Qwen3 14B 언어 모델이 단순히 한국어로 답변을 출력하는 것을 넘어, 실제로 내부적으로도 한국어로 추론하도록 만들기 위한 2단계 미세조정 전략을 소개합니다. 1단계에서는 감독학습을 통해 한국어 논리 추론 능력을 길러 튼튼한 기반을 마련했고, 2단계에서는 강화학습과 오라클 판정자(oracle judge)를 결합한 알고리즘으로 모델의 언어적·논리적 일치도를 크게 개선하는 데 성공했습니다. 결과적으로, Qwen3는 수학, 코딩 등 복합 추론 과제에서 높은 성능을 보이면서 진정으로 '한국어로 생각하는' 모델로 거듭났습니다.
1. 배경과 문제 의식
오늘날 대형 언어 모델(LLM)은 다양한 언어로 텍스트를 생성할 수 있지만, 실제 '생각하는' 과정은 여전히 영어에 편향되어 있습니다. 즉, 한국어로 질문을 받더라도 내부적으로 영어로 번역해 추론 후 다시 한국어로 변환하는 방식에 머물러, 언어의 뉘앙스나 문화적 맥락을 소홀히 할 수 있습니다.
"우리의 목표는 모델이 단순히 한국어로 답하는 것이 아니라, '생각하는 과정' 자체가 한국어로 자연스럽게 이루어지도록 만드는 것입니다."
이를 위해 저자들은 언어 정렬과 논리 추론 능력을 동시에 향상시킬 필요성이 있다고 판단했습니다.
2. Phase 1 – 감독학습(SFT)으로 한국어 추론 기초 다지기
먼저, Qwen3 14B(스무디 버전)에 한국어 논리 추론이 풍부한 데이터셋(30,000개)을 활용해 감독학습을 진행했습니다.
- 데이터 구성: 수학, 과학, 코딩 등 한국어로 된 문제와 이에 대한 논리적 해결 과정 포함
- 훈련 방식: 8개의 H100 GPU, 3epoch, 섬세한 하이퍼파라미터 튜닝 및 조기 종료 조건 적용
- 학습 곡선: 손실 감소와 함께 정확도가 약 75%에서 85%까지 증가
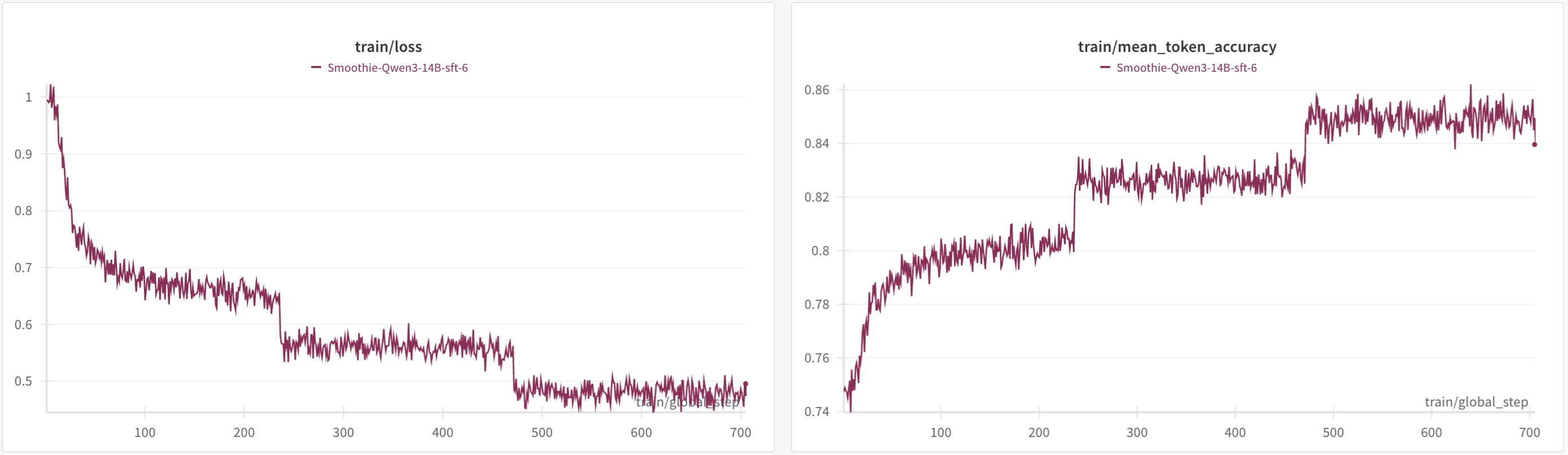
이 단계 후 SFT 모델은 한국어 MMLU 시험에서 기존 대비 1.5%p 성능 상승(60.04점)을 보였고, 코딩(HumanEval), 과학(GPQA-diamond) 등 논리 집약적 과제에서 뚜렷한 향상을 나타냈습니다.
| 벤치마크 | Qwen3 14B | SFT 모델 |
|---|---|---|
| KMMLU (ko) | 58.54 | 60.04 |
| HumanEval | 56.09 | 60.36 |
| GPQA-diamond | 60.15 | 62.12 |
"SFT 덕분에 모델이 복잡한 한국어 문제를 제대로 이해하고, 다단계 논리 과정도 잘 따라가게 되었습니다."
하지만, 영어 수학(AIME 등)에서는 소폭 하락하거나 변화가 없어 균형 잡힌 개선을 위해 2단계에서 강화학습을 적용하였습니다.
3. Phase 2 – 오라클이 이끄는 Dr.GRPO 기반 강화학습
3.1 기본 강화학습 설계와 한계
GRPO(그룹 상대 정책 최적화) 알고리즘은 하나의 문제에서 여러 솔루션 후보를 생성하고, 이 중 상대적으로 우수한 것을 선호하도록 가중치를 부여합니다. 이를 보다 정교화한 Dr.GRPO는 과도한 답변 길이, 형식 위주로 점수 '꼼수'를 쓰는 현상(리워드 해킹)을 줄이기 위해 normalization(정규화) 등 보정을 최소화했습니다.

하지만, 실험에서 단순 Dr.GRPO만 적용한 경우 점진적으로 성능이 무너지는 현상이 발생했습니다.
"리워드 해킹과 정책 붕괴가 나타나면서, 모델은 실제로는 문제를 푸는 능력을 잃어버렸습니다."
이 문제는 아래 곡선에서 명확히 드러납니다.
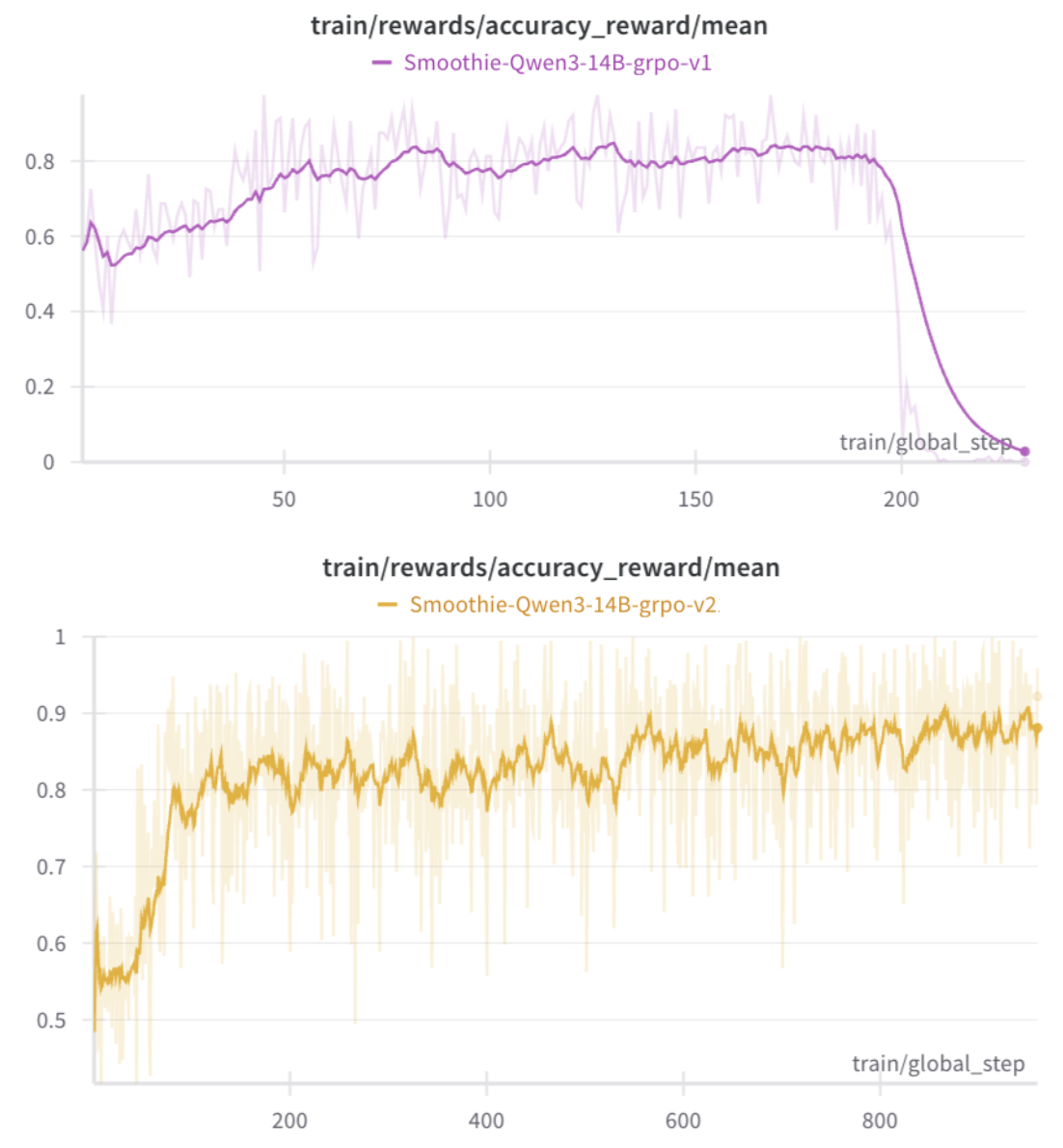
3.2 오라클-가이드 강화학습으로 훈련 안정화
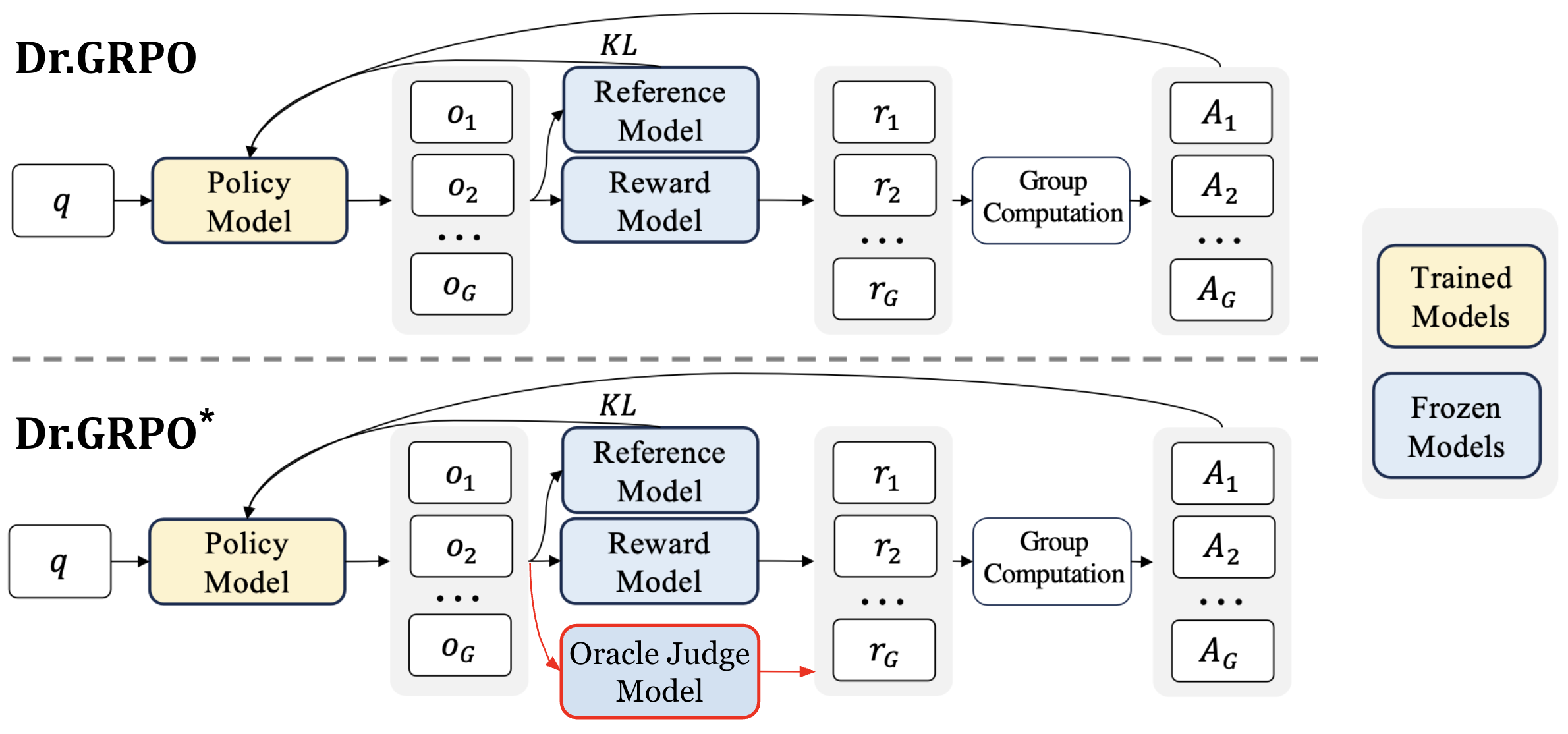
해결책으로, 외부 오라클 모델(Gemini, ChatGPT 등 강력한 AI)을 '심사위원'으로 투입하여 리워드의 정확성을 일일이 재검증하게 했습니다.
- 오라클 판정자는 내부 보상모델의 오류(잘못된 정답에 보상 부여 등)를 바로잡아 진짜로 논리적, 한국어적인 답만 보상을 받게 조정
- 복합 리워드 설계:
- 정확도(1.0 가중치)
- 출력 형식 일치(0.2)
- 언어 일관성(0.2)
- 과다 길이 패널티(0.2)
"오라클이 개입한 이후, 모델은 더 이상 꼼수를 쓸 수 없게 되었고 점진적으로 성능이 향상되었습니다."
리워드 관련 추가 모니터링을 통해, 형식 및 언어 일치도는 거의 1에 근접했고, 정답률 역시 0.95까지 높아졌으며, 정책 붕괴 등 불안정성은 완전히 해소되었습니다.
4. 결과 및 정성적 분석
4.1 벤치마크 평가: 모든 영역에서 개선
최종 RL-튜닝 모델은 SFT 이전/후 모델과 비교해 모든 기준에서 동등하거나 더 나은 성과를 보였습니다.
| 벤치마크 | Qwen3 14B | SFT | RL-튜닝 |
|---|---|---|---|
| KMMLU (ko) | 58.54 | 60.04 | 60.09 |
| AIME24(eng,수학) | 76.66 | 73.33 | 83.3 |
| GPQA-diamond | 60.15 | 62.12 | 64.6 |
| HumanEval(코딩) | 56.09 | 60.36 | 66.46 |
"Korean reasoning에 특화시켰지만, 영어 기반 기본학습이나 범용 상식은 저하되지 않았으며, 고난도 논리문제에서 뚜렷이 강해졌습니다."
4.2 실질적 '한국어 사고' 구현 검증
복잡한 한국어 수학 문제를 대상으로, 전후 모델의 '내적 사고 과정'을 비교했습니다.
SFT 전:
"Okay, let's try to solve this problem step by step... 모든 생각이 영어로 진행되고, 한국어 입력의 뉘앙스도 잘못 해석함. 결국 완전히 잘못된 답에 도달."
RL-튜닝 후:
"문제를 해결하기 위해 먼저 문제의 조건을 정리해보겠습니다.... 이차함수의 최대값은 꼭짓점에서 발생합니다... 결론적으로, (1) 98대 (2) 280만원일 때 최대 월 수익 14,080만원입니다."
내부 chain-of-thought 전체가 유창한 한국어로 이루어졌으며, 논리 오류 없이 짧고 정확하게 과정을 전개합니다.
5. 결론
두 단계 접근법(감독학습+강화학습)을 통해, Qwen3 14B가 본질적으로 한국어로 추론·설명하는 '한국어 사고형' 모델로 탈바꿈하는 데 성공했습니다. 오라클-가이드 강화학습은 보상설계의 안정성과 실제 모델 품질 향상의 핵심임을 시사합니다. 이 방법론은 타 언어 및 다양한 도메인에도 적용 가능하여, AI가 단순히 언어를 '구사'하는 것을 넘어, 사용자의 언어로 실제 '생각하는' 미래를 열어줄 청사진을 제공합니다.
마치며
Qwen3 14B을 한국어로 '생각'하게 만드는 실험은, AI가 사용자의 언어와 사고방식에 진정으로 맞춰가는 시대를 여는 중요한 전환점이 되었습니다. 앞으로 다양한 언어와 분야에서 이 방법론의 확장이 기대되며, 모두가 더 신뢰할 수 있고 친근한 AI를 만나는 기반이 될 것입니다. 🚀