DoWhy는 인과 그래프 모델과 잠재 결과 프레임워크를 통합해 인과 추론 과정을 구조적으로 지원하는 Python 라이브러리입니다. 인과 효과 추정, 반사실 분석, 원인 분석 등 다양한 인과적 질문에 대한 답을 쉽게 구하고, 초보자도 신뢰할 수 있는 분석을 할 수 있도록 설계된 것이 큰 장점입니다. 이 요약에서는 DoWhy의 특징, 사용 방법, 제공 기능 그리고 참고할 만한 자료에 대해 시간 흐름에 따라 자세히 안내합니다.
1. 프로젝트 및 커뮤니티 개요
DoWhy란 무엇인가?
DoWhy는 변수 간 인과 관계를 명확하게 모델링하고, 인과 추정을 직접적으로 검증할 수 있는 오픈소스 Python 라이브러리입니다. 단순한 예측을 넘어서 "무엇이 무엇에 영향을 미쳤는가?", "특정 변수를 바꾸면 결과가 어떻게 달라질까?" 등 인과적 질문에 답할 수 있도록 지원합니다.
"의사결정은 여러 변수 간의 상호작용을 이해하고, 일부를 새로운 값으로 변경했을 때 결과가 어떻게 바뀌는지 예측하는 것을 포함합니다."
DoWhy는 PyWhy 생태계의 일부로, PyWhy GitHub에 방문하면 인과추론 관련 다양한 도구도 함께 확인 가능합니다. 실무자와 연구자, 개발자들이 사용하는 만큼, Discord 커뮤니티 등에서 적극적인 질의응답과 사례 공유도 이루어지고 있습니다.
"특정 사용 사례에 대한 질문이나 의견, 토론이 필요하다면 저희 Discord 커뮤니티에 참여하세요."
- 공식 문서: https://py-why.github.io/dowhy
- PyWhy GitHub: https://github.com/py-why/
- 커뮤니티(Discord): https://discord.gg/cSBGb3vsZb
2. 적용 사례 및 실전 예시
DoWhy는 실제 다양한 업무에서 아래와 같은 인과적 질문을 해결하는 데 쓰이고 있습니다.
- 효과 추정: 호텔 예약 취소의 인과적 원인, 고객 멤버십의 효과, 기사 제목 최적화, 영유아 건강증진 방문 효과, 고객 이탈 원인 등
(호텔예약 취소 사례, 멤버십 효과 등) - 원인 분석/설명: 온라인 상점의 이상현상 원인, 마이크로서비스 구조에서의 지연 발생, 공급망 변화의 원인 파악 등
(온라인 상점 원인 분석, 공급망 변화 등)
더 많은 예시는 DoWhy 예제 노트북에서 볼 수 있습니다.
3. DoWhy의 구조와 핵심 기능
DoWhy는 인과 그래프 모델(graphical models)과 잠재 결과(potential outcomes)라는 양대 개념을 통합하여 효과적으로 인과 추론을 지원합니다.
특히 다음과 같은 작업을 직접적으로 지원합니다:
- 효과 추정: 인과 효과의 식별, 평균/조건부 인과효과, 도구변수 활용 등
- 인과 영향 수치화: 매개효과 분석, 직접 경로 강도 측정 등
- What-if & 반사실 분석: 개입(distribution intervention), counterfactual('만약 ~였다면?') 분석
- 원인 분석 및 설명: 이상 현상에 대한 원인 추적, 특성의 인과적 중요도 평가 등
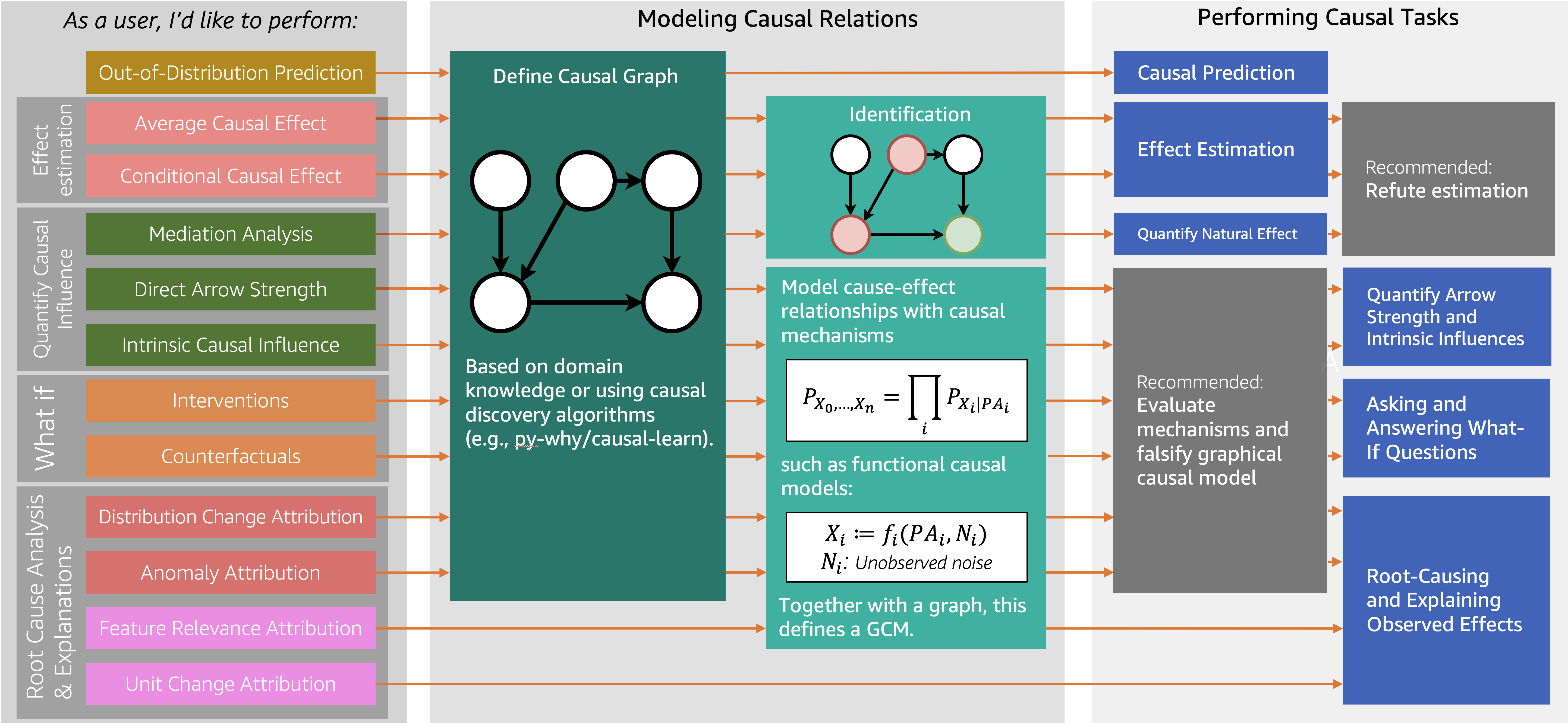
특히, 가정 검증(refutation & falsification) API를 통해 결과의 신뢰성을 직접적으로 테스트할 수 있다는 점이 초보자에게도 큰 장점입니다.
"DoWhy는 인과 가정의 검증 기능을 모든 추정 방법과 결합하여 추론을 더욱 실질적이고 신뢰할 수 있도록 만듭니다."
4. 설치 및 시작하기
설치 방법
Python 3.8 이상을 지원하며, pip, poetry, conda 등 다양한 방법으로 아주 간단하게 설치할 수 있습니다.
- pip:
pip install dowhy - poetry:
poetry add dowhy - conda:
conda install -c conda-forge dowhy
개발 최신 버전을 쓰고 싶다면 다음과 같이 GitHub 리포지토리에서 바로 설치 가능합니다.
pip install git+https://github.com/py-why/dowhy@main
추가 패키지 및 설치 팁
그래프 입력/시각화를 더 잘 하고 싶으면 pydot 또는 pygraphviz를 QR코드 형식으로 별도 설치할 수 있습니다. Ubuntu의 경우:
sudo apt install graphviz libgraphviz-dev graphviz-dev pkg-config
pip install --global-option=build_ext \
--global-option="-I/usr/local/include/graphviz/" \
--global-option="-L/usr/local/lib/graphviz" pygraphviz
문제가 있다면 공식 pygraphviz 설치 가이드 참조가 좋습니다.
5. 빠른 예제: 인과 효과 추정 및 그래프 기반 분석
1) 인과 효과 추정의 기본 흐름
아래와 같이 네 단계만 거치면 데이터를 이용한 인과 추정이 가능합니다.
- 모델 생성: 데이터를 기반으로 인과 그래프를 정의하여 모델링
- 효과 식별: 인과 그래프상에서 효과 도출을 위한 조건 및 변수 확인
- 효과 추정: 통계/머신러닝 방법 활용하여 효과 실제 추정
- 결과 반증: 무작위 변인 추가 등 여러 테스트로 결과 신뢰성 검증
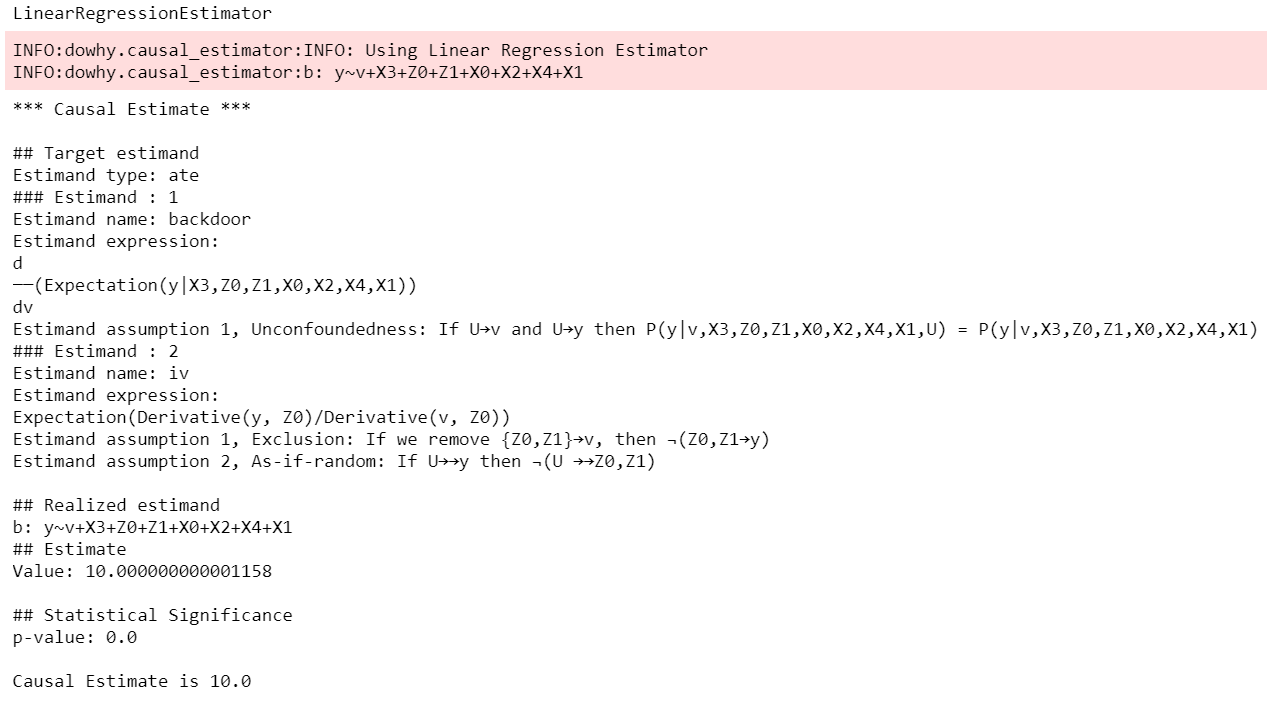
from dowhy import CausalModel
import dowhy.datasets
# 데이터 불러오기
data = dowhy.datasets.linear_dataset(
beta=10,
num_common_causes=5,
num_instruments=2,
num_samples=10000,
treatment_is_binary=True)
# 1. 인과모델 생성
model = CausalModel(
data=data["df"],
treatment=data["treatment_name"],
outcome=data["outcome_name"],
graph=data["gml_graph"]) # 또는 nx.DiGraph 사용
# 2. 효과 식별
identified_estimand = model.identify_effect()
# 3. 효과 추정
estimate = model.estimate_effect(identified_estimand, method_name="backdoor.propensity_score_matching")
# 4. 결과 반증
refute_results = model.refute_estimate(identified_estimand, estimate, method_name="random_common_cause")
DoWhy의 출력은 과정별로 가정, 식별된 인과 효과, 추정값 전체를 직접 눈으로 확인할 수 있게 지원합니다.
- 더 많은 예시: Getting Started with DoWhy
- EconML 라이브러리를 활용한 Conditional Average Treatment Effect (CATE) 예시도 공식 노트북에서 볼 수 있습니다.
2) 그래프 기반 모델링(GCM) 및 원인 추적 분석
Pearl의 구조적 인과모형(Structural Causal Model) 프레임워크에 기반한 DoWhy-GCM을 활용하면 복잡한 원인 분석/시나리오 시뮬레이션이 가능합니다.
예를 들어, 아래처럼 X→Y→Z인 단순 구조를 만들어 보고, Z의 이상값 발생 원인을 역추적으로 찾을 수 있습니다.
import networkx as nx, numpy as np, pandas as pd
from dowhy import gcm
# 1. 데이터 생성 및 구조적 인과모형 정의
data = pd.DataFrame(dict(
X=np.random.normal(loc=0, scale=1, size=1000),
Y=2 * X + np.random.normal(loc=0, scale=1, size=1000),
Z=3 * Y + np.random.normal(loc=0, scale=1, size=1000),
))
causal_model = gcm.StructuralCausalModel(nx.DiGraph([('X','Y'), ('Y','Z')])) # X→Y→Z 연결
gcm.auto.assign_causal_mechanisms(causal_model, data)
# 2. 모델 피팅
gcm.fit(causal_model, data)
# 3. Z의 이상값 원인이 어디인지 분석
anomalous_sample = pd.DataFrame(dict(X=[0.1], Y=[6.2], Z=[19])) # 이상값
anomaly_attribution = gcm.attribute_anomalies(causal_model, "Z", anomalous_sample)
- 더 많은 활용법 및 예시: Online Shop 예제, User Guide
6. 참고 자료 및 추가 정보
- Microsoft Research Blog: DoWhy 소개글
- 튜토리얼 영상
- 관련 논문
- 슬라이드 자료: Slideshare
- 기여/이슈/문의
"DoWhy가 여러분의 연구나 업무에 유용하다면, 반드시 아래 두 논문을 모두 인용해주세요."
7. 인용 정보
@article{dowhy,
title={DoWhy: An End-to-End Library for Causal Inference},
author={Sharma, Amit and Kiciman, Emre},
journal={arXiv preprint arXiv:2011.04216},
year={2020}
}
@article{JMLR:v25:22-1258,
author = {Patrick Bl{{\"o}}baum and Peter G{\"o}tz and Kailash Budhathoki and Atalanti A. Mastakouri and Dominik Janzing},
title = {DoWhy-GCM: An Extension of DoWhy for Causal Inference in Graphical Causal Models},
journal = {Journal of Machine Learning Research},
year = {2024},
volume = {25},
number = {147},
pages = {1--7},
url = {http://jmlr.org/papers/v25/22-1258.html}
}
마치며
DoWhy는 인과 추론을 쉽고, 투명하며, 신뢰성 있게 수행하고자 하는 모든 분들에게 훌륭한 도구입니다. 데이터 분석이 '왜'라는 본질적인 질문에 집중할 수 있도록 돕는 만큼, 인과적 분석을 시도해보고 싶은 분이라면 한 번쯤 꼭 사용해보시기를 추천드립니다! 🚀
궁금한 점은 언제든 커뮤니티에 질문해보세요.