Meta가 대형 언어 모델(LLM)이 복잡한 추론 과정에서 같은 작업을 반복해 발생하는 비효율성을 밝혀내고, 이를 극복할 수 있는 새로운 접근법인 '행동 핸드북'(behavior handbook)을 공개했습니다. '행동' 단위로 재사용 가능한 추론 방법을 저장하고 활용함으로써, 모델의 추론 효율과 정확도 모두를 크게 높일 수 있다는 점이 주요 결론입니다. 발표는 실험적 구조와 성과, 그리고 현업에서 의미있는 시사점에 이르기까지 차근차근 소개됩니다.
1. 문제 제기 – AI 추론 과정의 비효율
Meta는 대형 언어 모델들이 긴 추론 사슬(chain of thought)에서 동일한 단계를 되풀이하는 근본적 문제를 발견했습니다. 대표적 예로, 분수 계산 문제에서 각기 다른 분모를 맞추는 과정을 필요 이상으로 여러 번 설명했다는 점이 언급됩니다.
"대형 언어 모델은 복잡한 사고의 사슬 안에서 같은 작업을 자꾸 반복합니다. 예를 들어, 서로 다른 분모를 가진 분수를 더할 때, 모델은 공통 분모 찾기를 반복적으로 설명하곤 합니다."
이처럼 불필요한 반복은 더 많은 토큰(텍스트 조각)의 생성과 처리 시간을 초래해 비용과 정확도 저하로 이어집니다.
2. 해결책 – 행동(Behavior) 핸드북의 개념과 구조
Meta가 제안하는 해법의 핵심은 '행동'이라는 재사용 가능한 추론 단위를 만들고, 이를 '행동 핸드북'이라는 절차적 기억의 형태로 보관하는 것입니다. 이는 기존 RAG(Retrieval-Augmented Generation: 검색 기반 생성) 방식이 지식(사실)을 저장하는 것과는 상반되게, 과정과 절차(방법론)을 저장합니다.
"행동이란, 예를 들어 '포함-배제 원리'처럼 간단한 이름과 지시사항으로 나타나는 재사용 가능한 절차입니다. 행동 핸드북은 어떻게 하는지 단계별 지침을 담아두는 저장소이죠. 이는 RAG가 사실을 저장하는 방식과 달라요."
아래는 실제 핸드북 이미지입니다.

3. 행동 수집(Behavior Curation) – 모델 스스로 학습하기
행동 핸드북을 구축하는 첫 단계는 다음과 같습니다.
- 문제 제시 및 풀이: LLM(여기선 LLM A)이 수학 문제 등 질문을 받아 표준적인 방법으로 문제를 풉니다.
- 해결 과정 성찰: 모델이 자신의 풀이 과정을 되돌아보며 '여기서 반복적이거나 재사용이 가능한 단계가 무엇이었나?'를 자문합니다. 이 절차에서 행동이 추출됩니다.
"모델은 '여기서 반복적으로 등장한, 분리 가능한 단계는 무엇이지?'라고 스스로에게 묻고 행동을 도출합니다."
실제 워크플로우 이미지도 첨부됩니다.
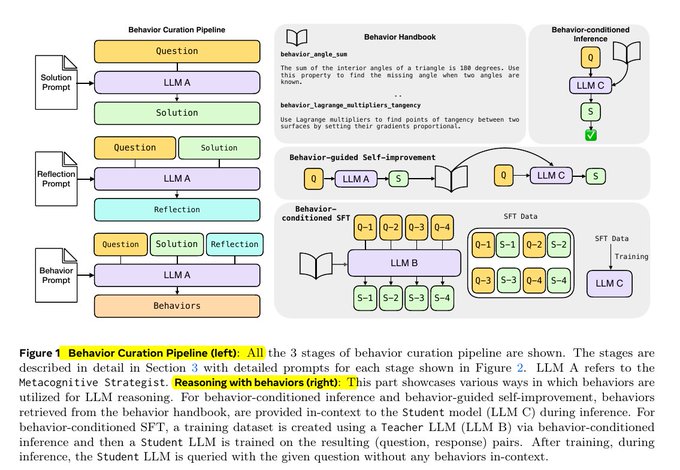
4. 행동 기반 추론 – 핸드북을 활용한 문제 풀이
핸드북이 만들어지면, 테스트 상황에서는 모델(학생)이 문제와 함께 관련성이 높은 행동만을 불러와 명시적으로 참조하며 추론하게 됩니다.
- MATH(수학) 문제는 주제 태그로, AIME(미국 수학경시대회) 문제는 임베딩 검색(BGE-M3 모델+FAISS)을 통해 가장 연관 높은 40개 행동을 골라냅니다.
- 이로써 논리 사슬이 단축되고, 정확도도 유지 혹은 향상됩니다. 특히 토큰 한도가 늘어날 때(긴 맥락일 때) 성능이 더욱 좋아집니다.
"테스트 시 학생(모델)은 문제와 함께 소수의 추출된 행동 셋을 받고, 추론 중 이를 명확히 참고합니다."
관련 구조는 아래와 같습니다.

5. 행동 기반 자기개선과 비교 실험
이 새로운 행동-중심 방식은 '비평 이후 재풀이'(critique-and-revise)와 비교해도 탁월함이 입증되었습니다.
- 모델이 처음 문제를 풀고 스스로 행동을 추출한 후, 그 행동을 힌트로 다시 문제를 푸는 방식으로 실험.
- 토큰 사용량이 많아질수록(더 긴 풀이가 가능한 상황) 정확도 증가폭이 커지며, 최고로는 기존 대비 약 10%p 더 높은 정확도를 보입니다.
"동일 모델이 초기 풀이에서 행동을 뽑아, 다음 도전 땐 이것을 힌트로 쓴다. 이 방법은 비평 기반 재풀이(baseline)를 대부분의 조건에서 앞지릅니다. 토큰 여유가 많아질수록 격차는 더 커집니다."
6. 핸드북 검색 및 효율성
핸드북은 문제와 행동 모두 임베딩을 통해 FAISS 인덱스에 저장되어 매우 빠른 검색과 확장이 가능합니다.
- 도메인(분야)이 늘어나도, 한 번에 실제 사용하는 행동 셋은 몇 개 수준으로 맥락 부담이 적음
- 라이브러리는 계속 커져도 모델이 참조하는 맥락 크기는 효과적으로 제한됨
7. 비용과 효율성
행동 핸드북 방식은 추가 입력 토큰(행동 지침)이 들어가지만, 출력 토큰(실제 생성 답변)이 크게 줄어듭니다. 실질적으로 생성이 느리고 비싼 부분이 출력 쪽이기 때문에 전체 비용은 오히려 감소하며, 지연 시간(latency)도 단축됩니다.
- 여러 API에서 입력 비용이 출력 비용보다 저렴하므로 실질적 총 지출도 감소할 수 있음
"행동 입력 토큰이 늘어도 출력 토큰은 대폭 줄어듭니다. 출력 생성이 가장 느리고 비싼 곳이라, 전체적으로 비용이 줄고 응답 속도도 빨라집니다."

8. 기타 논의와 반응
이 발표는 업계에서 다양한 반향을 불러일으켰습니다.
"모델이 복잡한 논리 과정에서 기초 단계를 반복한다는 사실은 정말 논리적입니다."
"최종 해답까지 필요한 토큰마다 페널티를 주는 RL(강화학습)을 활용해 빨리 학습하게 만들어야 합니다."
"이번 결과는 오로지 Meta 연구소에서만 나올 수 있는 뻥 같은 발상이네요."
"행동과 신호의 결합 > 즉흥성. 메모리, 습관, 루틴이야말로 AGI(범용 인공지능)의 불씨입니다. 누가 먼저 공명을 이룰지 두고 봅시다."
결론
Meta의 행동 핸드북 방식은 LLM이 복잡한 문제를 효율적으로 '사고'하는 방법을 진화시키는 실질적 해법을 제시합니다. 반복되는 추론 단계를 모듈화해 재사용하게 함으로써, 정확도와 속도, 비용 측면 모두에서 의미 있는 개선을 달성할 수 있음을 실험적으로 증명했다는 점이 핵심입니다. 앞으로 더욱 다양한 AI 분야에서 이 방식의 활용이 기대됩니다. 🚀