이 글에서는 Lyft의 데이터 과학팀이 겪고 있는 시장 관리 문제를 해결하기 위한 인과 예측 시스템의 첫 번째 부분으로, 비즈니스 문제, 기본 원칙, 그리고 모델링 기법에 대해 설명합니다. 이 시스템은 라이더 쿠폰, 드라이버 보너스, 가격 책정 등 다양한 시장 관리 제품의 하위 결과를 정확하게 예측하여 효율적인 의사 결정을 돕습니다. 특히, 단순히 상관관계를 분석하는 것을 넘어 인과 관계를 파악하여 미래 지향적인 스마트한 의사 결정을 내리는 데 중점을 둡니다.
1. Lyft의 시장 관리와 당면 과제 🚴♀️
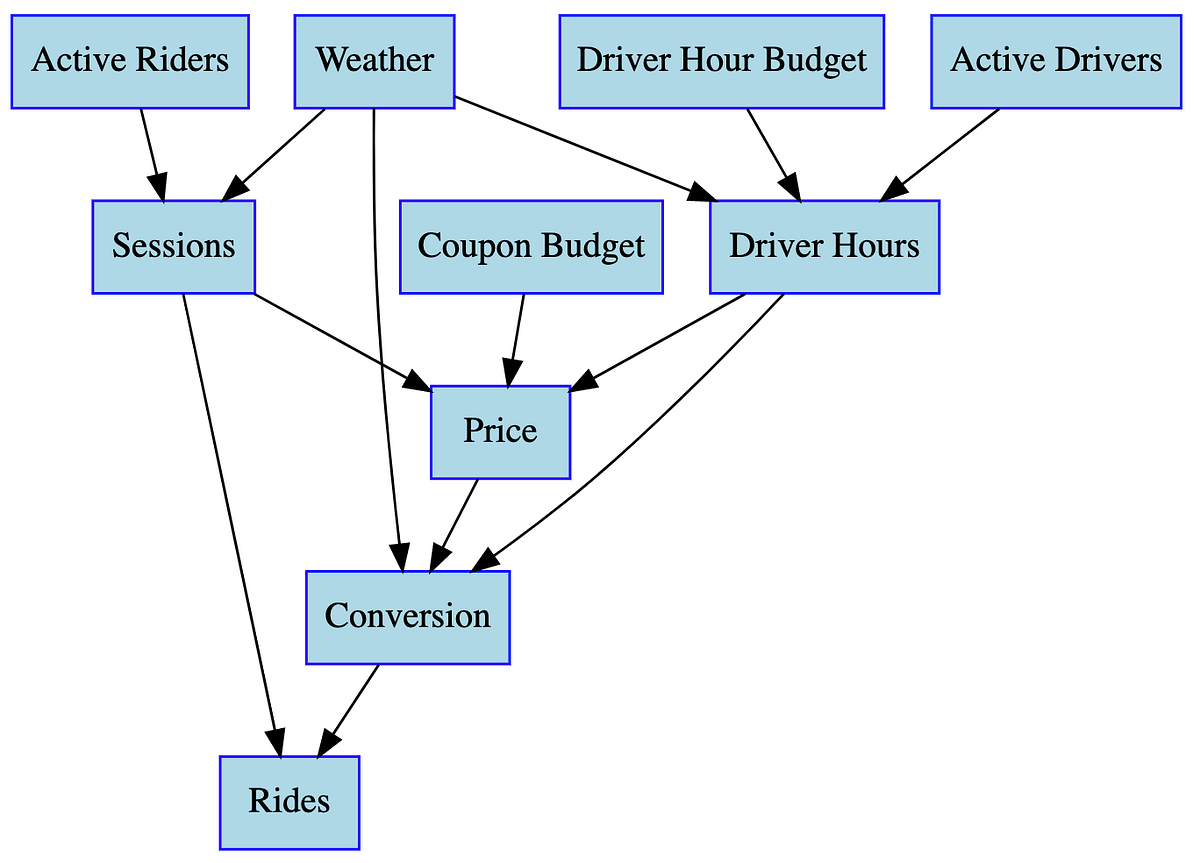
Lyft의 데이터 과학팀은 변화하는 시장 상황 속에서 드라이버에게 합리적인 인센티브를 제공하고, 라이더에게는 저렴한 요금과 짧은 예상 대기 시간(ETA)을 제공함으로써 시장을 효율적으로 관리하는 것을 핵심 목표로 삼고 있어요. 이를 위해 라이더 쿠폰, 드라이버 보너스, 가격 책정 등 다양한 시장 관리 도구를 사용하고 있죠. 이러한 도구들을 효과적으로 활용하려면 앱 접속 횟수부터 재무 지표에 이르기까지, 각 결정이 어떤 하위 결과를 가져올지 깊이 이해하는 것이 중요해요.
하지만 문제는 단순히 상관관계만으로는 부족하다는 점이에요. 과거의 결정들이 데이터에 복합적으로 얽혀 있기 때문에, 순수한 상관관계 모델만으로는 정확한 예측을 할 수 없어요. 마치 "닭이 먼저냐, 달걀이 먼저냐"처럼, 무엇이 원인이고 무엇이 결과인지 정확히 파악해야만 올바른 결정을 내릴 수 있죠. 그래서 Lyft는 인과 관계를 밝혀내는 것을 목표로 삼았고, 이를 위해 Lyft의 인과 예측 시스템이라는 내부 제품을 개발했습니다. 이 글에서는 이 시스템의 핵심적인 아이디어와 모델링 기법을 다루고, 다음 글에서는 이를 실제 서비스에 적용하기 위한 소프트웨어에 대해 설명할 예정이에요.
2. 예측 및 최적화 목표 🎯
Lyft는 제품 중심의 팀으로 조직되어 있어요. 예를 들어, 라이더 쿠폰 팀은 쿠폰을 통해 비용 효율적으로 라이더 수를 늘리고 총 탑승 횟수를 증가시키는 데 집중하죠. 각 팀은 주로 자신들의 제품과 직접적으로 관련된 지표에 초점을 맞추지만, 이 모든 팀의 활동은 핵심 비즈니스 지표(V)와 제어 가능한 정책 변수(C)라는 두 가지 중요한 변수로 요약될 수 있어요.
가령, V₁과 V₂는 각각 탑승 횟수와 수익이 될 수 있고, C₁은 요율 카드(Rate Card, 라이더가 분당/마일당 지불하는 요금)가 될 수 있죠. Lyft의 궁극적인 목표는 크게 두 가지예요:
- 정책 변수가 주어졌을 때, 핵심 비즈니스 지표들을 정확하게 예측하는 모델을 만드는 것.
- 이 모델을 바탕으로, 예측된 변수들을 최적화할 수 있는 정책 값을 결정하는 것.
이 두 가지 목표를 달성함으로써 Lyft는 조직 전반에 걸쳐 지능적인 의사 결정을 내릴 수 있게 됩니다. 하지만 이를 위해서는 단순한 상관관계 예측을 넘어서는 상당한 기술적 도전 과제가 따르죠.
3. 인과 모델링의 핵심 원리 🧠
Lyft의 접근 방식은 인과 모델에 크게 기반을 두고 있어요. 인과 모델은 모든 변수가 다른 변수의 영향을 받는다고 가정하고, 이를 통해 특정 변수를 예측할 수 있다고 보는 것이죠. 이러한 관계는 방향성 비순환 그래프(DAG, Directed Acyclic Graph)라는 형태로 표현될 수 있습니다.
DAG에서는 각 변수가 '노드'가 되고, 한 변수가 다른 변수의 '원인'이 되면 원인 변수에서 결과 변수로 '방향성 에지'가 연결돼요. 예를 들어, 평균 가격이 전환율에 영향을 미친다고 가정하면, 다음과 같은 DAG로 표현할 수 있습니다.
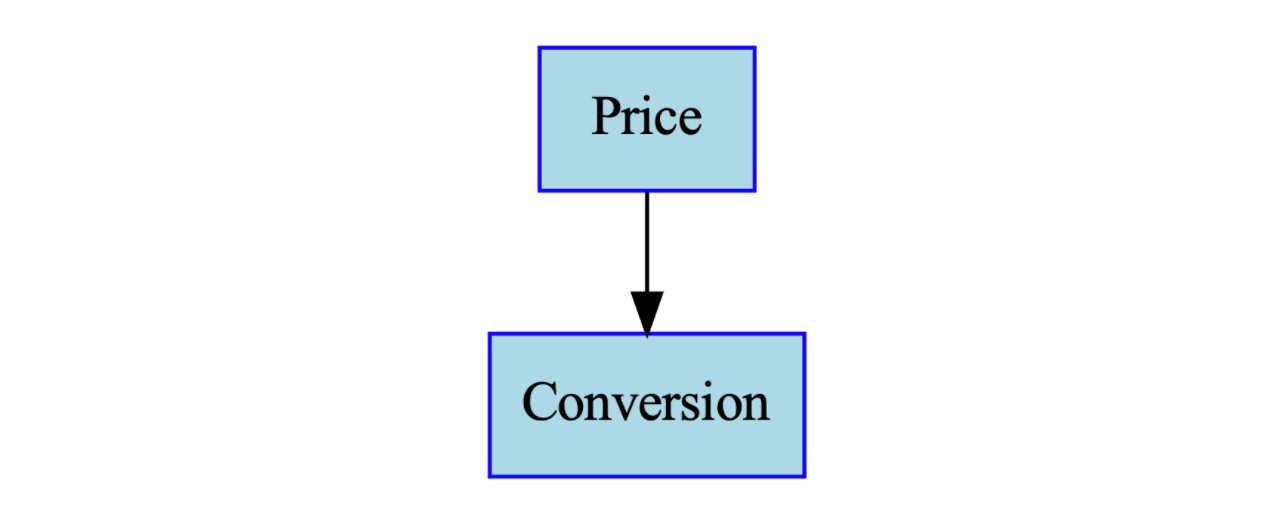
"전환율은 가격에 의해 발생하며, 다른 요인에 의해서는 발생하지 않는다"는 가정을 이 그래프에 담는 것이죠. 나아가, 탑승 횟수가 세션과 전환율의 곱으로 생성된다고 가정하면, 이 관계 또한 DAG로 표현될 수 있습니다.
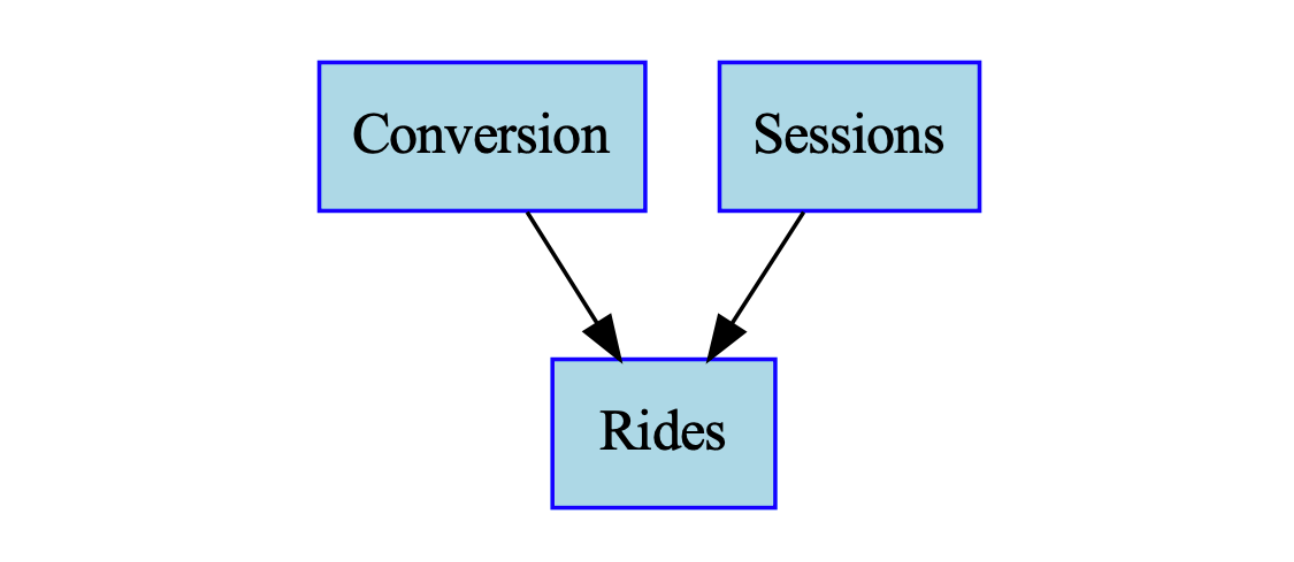
이렇게 각각의 DAG를 결합하면 전체 비즈니스 변수들 간의 관계를 보여주는 더 큰 DAG를 만들 수 있어요.

이러한 DAG는 분할 정복 모델링 전략을 가능하게 해요. 즉, 복잡한 문제를 작은 모델링 작업으로 분해할 수 있다는 뜻이죠. 각 데이터 과학자들은 독립적으로 모델을 개발하고, 이들을 결합하여 비즈니스에 대한 합의된 관점을 담은 큰 그래프를 생성할 수 있게 됩니다. Lyft는 이러한 연결을 평가하기 위해 실험을 활용하고, 이를 통해 정책 결정과 결과 사이의 함수적 관계를 파악합니다. 🧪
4. 드라이버 인센티브 사례 분석 🚗
드라이버 인센티브가 드라이버 근무 시간에 미치는 영향을 예시로 들어볼까요?
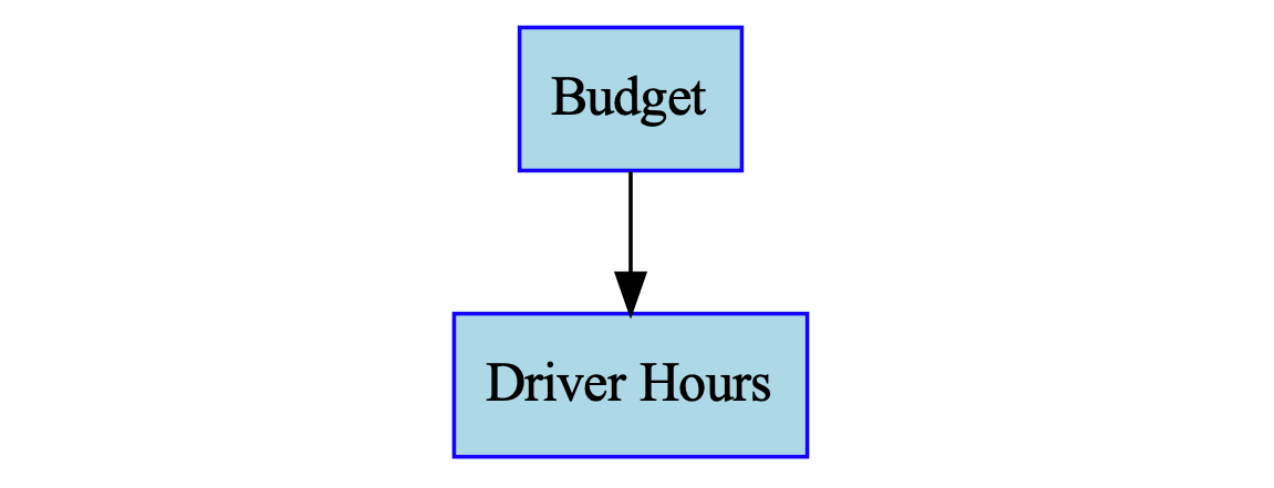
만약 드라이버 인센티브 예산과 드라이버 근무 시간의 가상 데이터를 시계열과 산점도로 나타내면 다음과 같아요.
이 산점도만 보면 음의 상관관계가 있는 것처럼 보이죠? 즉, 예산이 늘면 근무 시간이 줄어드는 것처럼요. 이런 상관관계만을 기반으로 모델을 만들면 다음과 같은 예측이 나올 수 있습니다.
문제는 이 모델이 예측하는 예산과 드라이버 근무 시간 사이의 미분 관계예요. 특정 날짜에 예산을 변경했을 때, 드라이버 근무 시간의 변화(증분 근무 시간)를 보면 특정 예산 이상에서는 예산을 줄여야 드라이버 근무 시간이 늘어난다는 황당한 결론에 도달합니다.
"예산을 60K 이상으로 늘리면 드라이버 근무 시간이 줄어든다고? 이건 말도 안 돼!" 😱 이런 모델은 실제 계획 수립에 전혀 사용할 수 없겠죠.
이러한 문제를 해결하기 위해 Lyft는 실험적으로 결정된 "비용 곡선"을 활용해요. 드라이버 보너스 팀에서 제공하는 이 비용 곡선은 예산 변화에 따른 드라이버 근무 시간의 실제적인 변화를 보여줍니다.
이 비용 곡선을 모델에 반영하면, 예측 정확도를 유지하면서도 드라이버 보너스 팀의 믿음과 일치하는, 즉 인과적으로 올바른 예측을 할 수 있는 모델을 개발할 수 있어요.
이제 이 모델은 정확하게 예측할 뿐만 아니라, 드라이버 보너스 팀이 예산 변화에 따라 어떤 일이 일어날 것이라고 믿는지를 반영하므로 의사 결정에 활용할 수 있게 되었어요. 이처럼 인과적 가정을 DAG로 인코딩하고, 경험적(이상적으로는 실험적) 관계를 가져와서 역사적 데이터를 잘 설명하면서도 인과적 관계를 따르는 모델을 개발하는 것이 핵심 원칙입니다.
5. 모델 결합 및 비즈니스 이해 🤝
앞서 설명한 원칙은 반복적으로 적용될 수 있어요. 즉, 인과적 가정을 DAG로 표현하고, 경험적(실험적) 관계를 모델에 통합하여 역사적 데이터에 잘 맞는 모델을 개발하는 것이죠. 우리가 관찰하는 데이터는 모델을 학습시키는 데 사용되지만, 실험은 우리의 결정이 결과에 어떻게 영향을 미치는지 알려주는 중요한 단서가 됩니다. 📊
이렇게 개발된 다양한 모델들을 서로 연결하면, Lyft 비즈니스의 전체적인 기능을 보여주는 포괄적인 모델을 만들 수 있어요.
이 DAG를 통해 우리는 비즈니스의 작동 방식을 한눈에 파악할 수 있죠. 더 중요한 것은, 우리의 가정이 정확하고 인과 관계가 올바르며 모델이 예측력이 있다면, 이 모델 컬렉션은 앞서 언급한 첫 번째 목표(예측)를 달성한다는 점입니다. 이 모델에서 우리의 제어 변수는 입력이 되고, 그로부터 파생되는 모든 것들이 출력이 되는 거죠.
6. 계획 수립 및 최적화 📈
우리의 초기 목표인 의사 결정으로 돌아가 보면, 이 인과 모델을 활용하여 우리의 결정에 따른 조건부 예측을 할 수 있습니다. 이를 우리는 '계획(plan)'이라고 부르죠. 이 계획을 통해 의사 결정자들은 균형 성장 전략과 공격적 성장 전략 사이의 상충 관계를 평가할 수 있어요.
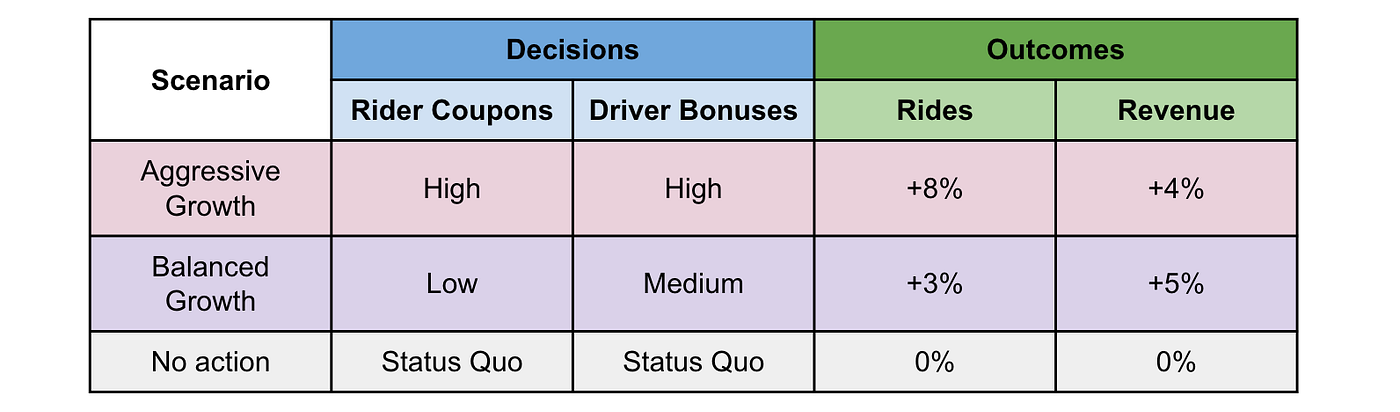
다양한 시나리오를 모델링할 수 있는 능력은 그 자체로 매우 유용합니다. 실제로 Lyft에는 모델과 직접 상호작용할 수 있는 UI가 있어요.
이러한 모델들을 활용하여 특정 목표를 최적화하는 것도 가능합니다. 예를 들어, "수익당 탑승 횟수 제약 조건 내에서 총 탑승 횟수를 최대화"하는 목표를 설정할 수 있죠. 이는 다음과 같은 스칼라 함수로 표현될 수 있습니다.
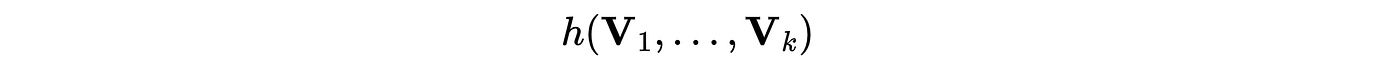
우리의 모델을 통해 이러한 변수들을 예측할 수 있으므로,
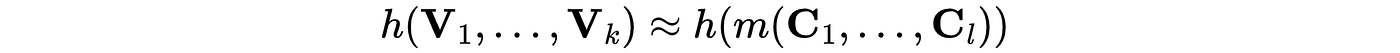
이제 목표는 우리의 정책 변수에 대해 이 함수를 최적화하는 것입니다.
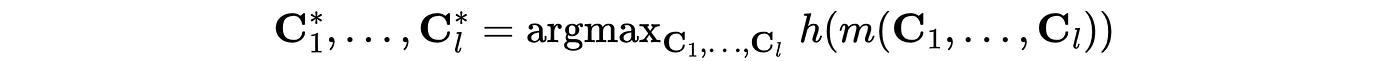
몇 가지 가정과 제약 사항이 있긴 하지만, 이는 다차원 최적화 문제로 해결 가능하며, 다음 글에서 더 자세히 다룰 예정입니다.
7. 결론 및 다음 단계 🚀
Lyft는 효율적이고 확장 가능한 의사 결정을 위해, 예측력과 인과적 타당성을 모두 갖춘 대규모 인과 모델을 개발했습니다. 이 모델은 작은 모델들의 집합으로 이루어져 있으며, 각 제품 팀이 자신들의 지표에 집중하면서도 전체 시장에 대한 Lyft의 합의된 이해를 반영할 수 있게 해줍니다. 궁극적으로 이 시스템은 의사 결정자들이 정보에 기반한 결정을 내리고, 나아가 의사 결정을 최적화하는 데 활용될 수 있도록 설계되었어요.
다음 글에서는 이 시스템을 실제 구현하고 확장하는 과정에서 발생했던 중요한 문제들에 대한 해결책을 다룰 예정입니다. 구체적으로는 다음과 같은 질문들에 답할 거예요.
- 모델을 빠르고 유연하게 선언하는 방법은 무엇일까요?
- 독립적인 모델링과 이들의 원활한 통합을 가능하게 하는 소프트웨어는 무엇일까요?
- 다차원 계획을 포함한 계획들을 어떻게 최적화할까요?
Lyft 데이터 과학 분야의 커리어에 관심이 있다면, Lyft 채용 페이지를 확인해보세요! 🌟