구글 클라우드가 Vertex AI Agent Engine의 신규 관리형 서비스인 Memory Bank(메모리 뱅크)의 공개 프리뷰를 발표했습니다. 이 메모리 뱅크는 AI 에이전트가 자연스럽고 개인화된 대화를 지속할 수 있게 핵심 '장기 기억' 기능을 제공합니다. 본문에서는 기존 메모리 문제, Memory Bank의 구체적인 동작 방식, 활용법과 개발자 리소스를 모두 시간 순서에 따라 쉽게 정리합니다.
1. AI 에이전트의 치명적 한계: '기억상실'
AI 에이전트가 활성화되면서 개발자들은 더 똑똑하고 개인화된 에이전트를 만들기 위해 분주하게 움직이고 있습니다. 하지만 실제 현장에서는 "메모리의 부재" 라는 근본적인 제한에 부딪히곤 합니다. 에이전트는 매번 새로운 대화로 인식해 반복 질문을 하거나 유저의 선호, 과거 정보를 기억하지 못하는 경우가 많죠.
"에이전트가 각각의 상호작용을 매번 처음인 것처럼 다루어요. 반복적으로 같은 질문을 하고, 사용자의 취향을 기억하지 못하니, 맞춤형 지원이 어렵죠."
이처럼 맥락 인식 능력이 없는 에이전트는 대화를 개인화하지 못해, 사용자와 개발자 모두에게 답답함을 안겨줍니다.
2. 기존의 임시 해결법과 그 한계
이런 메모리 문제를 해결하기 위해, 지금까지는 LLM(대형 언어 모델)의 "문맥 창(context window)"을 활용했습니다. 즉, 이전 대화 내용을 전부 LLM에게 같이 제공하는 방식이었죠.
하지만 이 방법의 단점은 명확합니다.
-
비용 증가와 느린 응답
자료를 전부 맥락 창에 넣으면 연산량이 급격히 늘어나 inference 비용이 오르고, 처리 속도도 느려집니다. -
품질 저하
문맥 창에 쓸데없는 정보가 쌓이면 모델의 응답 정확도가 떨어집니다. 특히 "중간 내용이 소실(lost in the middle)"이나 "문맥의 부패(context rot)" 문제가 나타나죠.
"문맥 창에 대화 전체를 넣는 건 비싸고 비효율적입니다. 입력량이 늘어날수록 오히려 응답 품질도 떨어집니다."
3. Vertex AI Memory Bank로 '진짜 기억'을 심다
이제 구글은 이런 한계를 극복할 'Memory Bank(메모리 뱅크)'의 공개 프리뷰를 발표했습니다. 이 서비스는 엔진에 자연스럽고 지속적인 대화 능력, 진짜 기억을 더해줍니다.
Memory Bank가 가져오는 4가지 혁신은 다음과 같습니다.
- 개인별 맞춤화
사용자 선호, 과거 선택, 주요 이벤트 등 시간을 넘어 개인에 꼭 맞는 추천을 할 수 있습니다. - 대화 연속성 보장
시간이 지나도, 다른 세션에서도 끊어진 곳 없이 자연스럽게 대화를 이어나갈 수 있습니다. - 더 나은 맥락 제공
사용자 배경 정보까지 파악하여 더 깊고 유익한 대화를 지원합니다. - 경험 개선
사용자는 같은 말을 반복할 필요 없이 자연스럽고 효율적으로 에이전트와 소통할 수 있습니다.
"사용자에게 '내가 선호하는 온도는 71도, 비행기에서는 통로 좌석이 좋아요' 같은 정보를 한 번만 말하면, 에이전트가 계속 기억합니다!"
Memory Bank는 Agent Development Kit(ADK) 및 Agent Engine Sessions과 통합되어 있습니다. 이제 대화 히스토리를 개별 세션별로 저장·관리하고, 메모리 뱅크를 통해 장기 기억을 추가로 관리할 수 있습니다.
또한 LangGraph, CrewAI 등 타 프레임워크에서도 사용할 수 있습니다.
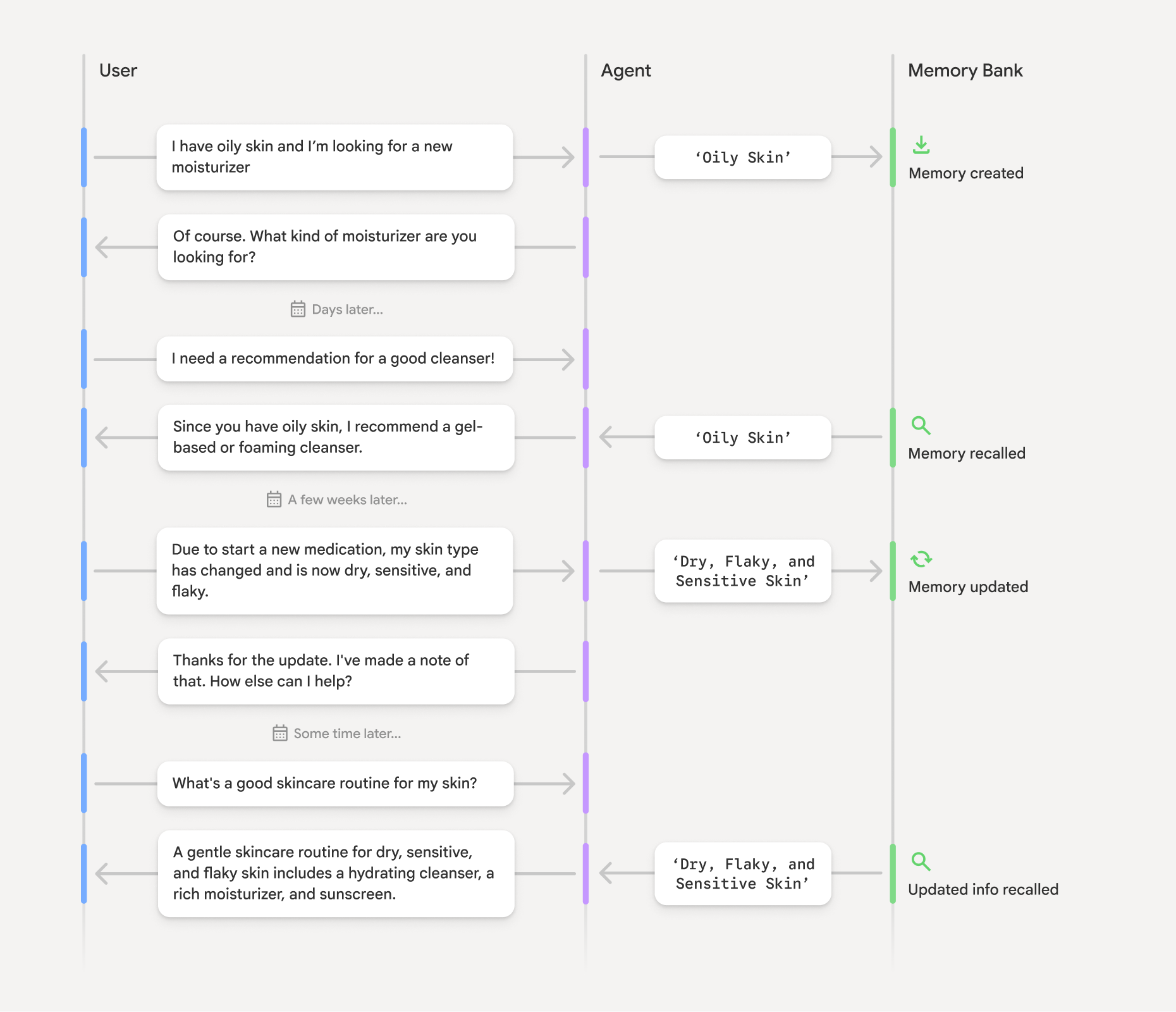
4. Memory Bank의 동작 원리: 어떻게 기억을 관리하나?
Memory Bank는 아래 세 단계로 작동합니다.
-
대화로부터 기억 추출
에이전트와 사용자의 대화 히스토리(Agent Engine Sessions)를 Gemini 모델이 분석, 중요 사실이나 선호, 맥락 정보를 자동으로 "새로운 기억" 형태로 정제합니다. 이 과정은 별도 복잡한 파이프라인 없이 비동기적으로, 자동 진행됩니다. -
지능적 저장 및 업데이트
추출된 핵심 정보(예: '내 피부타입은 복합성', '최근 구매 제품' 등)는 사용자 ID 별로 구조화되어 보관됩니다. 새 정보가 생기면, 기존 기억과 통합·업데이트하여 모순도 자동 정리합니다. -
상황 맞춤형 기억 불러오기
사용자가 신규 대화를 시작하면, 에이전트는 관련 기억을 즉시 불러올 수 있습니다. 필요하다면 단순 조회뿐 아니라 Embedding 검색으로 "지금 이 상황에 꼭 맞는 기억만 뽑아서" 응답에 활용하게 됩니다.

이 모든 과정은 구글의 최신 연구(ACL 2025 채택)에 기반을 두고, 에이전트가 주제 기반 기억을 지능적으로 학습 및 회수하도록 설계되어 있습니다.
"에이전트가 사용자와의 과거 대화에서 피부 타입이 변했다는 걸 기억하고, 변화에 맞게 스킨케어를 추천해줍니다. 이게 바로 장기 기억의 힘이에요!"
5. 개발자가 Memory Bank 시작하는 방법
Memory Bank를 에이전트에 적용하는 방법은 다음 두 가지입니다.
-
Google ADK로 에이전트 개발
가장 손쉽게 Memory Bank를 연동할 수 있습니다. -
Memory Bank API 호출 기반 에이전트 구축
다른 프레임워크(LangGraph, CrewAI 등)에서도 쉽게 API를 연동할 수 있습니다.
관련 공식 유저 가이드 및 개발자 블로그에서 자세한 예시와 통합법을 확인하세요.
아래는 바로 활용 가능한 개발 예제 노트북입니다.
ADK를 사용하지만 구글 클라우드를 처음 쓰는 개발자에게는 express mode로 간편 신청이 가능합니다.
- Gmail 계정으로 API 키 신청
- 키로 Agent Engine Sessions 및 Memory Bank에 접근
- 무료 사용량 내에서 개발·테스트
- 프로덕션 단계에서 구글 클라우드 전체 프로젝트로 확장 전환
더 궁금하다면 Vertex AI 구글 클라우드 커뮤니티에 가입해 질문·경험을 공유할 수 있습니다.
마치며
Vertex AI의 Memory Bank는 그동안 AI 에이전트 개발의 마지막 퍼즐이었던 '장기 기억' 문제를 실용적으로 해결합니다. 이제 에이전트가 개인을 진짜로 기억하며 대화의 연속성과 맥락을 살린 자연스러운 경험을 선사할 수 있는 시대가 열렸습니다.
"반복된 설명과 답답함 없이, 내 취향과 과거를 기억하는 AI와 대화해보세요!"
궁금하다면 공식 가이드와 샘플로 직접 경험해보세요! 🚀