2025년 현재, GPT-2부터 DeepSeek-V3, Llama 4, Kimi 2까지 대형 언어모델(LLM) 아키텍처의 발전사를 시간순으로 살펴봅니다. 겉보기엔 비슷해 보이지만, 효율성과 성능을 높이기 위한 다양한 구조적 변화가 있었습니다. 이 글에서는 각 모델의 핵심 아키텍처 변화와 그 의미를 친절하게 정리합니다.
1. LLM 아키텍처의 7년: 기본 구조는 비슷, 디테일은 혁신적 변화
GPT-2(2019)에서 DeepSeek-V3, Llama 4(2024-2025)까지, 기본 구조는 크게 변하지 않았지만 세부적인 효율화와 성능 개선이 이어졌습니다.
예를 들어, 포지셔널 임베딩은 절대 방식에서 RoPE(회전적 위치 인코딩)로, Multi-Head Attention(MHA)은 Grouped-Query Attention(GQA)로, 활성화 함수는 GELU에서 SwiGLU로 바뀌었습니다.
"겉으로 보기엔 여전히 비슷해 보이지만, 정말 혁신적인 변화가 있었을까요, 아니면 같은 기반을 계속 다듬고 있는 걸까요?"
하지만 실제로는 데이터셋, 학습 기법, 하이퍼파라미터 등 다양한 요소가 성능에 영향을 주기 때문에, 아키텍처만으로 성능을 단정짓기는 어렵습니다.
그럼에도 불구하고, 2025년 현재 LLM 개발자들이 어떤 구조적 실험을 하고 있는지 살펴보는 것은 여전히 큰 의미가 있습니다.
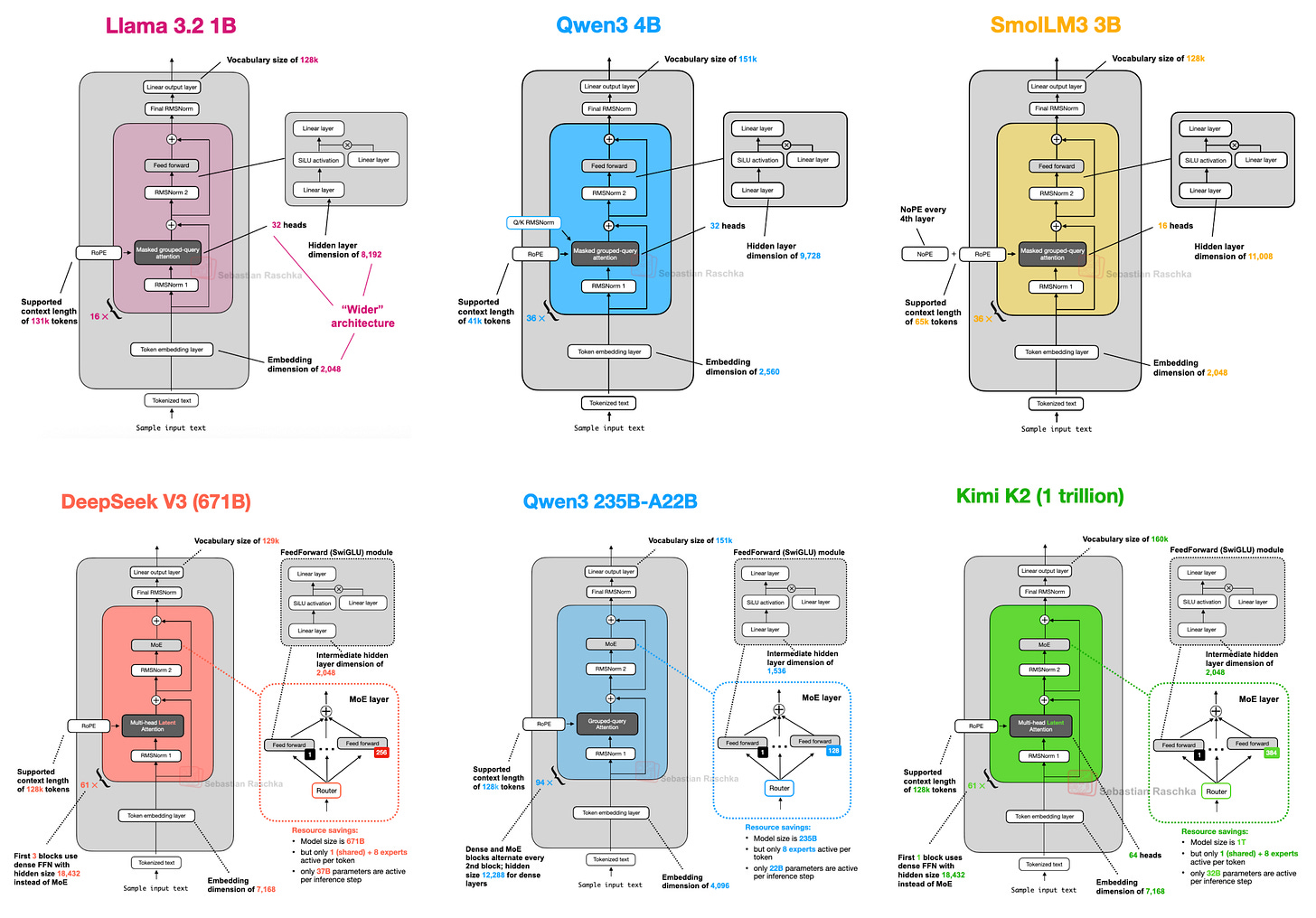
2. DeepSeek-V3/R1: MLA와 MoE로 효율과 성능 모두 잡다
2025년 1월 공개된 DeepSeek R1은 DeepSeek V3(2024년 12월 발표) 아키텍처를 기반으로 한 추론 특화 모델입니다.
DeepSeek V3의 핵심 구조적 특징은 다음 두 가지입니다.
- Multi-Head Latent Attention(MLA)
- Mixture-of-Experts(MoE)
2.1. MLA: 메모리 효율을 극대화한 새로운 어텐션
기존 MHA는 각 헤드마다 키와 값을 따로 계산하지만, GQA는 여러 헤드가 키/값을 공유해 메모리 사용량을 줄입니다.
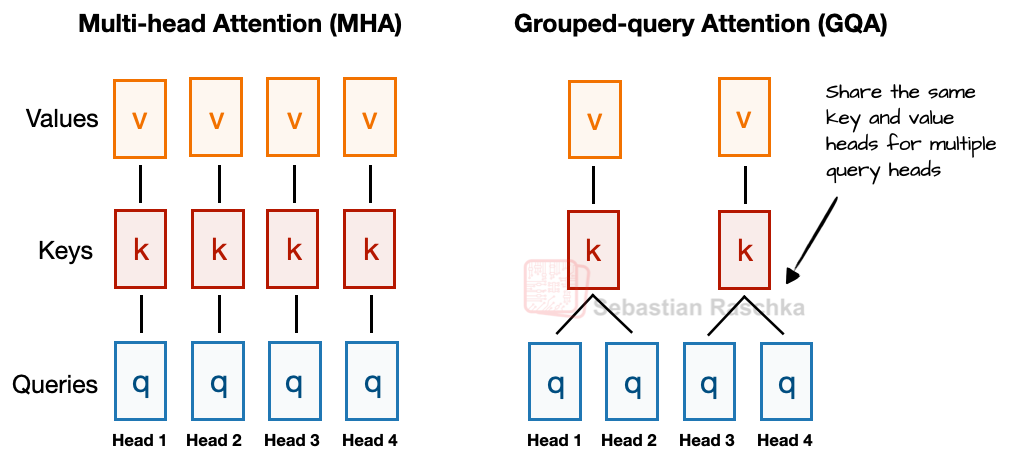
"GQA의 핵심은 여러 쿼리 헤드가 키/값을 공유해 파라미터 수와 메모리 사용량을 줄이는 데 있습니다."
MLA는 한 단계 더 나아가, 키/값 텐서를 저차원으로 압축해 KV 캐시에 저장하고, 추론 시 다시 원래 크기로 복원합니다.

실험 결과, MLA는 GQA보다 성능이 더 좋으면서도 메모리 효율이 뛰어납니다.

2.2. MoE: 거대한 파라미터, 효율적인 추론
MoE는 각 트랜스포머 블록의 FeedForward 모듈을 여러 개의 "전문가(Expert)"로 대체합니다.
하지만 모든 전문가를 매번 사용하는 것이 아니라, 라우터가 일부 전문가만 선택해 활성화합니다.

예를 들어, DeepSeek-V3는 256명의 전문가 중 9명(공유 전문가 1명 + 라우터가 선택한 8명)만 활성화합니다.
이렇게 하면 전체 파라미터는 671B(6,710억)이지만, 실제 추론 시에는 37B(370억)만 사용해 효율적입니다.
"공유 전문가는 모든 토큰에 항상 활성화되어, 반복되는 패턴을 여러 전문가가 중복 학습하지 않아도 되게 해줍니다."

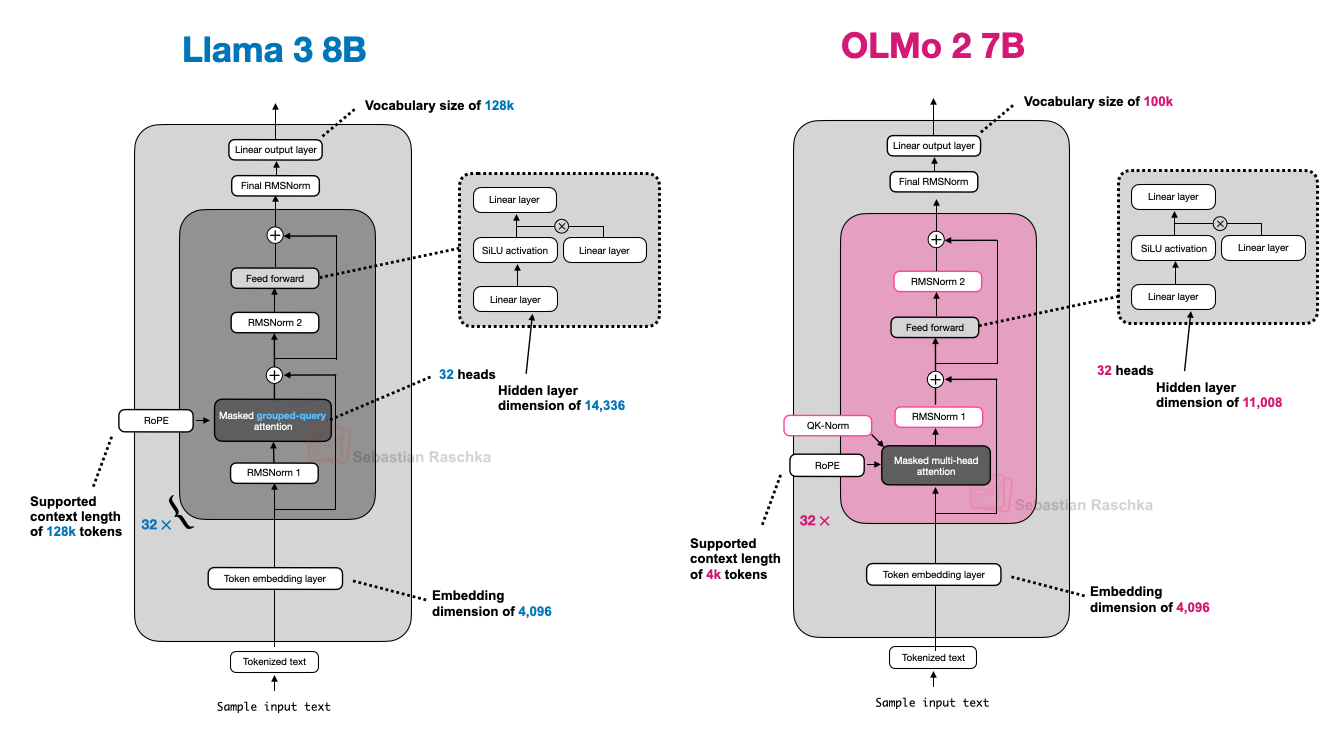
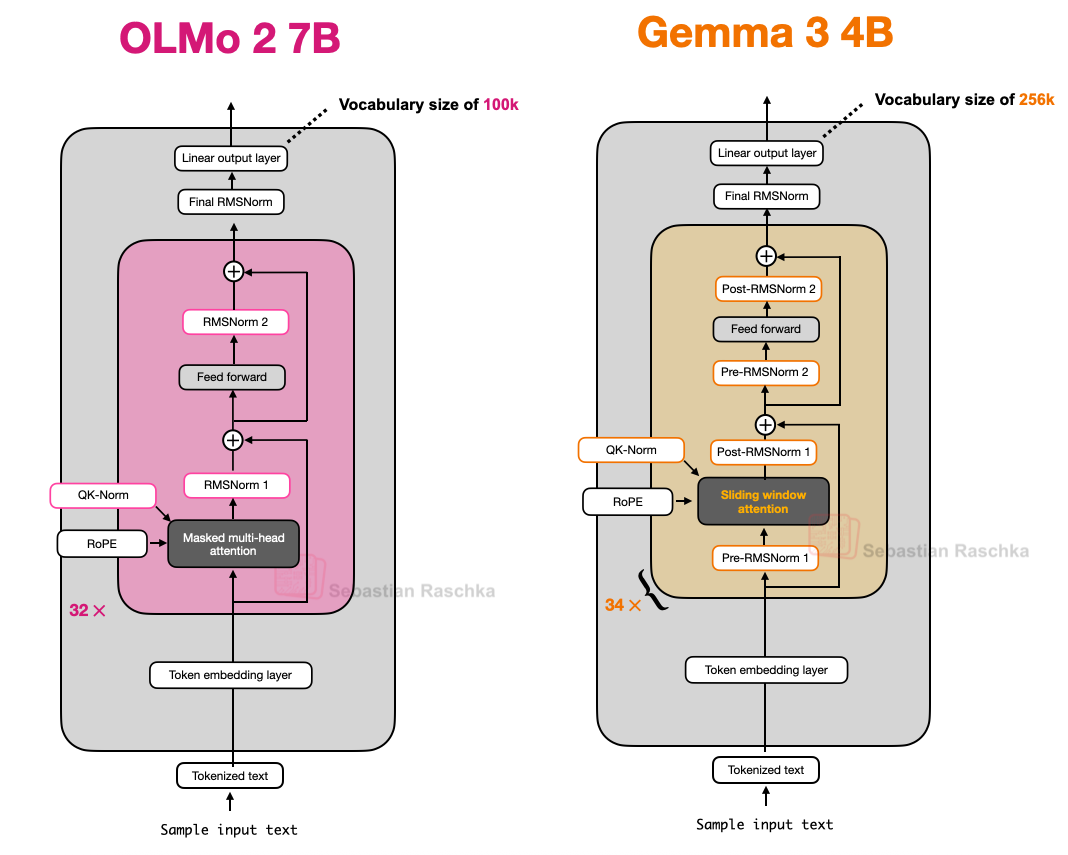
3. OLMo 2: 투명성과 안정성에 집중한 설계
OLMo 2는 AI2(Allen Institute for AI)에서 개발한 모델로, 학습 데이터와 코드, 기술 보고서가 투명하게 공개되어 있습니다.
성능은 최상위권은 아니지만, 아키텍처 설계의 청결함과 투명성이 큰 장점입니다.

3.1. RMSNorm과 QK-Norm: 안정적인 학습을 위한 정규화 전략
OLMo 2는 RMSNorm을 사용하며, 정규화 레이어의 위치를 기존과 다르게 배치합니다.
기존 GPT류는 Pre-Norm(정규화 → 어텐션/FFN), OLMo 2는 Post-Norm(어텐션/FFN → 정규화) 방식을 채택했습니다.

"정규화 레이어 위치를 바꾼 이유는 학습 안정성 때문입니다."
실제로, Post-Norm 방식이 학습 안정성을 높여줍니다.

또한, QK-Norm(쿼리/키 정규화)을 도입해 어텐션 내부에서도 RMSNorm을 적용, 추가적인 안정성을 확보했습니다.
4. Gemma 3 & 3n: 슬라이딩 윈도우 어텐션과 효율성의 진화
Gemma 3(구글)은 슬라이딩 윈도우 어텐션을 도입해 KV 캐시 메모리 사용량을 크게 줄였습니다.

4.1. 슬라이딩 윈도우 어텐션: 글로벌에서 로컬로
기존 어텐션은 모든 토큰이 서로를 참조(글로벌)하지만, 슬라이딩 윈도우 어텐션은 일정 범위(윈도우) 내에서만 참조(로컬)합니다.

Gemma 3는 5:1 비율로 슬라이딩 윈도우(로컬)와 글로벌 어텐션을 혼합, 윈도우 크기도 4096에서 1024로 줄였습니다.
실험 결과, 성능 저하 없이 메모리 효율을 극대화할 수 있었습니다.

4.2. 정규화 레이어의 독특한 배치
Gemma 3는 RMSNorm을 어텐션/FFN 앞뒤 모두에 배치(Pre-Norm + Post-Norm)해, 안정성과 효율을 동시에 추구합니다.
4.3. Gemma 3n: 모바일 최적화와 PLE
Gemma 3n은 Per-Layer Embedding(계층별 임베딩) 기법으로, 일부 파라미터만 GPU에 두고 나머지는 필요할 때 CPU/SSD에서 불러와 모바일 환경에서도 효율적으로 동작합니다.

5. Mistral Small 3.1: 빠른 추론을 위한 최적화
Mistral Small 3.1 24B는 Gemma 3 27B보다 빠르면서도 여러 벤치마크에서 더 나은 성능을 보입니다.
주요 비결은 커스텀 토크나이저, KV 캐시 및 레이어 수 축소 등으로 추론 지연을 최소화한 점입니다.

6. Llama 4: MoE의 대세화와 DeepSeek-V3와의 비교
Llama 4 역시 MoE 구조를 채택, DeepSeek-V3와 매우 유사한 아키텍처를 보입니다.
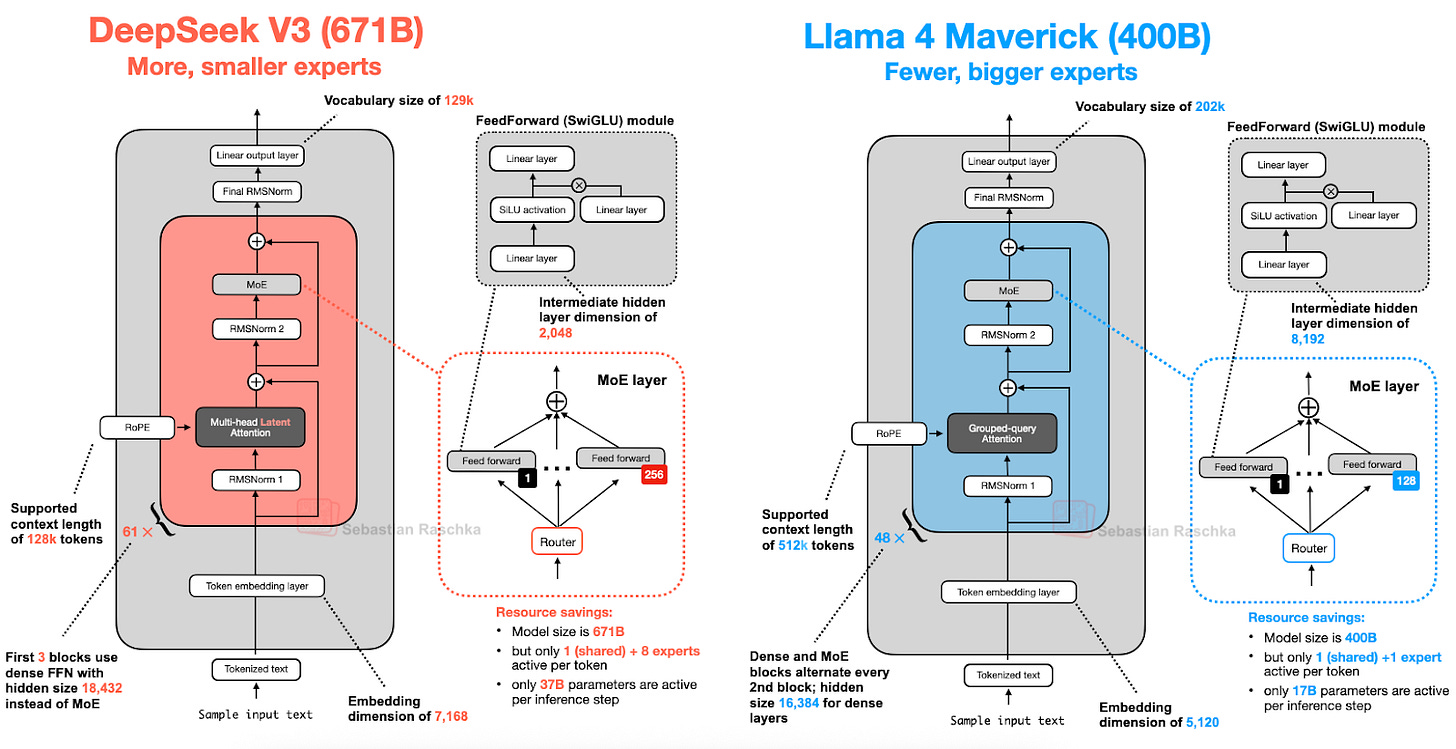
차이점은 Llama 4는 GQA를, DeepSeek-V3는 MLA를 사용한다는 점,
그리고 MoE의 전문가 수와 활성화 방식(DeepSeek-V3는 9명, Llama 4는 2명)이 다르다는 점입니다.
"2025년, MoE 구조는 대형 LLM의 대세가 되었습니다."
7. Qwen3: 초소형부터 초대형까지, 유연한 아키텍처
Qwen3는 0.6B~32B(밀집), 30B-A3B/235B-A22B(MoE) 등 다양한 크기로 출시되어,
로컬 실행/학습에 적합한 소형 모델부터 대규모 추론에 최적화된 MoE 모델까지 폭넓은 선택지를 제공합니다.

MoE 모델은 활성화 전문가 수(예: 22B)만큼만 파라미터를 사용해,
대용량 모델의 학습 능력과 추론 효율을 동시에 추구합니다.
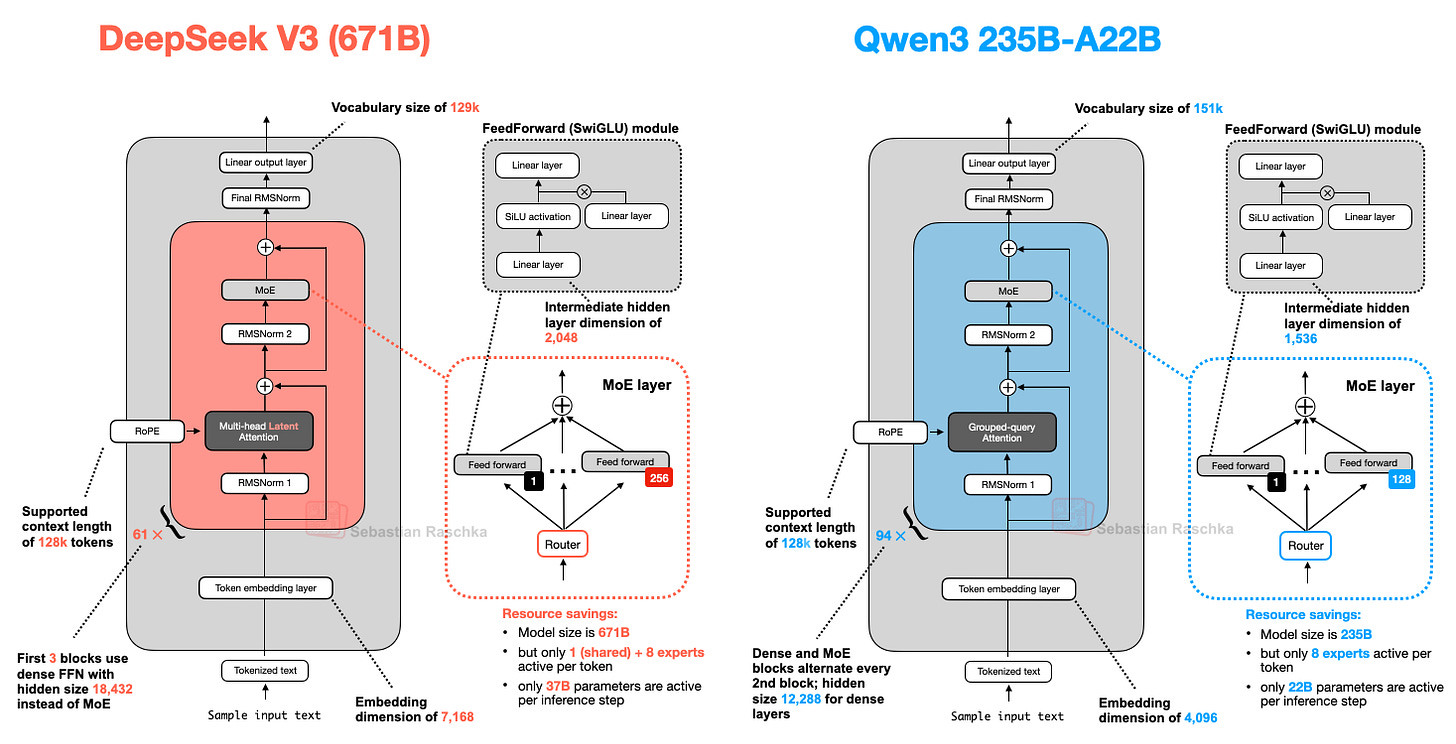
특이하게도 Qwen3는 공유 전문가를 사용하지 않는데,
개발자 Junyang Lin은 이렇게 답했습니다.
"그 당시 공유 전문가가 큰 개선을 주지 않았고, 추론 최적화에 대한 걱정도 있었습니다. 솔직히 명확한 답은 없습니다."
8. SmolLM3: NoPE로 포지셔널 임베딩을 없애다
SmolLM3(3B)는 Qwen3 1.7B/4B, Llama 3 3B, Gemma 3 4B와 경쟁하는 소형 모델입니다.

가장 흥미로운 점은 NoPE(No Positional Embeddings), 즉 포지셔널 임베딩을 아예 사용하지 않는 구조입니다.

기존에는 포지셔널 임베딩(예: RoPE)이 필수로 여겨졌지만,
NoPE 논문에 따르면 명시적 위치 정보 없이도 길이 일반화 성능이 더 좋을 수 있음이 밝혀졌습니다.

9. Kimi 2: 1조 파라미터, DeepSeek-V3의 확장판
Kimi 2는 1조(1T) 파라미터의 초대형 오픈 모델로,
DeepSeek-V3 아키텍처를 기반으로 더 많은 전문가와 더 적은 MLA 헤드를 사용합니다.

또한, Muon 옵티마이저를 대형 모델에 처음 적용해,
학습 손실 곡선이 매우 빠르고 안정적으로 감소했습니다.

마치며
2025년 현재, LLM 아키텍처는 기본 뼈대는 유지하면서도 효율성과 성능을 위한 다양한 실험이 활발히 이루어지고 있습니다.
MLA, GQA, MoE, 슬라이딩 윈도우 어텐션, NoPE, 정규화 레이어 배치 등
각 모델마다 자신만의 방식으로 메모리, 추론 속도, 학습 안정성, 확장성을 추구하고 있습니다.
"이렇게 오랜 시간이 흘렀지만, LLM의 발전은 여전히 흥미진진합니다. 앞으로 어떤 혁신이 나올지 기대됩니다!"