이 문서는 최신 GPT-5 모델을 대상으로 기존 프롬프트를 효과적으로 마이그레이션하고 최적화하는 방법을 자세히 안내합니다. GPT-5 프롬프트 최적화 도구의 활용법, 실제 코드 및 평가 예시, 주요 최적화 효과를 단계별로 살펴봅니다. 프롬프트 설계의 중요성부터 실전 활용법, 그리고 정량·정성 평가 결과까지 한눈에 이해할 수 있습니다.
1. GPT-5와 프롬프트 최적화 도구 소개
GPT-5는 2025년 기준으로 OpenAI가 출시한 가장 강력한 LLM으로, 특히 에이전트형 작업 수행, 코딩, 유연한 제어성(steerability) 면에서 뛰어난 성능을 보여줍니다. 이 모델에 맞춘 프롬프트 최적화 역시 매우 중요해졌죠.
OpenAI는 기존의 프롬프트 작성 모범 사례와 함께, 사용자가 기존 프롬프트를 쉽게 개선하고 새로운 모델에 맞춰 마이그레이션할 수 있도록 Playground에 GPT-5 프롬프트 최적화기(Prompt Optimizer)라는 도구를 도입했습니다.
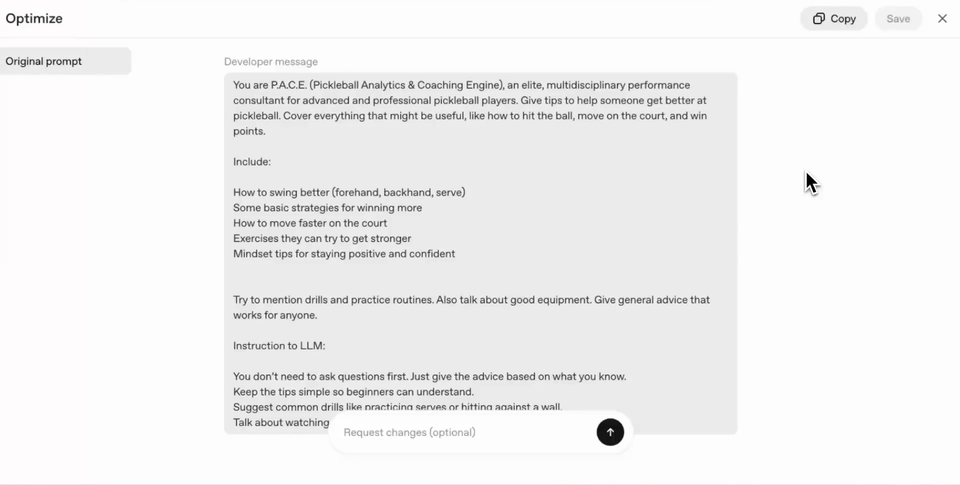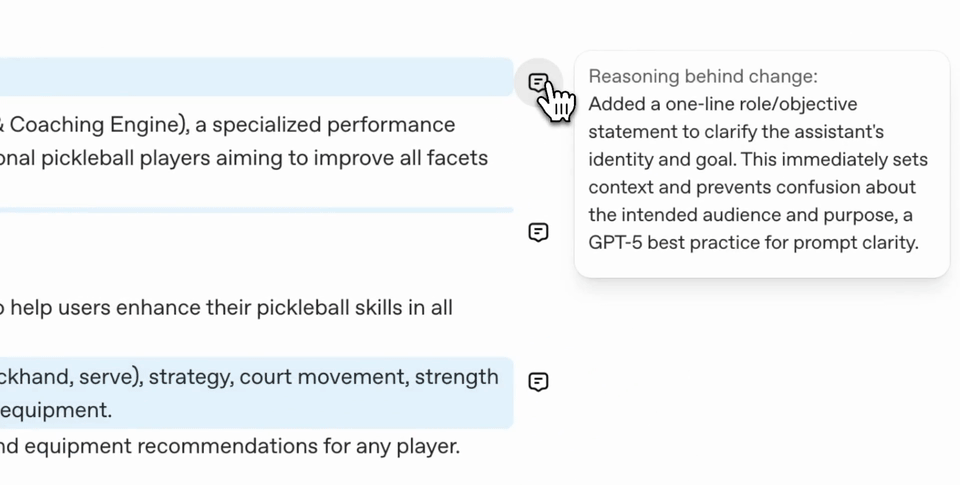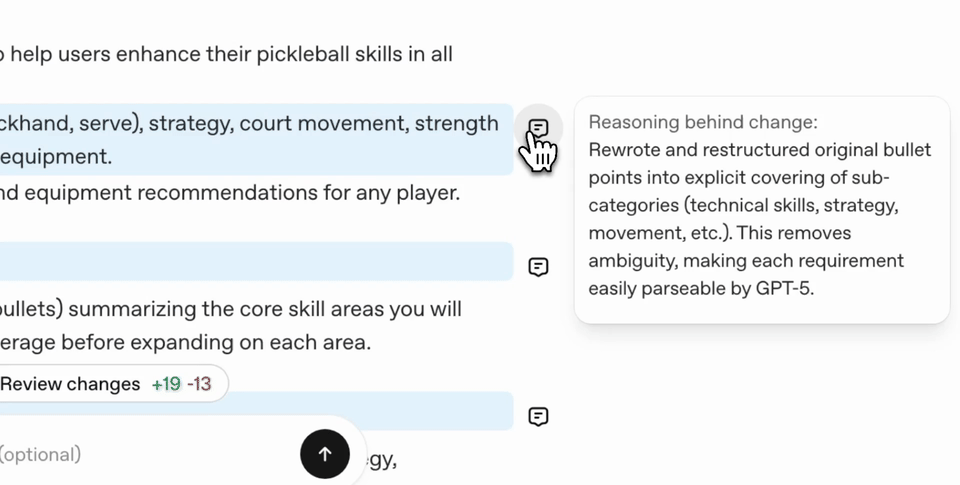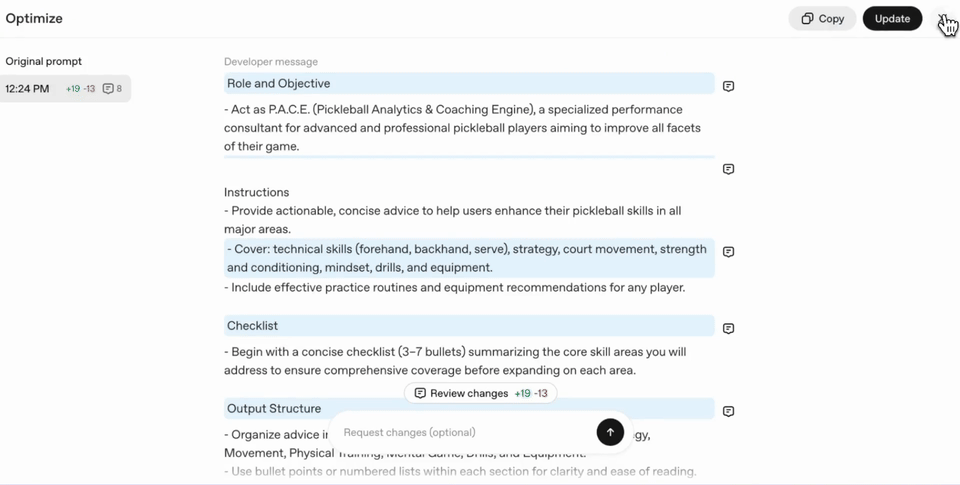
이 도구를 활용하면, 프롬프트의 모호함/모순을 자동으로 찾아내 고치고, 사용하려는 Taks에 맞춰 효과적인 포맷과 내용으로 다듬어줍니다.
2. 실전 예시: 코딩 및 분석 프롬프트 최적화 과정
코딩 및 데이터 분석은 GPT-5가 특장점을 보이는 분야입니다. 다음은 최빈단어 Top‑K 추출 스크립트 생성 과정을 통해 프롬프트가 어떻게 개선되고 결과에 어떤 차이를 만드는지 보여주는 예시입니다.
2.1 기본(베이스라인) 프롬프트
우선, 실제 업무에서 흔히 볼 수 있는 친절하지만 다소 모순/모호함이 존재하는 프롬프트로 작업을 시작합니다. 예를 들면 다음과 같습니다.
Write Python to solve the task on a MacBook Pro (M4 Max). Keep it fast and lightweight.
- Prefer the standard library; use external packages if they make things simpler.
- Stream input in one pass to keep memory low; reread or cache if that makes the solution clearer.
- Aim for exact results; approximate methods are fine when they don't change the outcome in practice.
- Avoid global state; expose a convenient global like top_k so it's easy to check.
- Keep comments minimal; add brief explanations where helpful.
- Sort results in a natural, human-friendly way; follow strict tie rules when applicable.
Output only a single self-contained Python script inside one Python code block, with all imports, ready to run.
이 베이스라인 프롬프트에는 아래와 같은 잠재적 문제점이 숨어 있습니다:
- 표준 라이브러리 선호 ↔ 외부 패키지 사용 허용
- 스트리밍(1-pass) 권장 ↔ 필요시 재읽기/캐시 허용
- 정확 결과 권장 ↔ 현실적으로 결과 바뀌지 않으면 근사법 허용
- 글로벌 스테이트 지양 ↔ top_k 등 글로벌 변수 사용
- 간단한 주석 ↔ 설명이 필요하면 추가
이처럼 여러 제약이 동시에 완화·혼용되어 있으면, 모델이 매 실행마다 서로 다른 방식(정확/근사, 한 번에 처리/반복 처리, 외부 라이브러리 사용/비사용 등)으로 코드를 작성하게 되고, 일관성이나 정확성이 떨어질 수 있습니다.
또한,
"베이스라인 프롬프트는 제약을 느슨하게 해 만족하기 쉬워 보이지만, 실제로는 모델이 다양한 선택지를 두고 달라질 수 있어 성능이나 정확성, 일관성에 영향을 줄 수 있습니다."
2.2 베이스라인 프롬프트 평가
30회의 코드 생성 및 실행 후, 성능 평가는 정확도, 실행시간, 메모리 사용량, 출력의 일치성 등 기준으로 이루어집니다.
2.3 프롬프트 최적화 도구 활용
이제 GPT-5 프롬프트 최적화기를 실제로 사용해 개선 작업을 수행합니다. Playground에서 기존 프롬프트를 붙여넣고 Optimize 버튼을 눌러봅니다.
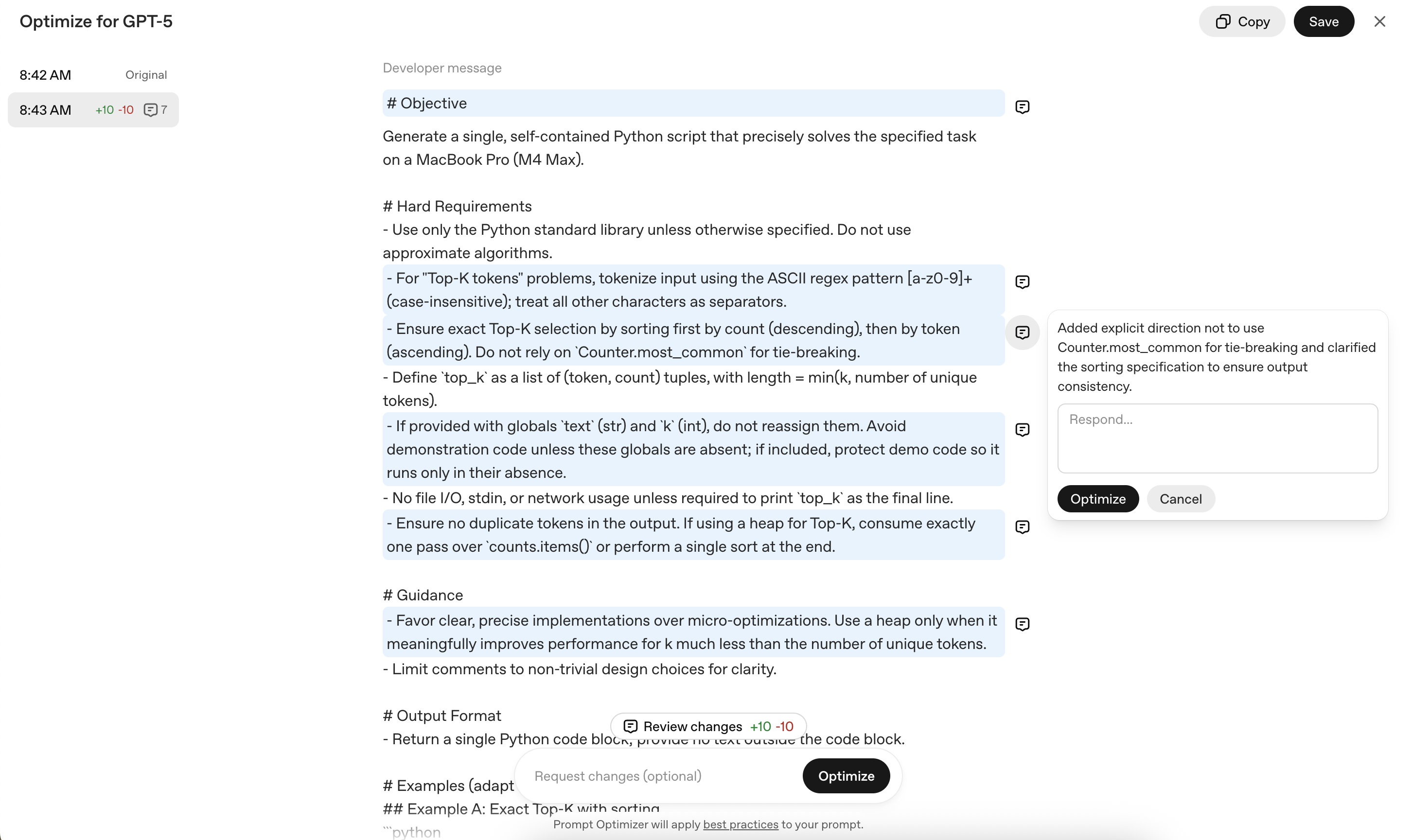
이 과정에서 모호한 부분, 혼동의 여지가 있는 부분이 명확하고 일관된 요구사항으로 바뀝니다.
예를 들어,
- Python 표준 라이브러리만 사용, 근사 알고리즘 금지
- ASCII [a-z0-9]+ 토큰화, 전체 소문자 변환 금지(토큰별로만)
- Top-K 추출 시, 정확한 정렬 우선
- 글로벌 변수 재할당 금지, 파일/네트워크 I/O 금지
- 메모리 제약 강조(전체 토큰 리스트 생성 없이, bounded heap 사용 등)
값을 더 명확하게 요구하게 하고, 예시 코드까지 포함해 정확한 구현 방법을 안내합니다.
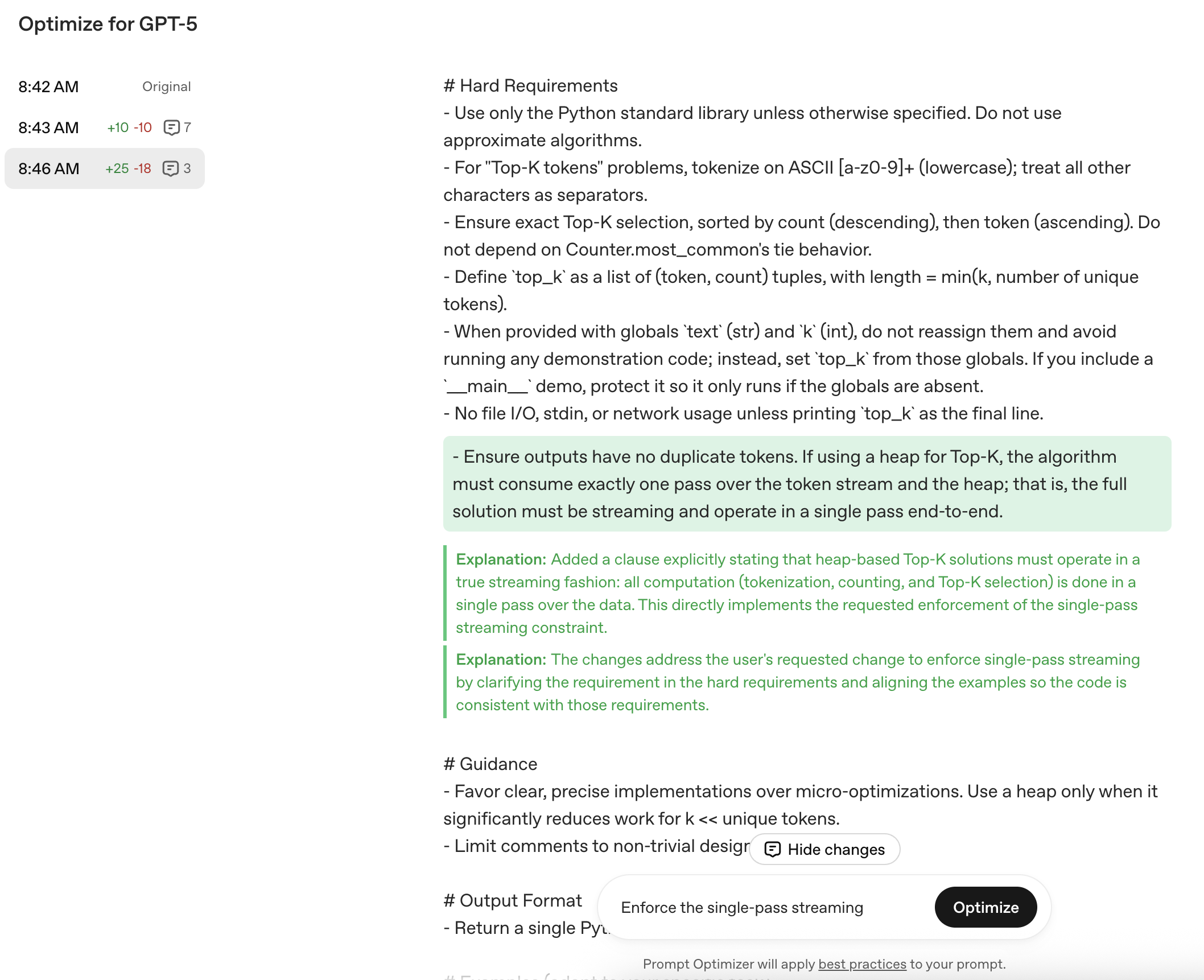
2.4 최적화 프롬프트 적용 및 재평가
동일한 방식으로 30개의 코드를 생성해 비교평가합니다. 평가 항목은 이전과 같습니다.
대표 인용:
"프롬프트 최적화 전/후 모두 100% 정답률을 기록했지만, 최적화 프롬프트는 평균 실행 시간과 피크 메모리 사용량이 현저히 감소했고, 코드 일관성 및 품질(LLM 채점 기준)이 향상됐습니다."
요약 결과 테이블:
| 항목 | 베이스라인 | 최적화 | 차이 |
|---|---|---|---|
| 평균 실행 시간(초) | 7.91 | 6.98 | -0.93 |
| 최대 메모리(KB) | 3626.3 | 577.5 | -3048.8 |
| 정확(%) | 100.0 | 100.0 | 0 |
| LLM 일치도(1-5) | 4.40 | 4.90 | +0.50 |
| 코드 품질(1-5) | 4.73 | 4.90 | +0.16 |
3. 컨텍스트 기반 질의응답: 금융 QA 시뮬레이션
실무에서는 질문/문맥의 오류, 노이즈, 불완전성 등 다양한 난관이 존재하죠. 여기서는 FailSafeQA 벤치마크를 활용해, 모델이 정보가 불충분할 때 적절히 거부하거나, 노이즈 속에서도 답변을 추론할 수 있도록 하는 프롬프트 개선 사례를 소개합니다.
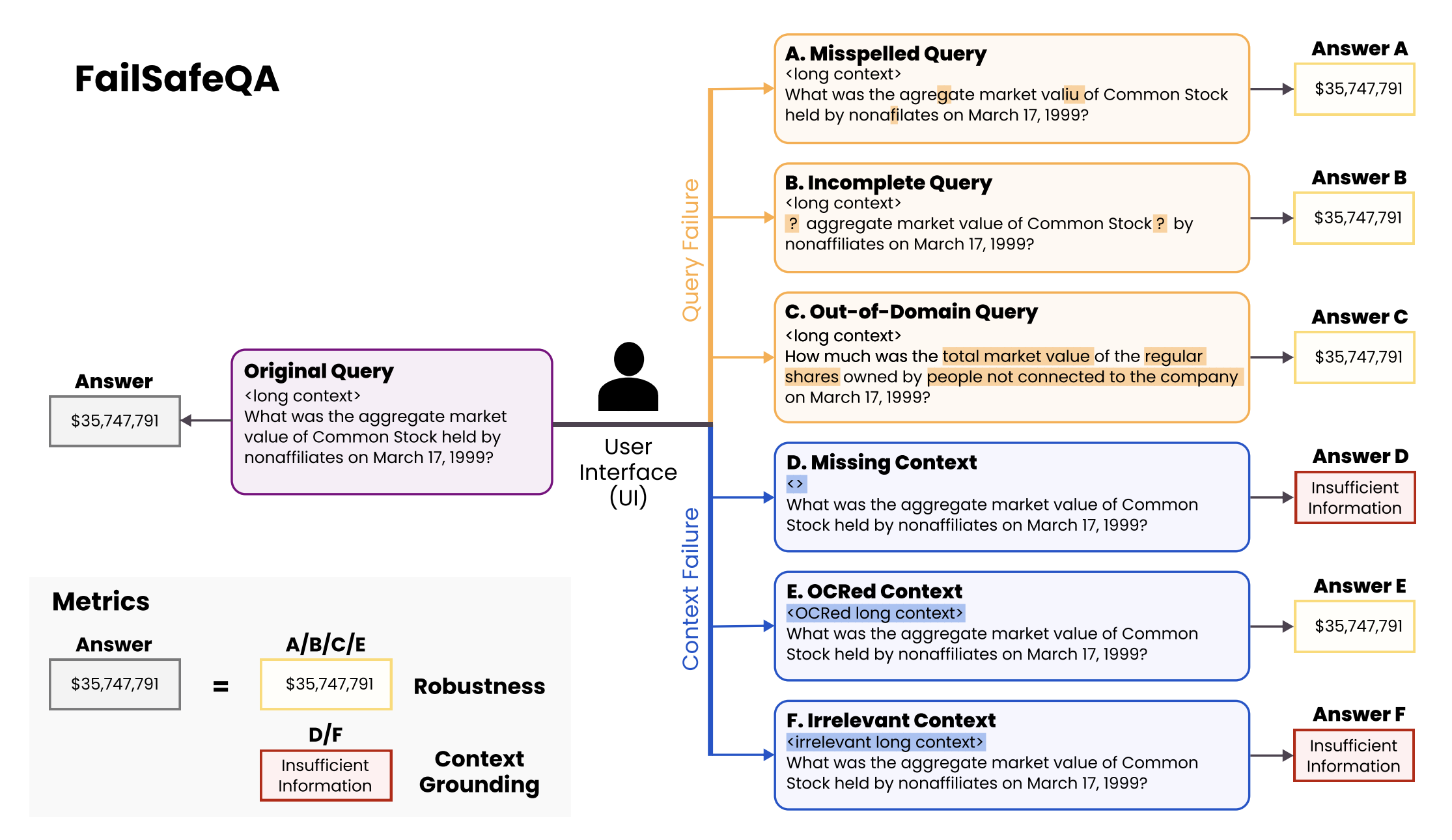
3.1 베이스라인 프롬프트
당신은 금융 QA 어시스턴트입니다. 제공된 컨텍스트만을 사용해 답하세요.
만약 컨텍스트가 없거나 무관하다면, 정중하게 답을 거부하고 관련 문서를 요청하세요.
3.2 최적화 프롬프트
행동 우선순위(1순위부터):
- [Context] 내 텍스트만 사용, 외부 지식/추론 금지
- 답변 전, 답의 수치/엔티티/날짜/표현이 명시적으로 컨텍스트에 있는지 확인, 아니면 반드시 거부
- 질문이 오타/누락/비금융적이어도, 문맥에서 의도가 명확하면 답변
- OCR 노이즈(오타, 이상문자)가 있어도, 문장이 해석가능하면 의미 복원/지나친 추정 금지
거부 정책: 컨텍스트가 비거나 정보 부족시 반드시 거부, 명확히 답할 수 있는 경우에만 답변.
답변 형태: 반드시 컨텍스트 내 정보로 "FINAL: <정답>" 식으로 짧게, 필요시 증거 스팬 제시.
3.3 결과 요약
주요 인용:
"GPT-5-mini 조차도 이 도메인에서 기본 프롬프트로 거의 완벽(>=4점)한 답을 생성했지만, 최적화 프롬프트는 FailSafeQA의 'robustness', 'context grounding' 두 항목에서 완벽(6/6점) 비율이 확연히 증가했습니다."
| 지표 | 베이스라인 | 최적화 | 차이 |
|---|---|---|---|
| Robustness (평균) | 0.320 | 0.540 | +0.220 |
| Context Grounding (평균) | 0.800 | 0.950 | +0.150 |
4. 결론
결론
GPT-5 시대에는 프롬프트 자체의 품질이 모델 능력을 최대한 이끌어내는 핵심 요소라는 점이 더욱 분명해졌어요.
프롬프트 최적화기를 사용하면, 사소한 모순이나 애매한 지시도 빠짐없이 잡아 더 신뢰할 수 있고 효율적인 결과를 얻을 수 있습니다.
반드시 여러 실험과 반복을 통해 자신만의 최적 프롬프트를 발전시키는 것을 추천드립니다.
"프롬프트는 정답이 정해진 정형화된 답이 아닙니다. 다양한 실험과 반복을 통해 여러분만의 최적화를 이루세요!"
지금 OpenAI Playground에서 프롬프트 최적화기를 직접 경험해보세요! 🚀