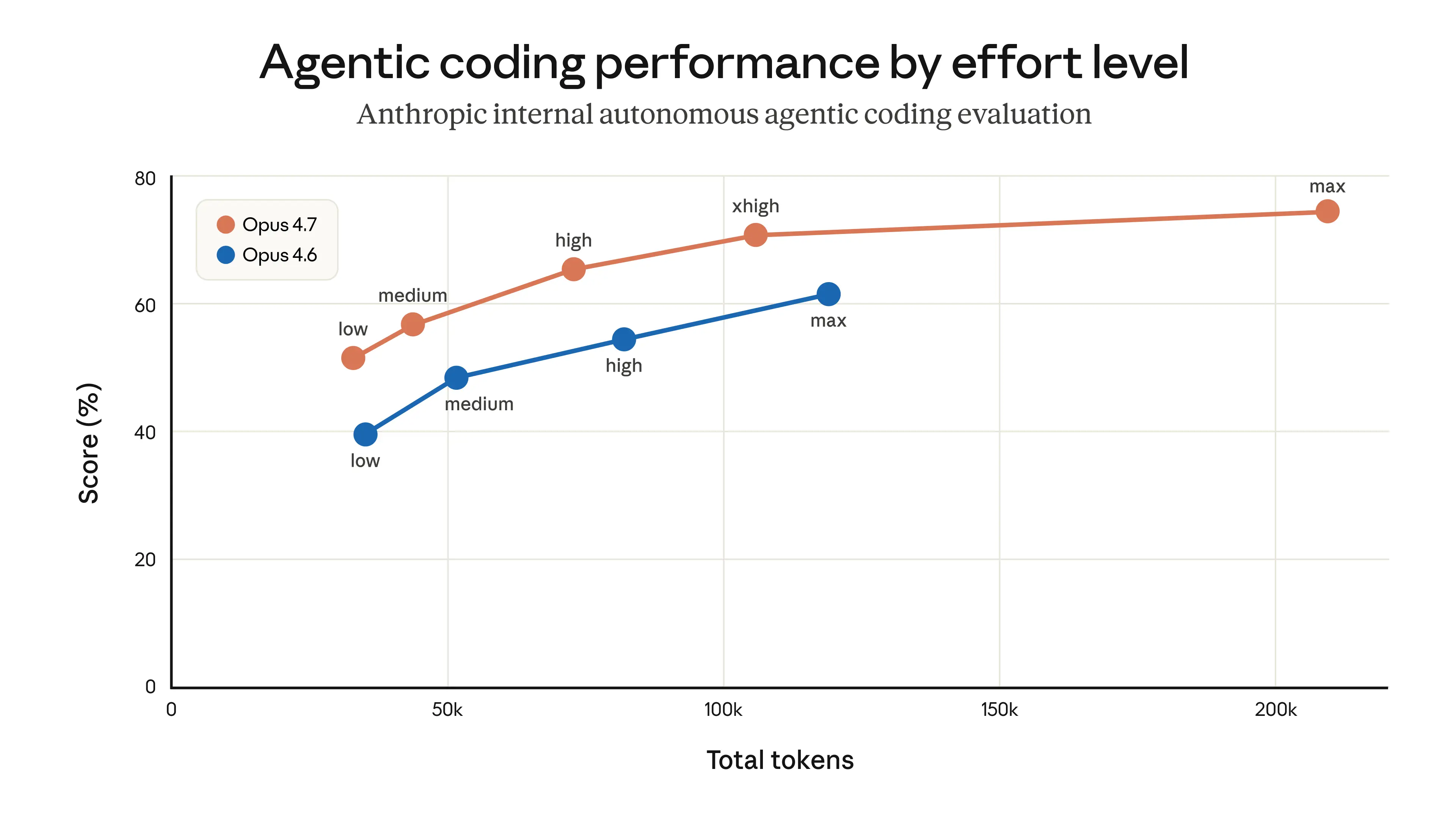
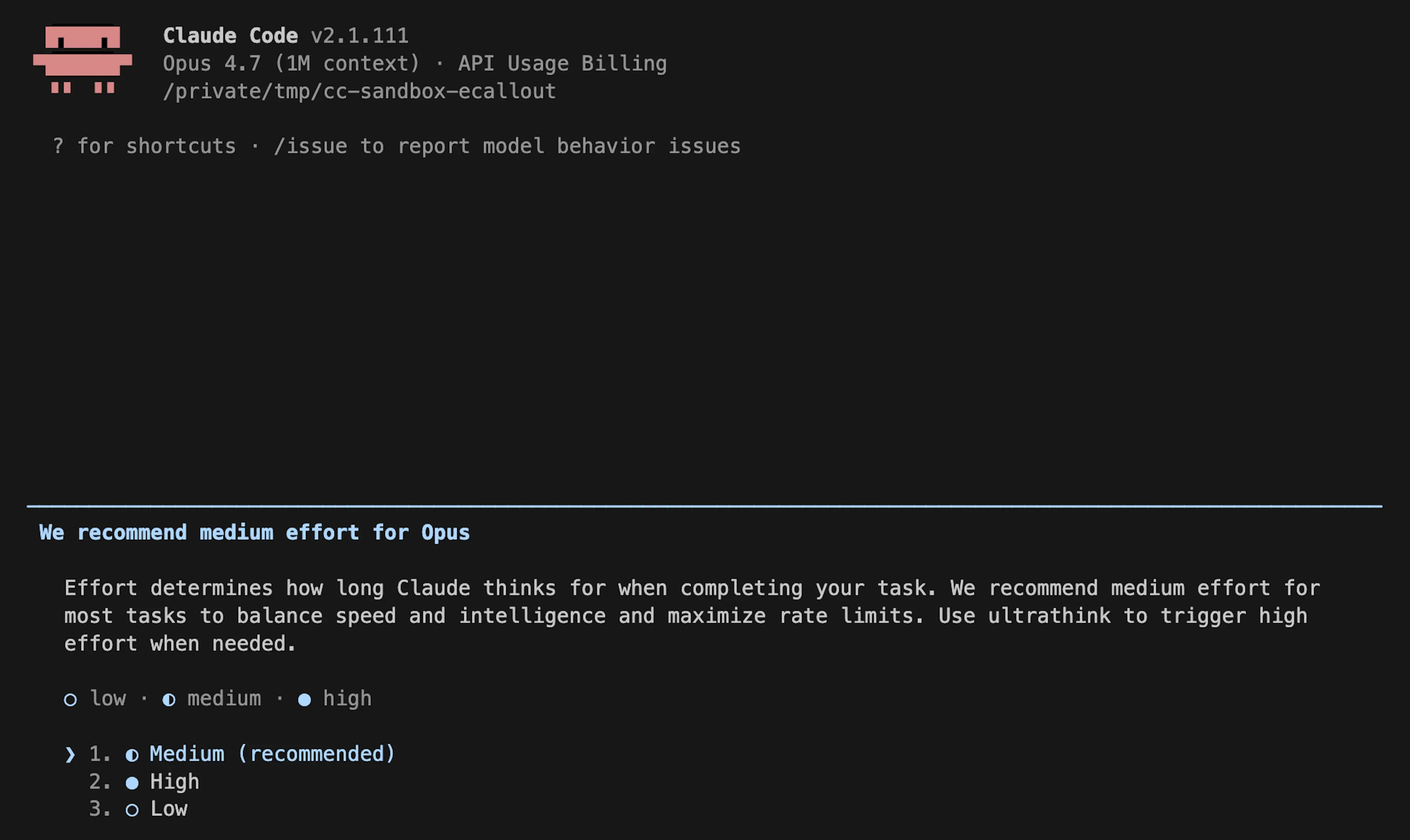
On March 4, 2026, the default reasoning effort level in Claude Code was changed from "high" to "medium" in order to reduce excessively long latency. Some users on "high" mode were experiencing delays long enough to make the UI appear frozen. While longer thinking improves output quality, it also increases latency and token usage. The tradeoff was evaluated, and "medium" effort was judged to deliver sufficiently good performance for most tasks at lower latency.
"We received user feedback that Claude Opus 4.6 in high reasoning effort mode was sometimes thinking too long, making the UI appear frozen and causing disproportionate latency and token usage for users."
However, this decision had unintended consequences. After the default was changed to "medium," many users began to feel that Claude Code had become less intelligent.
1.2. Listening to User Feedback and Rolling Back 🔄
After listening carefully to strong user feedback, it became clear that users prefer higher intelligence and only want lower effort for simple tasks. As a result, on April 7, 2026, the change was rolled back — restoring the default effort level for Opus 4.7 to "xhigh" and for all other models to "high."
2. Bug That Deleted Prior Reasoning History 🐛
2.1. A Severe Bug Introduced During Caching Optimization 🤯
On March 26, 2026, a caching optimization was deployed to improve Claude's efficiency. When Claude reasons through a task, the thinking process is normally stored in the conversation history so Claude can keep track of what edits it made and what tool calls it issued. The intent was to delete prior reasoning history for sessions that had been idle for more than an hour, reducing latency when resuming those sessions.
2.2. Claude Develops "Amnesia" 😵💫
However, a serious bug occurred during implementation. Contrary to the intent, the bug caused prior reasoning history to be deleted on every turn for the remainder of a session. Once a session crossed the idle threshold, all subsequent requests instructed the API to keep only the most recent reasoning block and discard everything before it. If Claude sent a follow-up message mid-tool-use, even the current turn's reasoning was deleted. The result was that Claude could no longer remember why it was doing what it was doing — leading to repeated forgetting, repetitive responses, and strange tool choices. Users described Claude as behaving like it had "amnesia."
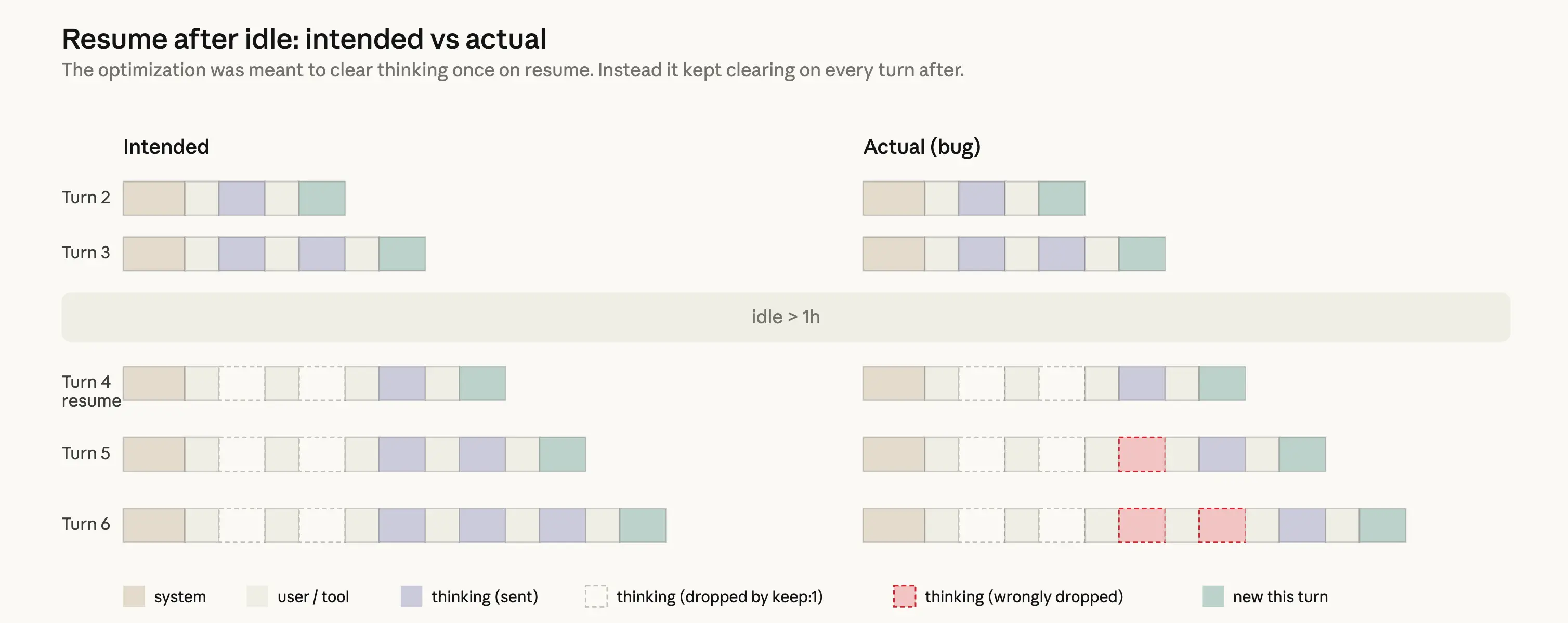
The bug also caused cache misses, leading to reports that usage limits were being exhausted faster than expected.
2.3. Discovering and Fixing the Bug 🔍
This bug was a compound issue involving Claude Code's context management, the Anthropic API, and extended thinking capabilities. Despite multiple code reviews, tests, and real-world usage, the bug took over a week to find and confirm because it only manifested in specific circumstances (long-running sessions) and was difficult to reproduce. Notably, during the investigation, Opus 4.7 was used to perform a code review on the buggy pull request. Opus 4.7 caught the bug — but Opus 4.6 did not! 😮
"As part of the investigation, we retroactively tested the problematic pull request using code review. When provided with the code repository needed to gather full context, Opus 4.7 identified the bug — but Opus 4.6 did not."
The bug was fixed on April 10, 2026, in v2.1.101.
3. System Prompt Change to Reduce Verbosity 📝
3.1. The Verbosity Problem with Opus 4.7 🗣️
The latest model, Claude Opus 4.7, tends to give more detailed responses compared to prior models. While this helps with complex problem-solving, it also generates more output tokens. To address this, various approaches were explored, and the following instruction was added to the system prompt:
"Length limit: keep text between tool calls to 25 words or fewer. Keep final responses to 100 words or fewer unless the task requires more detail."
This change showed no issues during several weeks of internal testing and evaluation, and was deployed alongside Opus 4.7 on April 16, 2026.
3.2. Coding Quality Degradation Discovered and Immediately Rolled Back ⏪
However, during further investigation, broader evaluations revealed that this prompt change reduced coding quality by 3% on both Opus 4.6 and Opus 4.7. The prompt was immediately rolled back on April 20, 2026.
4. What Will Change Going Forward 🚀
A great deal was learned from these incidents, and several improvements are planned to prevent recurrence.
- More internal employees using public builds: More internal staff will use the same public Claude Code builds as end users, enabling earlier detection of issues.
- Improved code review tooling: The internal code review tool will be improved and made available to customers. In particular, additional repository support will be added so the tool can obtain full context.
- Stronger system prompt change management:
- Broad, model-specific evaluations will be performed for all system prompt changes.
- Ablation tests will continue to be run to understand the impact of each line.
- New tooling has been built to make prompt changes easier to review and audit.
- Guidelines have been added to CLAUDE.md to ensure model-specific changes apply only to the intended model.
- Changes that may trade off intelligence will require a grace period, broader evaluation suites, and gradual rollout to catch issues earlier.
- Stronger communication channels: In-depth updates on product decisions and their rationale will be shared via X (@ClaudeDevs) and centralized threads on GitHub.
User feedback was essential in identifying and resolving these issues. A sincere thank you to everyone who shared their experiences, especially those who used the /feedback command. 🙏
Conclusion 🌟
The recent Claude quality degradation was caused by three independent factors: a change to the reasoning effort level, a bug that deleted prior reasoning history, and a system prompt change. All three issues have been resolved, and internal processes, testing, and review procedures will be strengthened to prevent similar problems in the future. We are deeply grateful for users' valuable feedback and patience. Starting April 23, 2026, usage limits have been reset for all subscribers. We are committed to delivering a better Claude going forward! 💖